|
MyCaffe
1.12.2.41
Deep learning software for Windows C# programmers.
|
|
MyCaffe
1.12.2.41
Deep learning software for Windows C# programmers.
|
The CudaDnn object is the main interface to the Low-Level Cuda C++ DLL. More...
Public Member Functions | |
| CudaDnn (int nDeviceID, DEVINIT flags=(DEVINIT.CUBLAS|DEVINIT.CURAND), long? lSeed=null, string strPath="", bool bResetFirst=false, bool bEnableMemoryTrace=false) | |
| The CudaDnn constructor. More... | |
| CudaDnn (CudaDnn< T > cuda, bool bEnableGhostMemory) | |
| Alternate CudaDnn constructor. More... | |
| void | Dispose () |
| Disposes this instance freeing up all of its host and GPU memory. More... | |
| void | DisableGhostMemory () |
| Disables the ghost memory, if enabled. More... | |
| void | ResetGhostMemory () |
| Resets the ghost memory by enabling it if this instance was configured to use ghost memory. More... | |
| void | KernelCopy (int nCount, long hSrc, int nSrcOffset, long hDstKernel, long hDst, int nDstOffset, long hHostBuffer, long hHostKernel=-1, long hStream=-1, long hSrcKernel=-1) |
| Copy memory from the look-up tables in one kernel to another. More... | |
| void | KernelAdd (int nCount, long hA, long hDstKernel, long hB, long hC) |
| Add memory from one kernel to memory residing on another kernel. More... | |
| long | KernelCopyNccl (long hSrcKernel, long hSrcNccl) |
| Copies an Nccl handle from one kernel to the current kernel of the current CudaDnn instance. More... | |
| void | SetDeviceID (int nDeviceID=-1, DEVINIT flags=DEVINIT.NONE, long? lSeed=null) |
| Set the device ID used by the current instance of CudaDnn. More... | |
| void | SetRandomSeed (long lSeed) |
| Set the random number generator seed. More... | |
| int | GetDeviceID () |
| Returns the current device id set within Cuda. More... | |
| string | GetDeviceName (int nDeviceID) |
| Query the name of a device. More... | |
| string | GetDeviceP2PInfo (int nDeviceID) |
| Query the peer-to-peer information of a device. More... | |
| string | GetDeviceInfo (int nDeviceID, bool bVerbose=false) |
| Query the device information of a device. More... | |
| void | ResetDevice () |
| Reset the current device. More... | |
| void | SynchronizeDevice () |
| Synchronize the operations on the current device. More... | |
| int | GetMultiGpuBoardGroupID (int nDeviceID) |
| Query the mutli-gpu board group id for a device. More... | |
| int | GetDeviceCount () |
| Query the number of devices (gpu's) installed. More... | |
| bool | CheckMemoryAttributes (long hSrc, int nSrcDeviceID, long hDst, int nDstDeviceID) |
| Check the memory attributes of two memory blocks on different devices to see if they are compatible for peer-to-peer memory transfers. More... | |
| double | GetDeviceMemory (out double dfFree, out double dfUsed, out bool bCudaCallUsed, int nDeviceID=-1) |
| Queries the amount of total, free and used memory on a given GPU. More... | |
| string | GetRequiredCompute (out int nMinMajor, out int nMinMinor) |
| The GetRequiredCompute function returns the Major and Minor compute values required by the current CudaDNN DLL used. More... | |
| bool | DeviceCanAccessPeer (int nSrcDeviceID, int nPeerDeviceID) |
| Query whether or not two devices can access each other via peer-to-peer memory copies. More... | |
| void | DeviceEnablePeerAccess (int nPeerDeviceID) |
| Enables peer-to-peer access between the current device used by the CudaDnn instance and a peer device. More... | |
| void | DeviceDisablePeerAccess (int nPeerDeviceID) |
| Disables peer-to-peer access between the current device used by the CudaDnn instance and a peer device. More... | |
| long | AllocMemory (List< double > rg) |
| Allocate a block of GPU memory and copy a list of doubles to it. More... | |
| long | AllocMemory (List< float > rg) |
| Allocate a block of GPU memory and copy a list of floats to it. More... | |
| long | AllocMemory (double[] rgSrc, long hStream=0) |
| Allocate a block of GPU memory and copy an array of doubles to it, optionally using a stream for the copy. More... | |
| long | AllocMemory (float[] rgSrc, long hStream=0) |
| Allocate a block of GPU memory and copy an array of float to it, optionally using a stream for the copy. More... | |
| long | AllocMemory (T[] rgSrc, long hStream=0, bool bHalfSize=false) |
| Allocate a block of GPU memory and copy an array of type 'T' to it, optionally using a stream for the copy. More... | |
| long | AllocMemory (long lCapacity, bool bHalfSize=false) |
| Allocate a block of GPU memory with a specified capacity. More... | |
| void | FreeMemory (long hMem) |
| Free previously allocated GPU memory. More... | |
| void | CopyDeviceToHost (long lCount, long hGpuSrc, long hHostDst) |
| Copy from GPU memory to Host memory. More... | |
| void | CopyHostToDevice (long lCount, long hHostSrc, long hGpuDst) |
| Copy from Host memory to GPU memory. More... | |
| long | AllocHostBuffer (long lCapacity) |
| Allocate a block of host memory with a specified capacity. More... | |
| void | FreeHostBuffer (long hMem) |
| Free previously allocated host memory. More... | |
| long | GetHostBufferCapacity (long hMem) |
| Returns the host memory capacity. More... | |
| double[] | GetHostMemoryDouble (long hMem) |
| Retrieves the host memory as an array of doubles. More... | |
| float[] | GetHostMemoryFloat (long hMem) |
| Retrieves the host memory as an array of floats. More... | |
| T[] | GetHostMemory (long hMem) |
| Retrieves the host memory as an array of type 'T' More... | |
| double[] | GetMemoryDouble (long hMem, long lCount=-1) |
| Retrieves the GPU memory as an array of doubles. More... | |
| float[] | GetMemoryFloat (long hMem, long lCount=-1) |
| Retrieves the GPU memory as an array of float. More... | |
| T[] | GetMemory (long hMem, long lCount=-1) |
| Retrieves the GPU memory as an array of type 'T' More... | |
| void | SetMemory (long hMem, List< double > rg) |
| Copies a list of doubles into a block of already allocated GPU memory. More... | |
| void | SetMemory (long hMem, List< float > rg) |
| Copies a list of float into a block of already allocated GPU memory. More... | |
| void | SetMemory (long hMem, double[] rgSrc, long hStream=0) |
| Copies an array of double into a block of already allocated GPU memory. More... | |
| void | SetMemory (long hMem, float[] rgSrc, long hStream=0) |
| Copies an array of float into a block of already allocated GPU memory. More... | |
| void | SetMemory (long hMem, T[] rgSrc, long hStream=0, int nCount=-1) |
| Copies an array of type 'T' into a block of already allocated GPU memory. More... | |
| void | SetMemoryAt (long hMem, double[] rgSrc, int nOffset) |
| Copies an array of double into a block of already allocated GPU memory starting at a specific offset. More... | |
| void | SetMemoryAt (long hMem, float[] rgSrc, int nOffset) |
| Copies an array of float into a block of already allocated GPU memory starting at a specific offset. More... | |
| void | SetMemoryAt (long hMem, T[] rgSrc, int nOffset) |
| Copies an array of type 'T' into a block of already allocated GPU memory starting at a specific offset. More... | |
| T[] | SetPixel (long hMem, int nCount, bool bReturnOriginal, int nOffset, params Tuple< int, T >[] rgPixel) |
| Set a pixel value where each pixel is defined a set index, value tuple. More... | |
| void | SetHostMemory (long hMem, T[] rgSrc) |
| Copies an array of type 'T' into a block of already allocated host memory. More... | |
| long | CreateMemoryPointer (long hData, long lOffset, long lCount) |
| Creates a memory pointer into an already existing block of GPU memory. More... | |
| void | FreeMemoryPointer (long hData) |
| Frees a memory pointer. More... | |
| long | CreateMemoryTest (out ulong ulTotalNumBlocks, out double dfMemAllocatedInGB, out ulong ulMemStartAddr, out ulong ulBlockSize, double dfPctToAllocate=1.0) |
| Creates a new memory test on the current GPU. More... | |
| void | FreeMemoryTest (long h) |
| Free a memory test, freeing up all GPU memory used. More... | |
| T[] | RunMemoryTest (long h, MEMTEST_TYPE type, ulong ulBlockStartOffset, ulong ulBlockCount, bool bVerbose, bool bWrite, bool bReadWrite, bool bRead) |
| The RunMemoryTest method runs the memory test from the block start offset through the block count on the memory previously allocated using CreateMemoryTest. More... | |
| long | CreateImageOp (int nNum, double dfBrightnessProb, double dfBrightnessDelta, double dfContrastProb, double dfContrastLower, double dfContrastUpper, double dfSaturationProb, double dfSaturationLower, double dfSaturationUpper, long lRandomSeed=0) |
| Create a new ImageOp used to perform image operations on the GPU. More... | |
| void | FreeImageOp (long h) |
| Free an image op, freeing up all GPU memory used. More... | |
| void | DistortImage (long h, int nCount, int nNum, int nDim, long hX, long hY) |
| Distort an image using the ImageOp handle provided. More... | |
| long | CreateStream (bool bNonBlocking=false, int nIndex=-1) |
| Create a new stream on the current GPU. More... | |
| void | FreeStream (long h) |
| Free a stream. More... | |
| void | SynchronizeStream (long h=0) |
| Synchronize a stream on the current GPU, waiting for its operations to complete. More... | |
| void | SynchronizeThread () |
| Synchronize all kernel threads on the current GPU. More... | |
| long | CreateCuDNN (long hStream=0) |
| Create a new instance of NVIDIA's cuDnn. More... | |
| void | FreeCuDNN (long h) |
| Free an instance of cuDnn. More... | |
| long | CreateNCCL (int nDeviceId, int nCount, int nRank, Guid guid) |
| Create an instance of NVIDIA's NCCL 'Nickel' More... | |
| void | FreeNCCL (long hNccl) |
| Free an instance of NCCL. More... | |
| void | NcclInitializeSingleProcess (params long[] rghNccl) |
| Initializes a set of NCCL instances for use in a single process. More... | |
| void | NcclInitializeMultiProcess (long hNccl) |
| Initializes a set of NCCL instances for use in different processes. More... | |
| void | NcclBroadcast (long hNccl, long hStream, long hX, int nCount) |
| Broadcasts a block of GPU data to all NCCL instances. More... | |
| void | NcclAllReduce (long hNccl, long hStream, long hX, int nCount, NCCL_REDUCTION_OP op, double dfScale=1.0) |
| Performs a reduction on all NCCL instances as specified by the reduction operation. More... | |
| long | CreateExtension (string strExtensionDllPath) |
| Create an instance of an Extension DLL. More... | |
| void | FreeExtension (long hExtension) |
| Free an instance of an Extension. More... | |
| T[] | RunExtension (long hExtension, long lfnIdx, T[] rgParam) |
| Run a function on the extension specified. More... | |
| long | CreateTensorDesc () |
| Create a new instance of a tensor descriptor for use with NVIDIA's cuDnn. More... | |
| void | FreeTensorDesc (long h) |
| Free a tensor descriptor instance. More... | |
| void | SetTensorNdDesc (long hHandle, int[] rgDim, int[] rgStride, bool bHalf=false) |
| Sets the values of a tensor descriptor. More... | |
| void | SetTensorDesc (long hHandle, int n, int c, int h, int w, bool bHalf=false) |
| Sets the values of a tensor descriptor. More... | |
| void | SetTensorDesc (long hHandle, int n, int c, int h, int w, int nStride, int cStride, int hStride, int wStride, bool bHalf=false) |
| Sets the values of a tensor descriptor. More... | |
| void | AddTensor (long hCuDnn, long hSrcDesc, long hSrc, int nSrcOffset, long hDstDesc, long hDst, int nDstOffset) |
| Add two tensors together. More... | |
| void | AddTensor (long hCuDnn, T fAlpha, long hSrcDesc, long hSrc, int nSrcOffset, T fBeta, long hDstDesc, long hDst, int nDstOffset) |
| Add two tensors together. More... | |
| long | CreateFilterDesc () |
| Create a new instance of a filter descriptor for use with NVIDIA's cuDnn. More... | |
| void | FreeFilterDesc (long h) |
| Free a filter descriptor instance. More... | |
| void | SetFilterNdDesc (long hHandle, int[] rgDim, bool bHalf=false) |
| Sets the values of a filter descriptor. More... | |
| void | SetFilterDesc (long hHandle, int n, int c, int h, int w, bool bHalf=false) |
| Sets the values of a filter descriptor. More... | |
| long | CreateConvolutionDesc () |
| Create a new instance of a convolution descriptor for use with NVIDIA's cuDnn. More... | |
| void | FreeConvolutionDesc (long h) |
| Free a convolution descriptor instance. More... | |
| void | SetConvolutionDesc (long hHandle, int hPad, int wPad, int hStride, int wStride, int hDilation, int wDilation, bool bUseTensorCores, bool bHalf=false) |
| Set the values of a convolution descriptor. More... | |
| void | GetConvolutionInfo (long hCuDnn, long hBottomDesc, long hFilterDesc, long hConvDesc, long hTopDesc, ulong lWorkspaceSizeLimitInBytes, bool bUseTensorCores, out CONV_FWD_ALGO algoFwd, out ulong lWsSizeFwd, out CONV_BWD_FILTER_ALGO algoBwdFilter, out ulong lWsSizeBwdFilter, out CONV_BWD_DATA_ALGO algoBwdData, out ulong lWsSizeBwdData, CONV_FWD_ALGO preferredFwdAlgo=CONV_FWD_ALGO.NONE) |
| Queryies the algorithms and workspace sizes used for a given convolution descriptor. More... | |
| void | ConvolutionForward (long hCuDnn, long hBottomDesc, long hBottomData, int nBottomOffset, long hFilterDesc, long hWeight, int nWeightOffset, long hConvDesc, CONV_FWD_ALGO algoFwd, long hWorkspace, int nWorkspaceOffset, ulong lWorkspaceSize, long hTopDesc, long hTopData, int nTopOffset, bool bSyncStream=true) |
| Perform a convolution forward pass. More... | |
| void | ConvolutionForward (long hCuDnn, T fAlpha, long hBottomDesc, long hBottomData, int nBottomOffset, long hFilterDesc, long hWeight, int nWeightOffset, long hConvDesc, CONV_FWD_ALGO algoFwd, long hWorkspace, int nWorkspaceOffset, ulong lWorkspaceSize, T fBeta, long hTopDesc, long hTopData, int nTopOffset, bool bSyncStream=true) |
| Perform a convolution forward pass. More... | |
| void | ConvolutionBackwardBias (long hCuDnn, long hTopDesc, long hTopDiff, int nTopOffset, long hBiasDesc, long hBiasDiff, int nBiasOffset, bool bSyncStream=true) |
| Perform a convolution backward pass on the bias. More... | |
| void | ConvolutionBackwardBias (long hCuDnn, T fAlpha, long hTopDesc, long hTopDiff, int nTopOffset, T fBeta, long hBiasDesc, long hBiasDiff, int nBiasOffset, bool bSyncStream=true) |
| Perform a convolution backward pass on the bias. More... | |
| void | ConvolutionBackwardFilter (long hCuDnn, long hBottomDesc, long hBottomData, int nBottomOffset, long hTopDesc, long hTopDiff, int nTopOffset, long hConvDesc, CONV_BWD_FILTER_ALGO algoBwd, long hWorkspace, int nWorkspaceOffset, ulong lWorkspaceSize, long hFilterDesc, long hWeightDiff, int nWeightOffset, bool bSyncStream) |
| Perform a convolution backward pass on the filter. More... | |
| void | ConvolutionBackwardFilter (long hCuDnn, T fAlpha, long hBottomDesc, long hBottomData, int nBottomOffset, long hTopDesc, long hTopDiff, int nTopOffset, long hConvDesc, CONV_BWD_FILTER_ALGO algoBwd, long hWorkspace, int nWorkspaceOffset, ulong lWorkspaceSize, T fBeta, long hFilterDesc, long hWeightDiff, int nWeightOffset, bool bSyncStream=true) |
| Perform a convolution backward pass on the filter. More... | |
| void | ConvolutionBackwardData (long hCuDnn, long hFilterDesc, long hWeight, int nWeightOffset, long hTopDesc, long hTopDiff, int nTopOffset, long hConvDesc, CONV_BWD_DATA_ALGO algoBwd, long hWorkspace, int nWorkspaceOffset, ulong lWorkspaceSize, long hBottomDesc, long hBottomDiff, int nBottomOffset, bool bSyncStream=true) |
| Perform a convolution backward pass on the data. More... | |
| void | ConvolutionBackwardData (long hCuDnn, T fAlpha, long hFilterDesc, long hWeight, int nWeightOffset, long hTopDesc, long hTopDiff, int nTopOffset, long hConvDesc, CONV_BWD_DATA_ALGO algoBwd, long hWorkspace, int nWorkspaceOffset, ulong lWorkspaceSize, T fBeta, long hBottomDesc, long hBottomDiff, int nBottomOffset, bool bSyncStream=true) |
| Perform a convolution backward pass on the data. More... | |
| long | CreatePoolingDesc () |
| Create a new instance of a pooling descriptor for use with NVIDIA's cuDnn. More... | |
| void | FreePoolingDesc (long h) |
| Free a pooling descriptor instance. More... | |
| void | SetPoolingDesc (long hHandle, PoolingMethod method, int h, int w, int hPad, int wPad, int hStride, int wStride) |
| Set the values of a pooling descriptor. More... | |
| void | PoolingForward (long hCuDnn, long hPoolingDesc, T fAlpha, long hBottomDesc, long hBottomData, T fBeta, long hTopDesc, long hTopData) |
| Perform a pooling forward pass. More... | |
| void | PoolingBackward (long hCuDnn, long hPoolingDesc, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, long hBottomDataDesc, long hBottomData, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform a pooling backward pass. More... | |
| void | DeriveBatchNormDesc (long hFwdScaleBiasMeanVarDesc, long hFwdBottomDesc, long hBwdScaleBiasMeanVarDesc, long hBwdBottomDesc, BATCHNORM_MODE mode) |
| Derive the batch norm descriptors for both the forward and backward passes. More... | |
| void | BatchNormForward (long hCuDnn, BATCHNORM_MODE mode, T fAlpha, T fBeta, long hFwdBottomDesc, long hBottomData, long hFwdTopDesc, long hTopData, long hFwdScaleBiasMeanVarDesc, long hScaleData, long hBiasData, double dfFactor, long hGlobalMean, long hGlobalVar, double dfEps, long hSaveMean, long hSaveInvVar, bool bTraining) |
| Run the batch norm forward pass. More... | |
| void | BatchNormBackward (long hCuDnn, BATCHNORM_MODE mode, T fAlphaDiff, T fBetaDiff, T fAlphaParamDiff, T fBetaParamDiff, long hBwdBottomDesc, long hBottomData, long hTopDiffDesc, long hTopDiff, long hBottomDiffDesc, long hBottomDiff, long hBwdScaleBiasMeanVarDesc, long hScaleData, long hScaleDiff, long hBiasDiff, double dfEps, long hSaveMean, long hSaveInvVar) |
| Run the batch norm backward pass. More... | |
| long | CreateDropoutDesc () |
| Create a new instance of a dropout descriptor for use with NVIDIA's cuDnn. More... | |
| void | FreeDropoutDesc (long h) |
| Free a dropout descriptor instance. More... | |
| void | SetDropoutDesc (long hCuDnn, long hDropoutDesc, double dfDropout, long hStates, long lSeed) |
| Set the dropout descriptor values. More... | |
| void | GetDropoutInfo (long hCuDnn, long hBottomDesc, out ulong ulStateCount, out ulong ulReservedCount) |
| Query the dropout state and reserved counts. More... | |
| void | DropoutForward (long hCuDnn, long hDropoutDesc, long hBottomDesc, long hBottomData, long hTopDesc, long hTopData, long hReserved) |
| Performs a dropout forward pass. More... | |
| void | DropoutBackward (long hCuDnn, long hDropoutDesc, long hTopDesc, long hTop, long hBottomDesc, long hBottom, long hReserved) |
| Performs a dropout backward pass. More... | |
| long | CreateLRNDesc () |
| Create a new instance of a LRN descriptor for use with NVIDIA's cuDnn. More... | |
| void | FreeLRNDesc (long h) |
| Free a LRN descriptor instance. More... | |
| void | SetLRNDesc (long hHandle, uint nSize, double fAlpha, double fBeta, double fK) |
| Set the LRN descriptor values. More... | |
| void | LRNCrossChannelForward (long hCuDnn, long hNormDesc, T fAlpha, long hBottomDesc, long hBottomData, T fBeta, long hTopDesc, long hTopData) |
| Perform LRN cross channel forward pass. More... | |
| void | LRNCrossChannelBackward (long hCuDnn, long hNormDesc, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, long hBottomDataDesc, long hBottomData, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform LRN cross channel backward pass. More... | |
| void | DivisiveNormalizationForward (long hCuDnn, long hNormDesc, T fAlpha, long hBottomDataDesc, long hBottomData, long hTemp1, long hTemp2, T fBeta, long hTopDataDesc, long hTopData) |
| Performs a Devisive Normalization forward pass. More... | |
| void | DivisiveNormalizationBackward (long hCuDnn, long hNormDesc, T fAlpha, long hBottomDataDesc, long hBottomData, long hTopDiff, long hTemp1, long hTemp2, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Performs a Devisive Normalization backward pass. More... | |
| void | TanhForward (long hCuDnn, T fAlpha, long hBottomDataDesc, long hBottomData, T fBeta, long hTopDataDesc, long hTopData) |
| Perform a Tanh forward pass. More... | |
| void | TanhBackward (long hCuDnn, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, long hBottomDataDesc, long hBottomData, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform a Tanh backward pass. More... | |
| void | EluForward (long hCuDnn, T fAlpha, long hBottomDataDesc, long hBottomData, T fBeta, long hTopDataDesc, long hTopData) |
| Perform a Elu forward pass. More... | |
| void | EluBackward (long hCuDnn, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, long hBottomDataDesc, long hBottomData, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform a Elu backward pass. More... | |
| void | SigmoidForward (long hCuDnn, T fAlpha, long hBottomDataDesc, long hBottomData, T fBeta, long hTopDataDesc, long hTopData) |
| Perform a Sigmoid forward pass. More... | |
| void | SigmoidBackward (long hCuDnn, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, long hBottomDataDesc, long hBottomData, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform a Sigmoid backward pass. More... | |
| void | ReLUForward (long hCuDnn, T fAlpha, long hBottomDataDesc, long hBottomData, T fBeta, long hTopDataDesc, long hTopData) |
| Perform a ReLU forward pass. More... | |
| void | ReLUBackward (long hCuDnn, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, long hBottomDataDesc, long hBottomData, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform a ReLU backward pass. More... | |
| void | SoftmaxForward (long hCuDnn, SOFTMAX_ALGORITHM alg, SOFTMAX_MODE mode, T fAlpha, long hBottomDataDesc, long hBottomData, T fBeta, long hTopDataDesc, long hTopData) |
| Perform a Softmax forward pass. More... | |
| void | SoftmaxBackward (long hCuDnn, SOFTMAX_ALGORITHM alg, SOFTMAX_MODE mode, T fAlpha, long hTopDataDesc, long hTopData, long hTopDiffDesc, long hTopDiff, T fBeta, long hBottomDiffDesc, long hBottomDiff) |
| Perform a Softmax backward pass. More... | |
| long | CreateRnnDataDesc () |
| Create the RNN Data Descriptor. More... | |
| void | FreeRnnDataDesc (long h) |
| Free an existing RNN Data descriptor. More... | |
| void | SetRnnDataDesc (long hRnnDataDesc, RNN_DATALAYOUT layout, int nMaxSeqLen, int nBatchSize, int nVectorSize, bool bBidirectional=false, int[] rgSeqLen=null) |
| Sets the RNN Data Descriptor values. More... | |
| long | CreateRnnDesc () |
| Create the RNN Descriptor. More... | |
| void | FreeRnnDesc (long h) |
| Free an existing RNN descriptor. More... | |
| void | SetRnnDesc (long hCuDnn, long hRnnDesc, int nHiddenCount, int nNumLayers, long hDropoutDesc, RNN_MODE mode, bool bUseTensorCores, RNN_DIRECTION direction=RNN_DIRECTION.RNN_UNIDIRECTIONAL) |
| Sets the RNN Descriptor values. More... | |
| int | GetRnnParamCount (long hCuDnn, long hRnnDesc, long hXDesc) |
| Returns the RNN parameter count. More... | |
| ulong | GetRnnWorkspaceCount (long hCuDnn, long hRnnDesc, long hXDesc, out ulong nReservedCount) |
| Returns the workspace and reserved counts. More... | |
| void | GetRnnLinLayerParams (long hCuDnn, long hRnnDesc, int nLayer, long hXDesc, long hWtDesc, long hWtData, int nLinLayer, out int nWtCount, out long hWt, out int nBiasCount, out long hBias) |
| Returns the linear layer parameters (weights). More... | |
| void | RnnForward (long hCuDnn, long hRnnDesc, long hXDesc, long hXData, long hHxDesc, long hHxData, long hCxDesc, long hCxData, long hWtDesc, long hWtData, long hYDesc, long hYData, long hHyDesc, long hHyData, long hCyDesc, long hCyData, long hWorkspace, ulong nWsCount, long hReserved, ulong nResCount, bool bTraining) |
| Run the RNN through a forward pass. More... | |
| void | RnnBackwardData (long hCuDnn, long hRnnDesc, long hYDesc, long hYData, long hYDiff, long hHyDesc, long hHyDiff, long hCyDesc, long hCyDiff, long hWtDesc, long hWtData, long hHxDesc, long hHxData, long hCxDesc, long hCxData, long hXDesc, long hXDiff, long hdHxDesc, long hHxDiff, long hdCxDesc, long hCxDiff, long hWorkspace, ulong nWsCount, long hReserved, ulong nResCount) |
| Run the RNN backward pass through the data. More... | |
| void | RnnBackwardWeights (long hCuDnn, long hRnnDesc, long hXDesc, long hXData, long hHxDesc, long hHxData, long hYDesc, long hYData, long hWorkspace, ulong nWsCount, long hWtDesc, long hWtDiff, long hReserved, ulong nResCount) |
| Run the RNN backward pass on the weights. More... | |
| bool | IsRnn8Supported () |
| Returns whether or not RNN8 is supported. More... | |
| long | CreateRnn8 () |
| Create the RNN8. More... | |
| void | FreeRnn8 (long h) |
| Free an existing RNN8. More... | |
| void | SetRnn8 (long hCuDnn, long hRnn, bool bTraining, RNN_DATALAYOUT layout, RNN_MODE cellMode, RNN_BIAS_MODE biasMode, int nSequenceLen, int nBatchSize, int nInputs, int nHidden, int nOutputs, int nProjection, int nNumLayers, float fDropout, ulong lSeed, bool bBidirectional=false) |
| Set the RNN8 parameters. More... | |
| void | GetRnn8MemorySizes (long hCuDnn, long hRnn, out ulong szWtCount, out ulong szWorkSize, out ulong szReservedSize) |
| Returns the memory sizes required for the RNN8. More... | |
| void | InitializeRnn8Weights (long hCuDnn, long hRnn, long hWt, RNN_FILLER_TYPE wtFt, double fWtVal, double fWtVal2, RNN_FILLER_TYPE biasFt, double fBiasVal, double fBiasVal2) |
| Initialize the RNN8 weights More... | |
| void | Rnn8Forward (long hCuDnn, long hRnn, long hX, long hY, long hhX, long hhY, long hcX, long hcY, long hWts, long hWork, long hReserved) |
| Calculate the forward pass through the RNN8. More... | |
| void | Rnn8Backward (long hCuDnn, long hRnn, long hY, long hdY, long hX, long hdX, long hhX, long hdhY, long hdhX, long hcX, long hdcY, long hdcX, long hWt, long hdWt, long hWork, long hReserved) |
| Calculate the backward pass through the RNN8 for both data and weights. More... | |
| long | AllocPCAData (int nM, int nN, int nK, out int nCount) |
| Allocates the GPU memory for the PCA Data. More... | |
| long | AllocPCAScores (int nM, int nN, int nK, out int nCount) |
| Allocates the GPU memory for the PCA scores. More... | |
| long | AllocPCALoads (int nM, int nN, int nK, out int nCount) |
| Allocates the GPU memory for the PCA loads. More... | |
| long | AllocPCAEigenvalues (int nM, int nN, int nK, out int nCount) |
| Allocates the GPU memory for the PCA eigenvalues. More... | |
| long | CreatePCA (int nMaxIterations, int nM, int nN, int nK, long hData, long hScoresResult, long hLoadsResult, long hResiduals=0, long hEigenvalues=0) |
| Creates a new PCA instance and returns the handle to it. More... | |
| bool | RunPCA (long hPCA, int nSteps, out int nCurrentK, out int nCurrentIteration) |
| Runs a number of steps of the iterative PCA algorithm. More... | |
| void | FreePCA (long hPCA) |
| Free the PCA instance associated with handle. More... | |
| long | CreateSSD (int nNumClasses, bool bShareLocation, int nLocClasses, int nBackgroundLabelId, bool bUseDiffcultGt, SSD_MINING_TYPE miningType, SSD_MATCH_TYPE matchType, float fOverlapThreshold, bool bUsePriorForMatching, SSD_CODE_TYPE codeType, bool bEncodeVariantInTgt, bool bBpInside, bool bIgnoreCrossBoundaryBbox, bool bUsePriorForNms, SSD_CONF_LOSS_TYPE confLossType, SSD_LOC_LOSS_TYPE locLossType, float fNegPosRatio, float fNegOverlap, int nSampleSize, bool bMapObjectToAgnostic, bool bNmsParam, float? fNmsThreshold=null, int? nNmsTopK=null, float? fNmsEta=null) |
| Create an instance of the SSD GPU support. More... | |
| void | SetupSSD (long hSSD, int nNum, int nNumPriors, int nNumGt) |
| Setup the SSD GPU support. More... | |
| void | FreeSSD (long hSSD) |
| Free the instance of SSD GPU support. More... | |
| int | SsdMultiBoxLossForward (long hSSD, int nLocDataCount, long hLocGpuData, int nConfDataCount, long hConfGpuData, int nPriorDataCount, long hPriorGpuData, int nGtDataCount, long hGtGpuData, out List< DictionaryMap< List< int > > > rgAllMatchIndices, out List< List< int > > rgrgAllNegIndices, out int nNumNegs) |
| Performs the SSD MultiBoxLoss forward operation. More... | |
| void | SsdEncodeLocPrediction (long hSSD, int nLocPredCount, long hLocPred, int nLocGtCount, long hLocGt) |
| Encodes the SSD data into the location prediction and location ground truths. More... | |
| void | SsdEncodeConfPrediction (long hSSD, int nConfPredCount, long hConfPred, int nConfGtCount, long hConfGt) |
| Encodes the SSD data into the confidence prediction and confidence ground truths. More... | |
| long | CreateLayerNorm (int nGpuID, int nCount, int nOuterNum, int nChannels, int nInnerNum, float fEps=1e-10f) |
| Create the Cuda version of LayerNorm More... | |
| void | FreeLayerNorm (long hLayerNorm) |
| Free the instance of LayerNorm GPU support. More... | |
| void | LayerNormForward (long hLayerNorm, long hXdata, long hYdata) |
| Run the LayerNorm forward pass. More... | |
| void | LayerNormBackward (long hLayerNorm, long hYdata, long hYdiff, long hXdiff) |
| Run the LayerNorm backward pass. More... | |
| void | set (int nCount, long hHandle, double fVal, int nIdx=-1) |
| Set the values of GPU memory to a specified value of type More... | |
| void | set (int nCount, long hHandle, float fVal, int nIdx=-1) |
| Set the values of GPU memory to a specified value of type More... | |
| void | set (int nCount, long hHandle, T fVal, int nIdx=-1, int nXOff=0) |
| Set the values of GPU memory to a specified value of type 'T'. More... | |
| double[] | get_double (int nCount, long hHandle, int nIdx=-1) |
| Queries the GPU memory by copying it into an array of More... | |
| float[] | get_float (int nCount, long hHandle, int nIdx=-1) |
| Queries the GPU memory by copying it into an array of More... | |
| T[] | get (int nCount, long hHandle, int nIdx=-1) |
| Queries the GPU memory by copying it into an array of type 'T'. More... | |
| void | copy (int nCount, long hSrc, long hDst, int nSrcOffset=0, int nDstOffset=0, long hStream=-1, bool? bSrcHalfSizeOverride=null, bool? bDstHalfSizeOverride=null) |
| Copy data from one block of GPU memory to another. More... | |
| void | copy (int nCount, int nNum, int nDim, long hSrc1, long hSrc2, long hDst, long hSimilar, bool bInvert=false) |
| Copy similar items of length 'nDim' from hSrc1 (where hSimilar(i) = 1) and dissimilar items of length 'nDim' from hSrc2 (where hSimilar(i) = 0). More... | |
| void | copy_batch (int nCount, int nNum, int nDim, long hSrcData, long hSrcLbl, int nDstCount, long hDstCache, long hWorkDevData, int nLabelStart, int nLabelCount, int nCacheSize, long hCacheHostCursors, long hWorkDataHost) |
| Copy a batch of labeled items into a cache organized by label where older data is removed and replaced by newer data. More... | |
| void | copy_sequence (int nK, int nNum, int nDim, long hSrcData, long hSrcLbl, int nSrcCacheCount, long hSrcCache, int nLabelStart, int nLabelCount, int nCacheSize, long hCacheHostCursors, bool bOutputLabels, List< long > rghTop, List< int > rgnTopCount, long hWorkDataHost, bool bCombinePositiveAndNegative=false, int nSeed=0) |
| Copy a sequence of cached items, organized by label, into an anchor, positive (if nK > 0), and negative blobs. More... | |
| void | copy_sequence (int n, long hSrc, int nSrcStep, int nSrcStartIdx, int nCopyCount, int nCopyDim, long hDst, int nDstStep, int nDstStartIdx, int nSrcSpatialDim, int nDstSpatialDim, int nSrcSpatialDimStartIdx=0, int nDstSpatialDimStartIdx=0, int nSpatialDimCount=-1) |
| Copy a sequence from a source to a destination and allow for skip steps. More... | |
| void | copy_expand (int n, int nNum, int nDim, long hX, long hA) |
| Expand a vector of length 'nNum' into a matrix of size 'nNum' x 'nDim' by copying each value of the vector into all elements of the corresponding matrix row. More... | |
| void | fill (int n, int nDim, long hSrc, int nSrcOff, int nCount, long hDst) |
| Fill data from the source data 'n' times in the destination. More... | |
| void | sort (int nCount, long hY) |
| Sort the data in the GPU memory specified. More... | |
| void | gemm (bool bTransA, bool bTransB, int m, int n, int k, double fAlpha, long hA, long hB, double fBeta, long hC) |
| Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C More... | |
| void | gemm (bool bTransA, bool bTransB, int m, int n, int k, float fAlpha, long hA, long hB, float fBeta, long hC) |
| Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C More... | |
| void | gemm (bool bTransA, bool bTransB, int m, int n, int k, T fAlpha, long hA, long hB, T fBeta, long hC, int nAOffset=0, int nBOffset=0, int nCOffset=0, int nGroups=1, int nGroupOffsetA=0, int nGroupOffsetB=0, int nGroupOffsetC=0) |
| Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C More... | |
| void | gemm (bool bTransA, bool bTransB, int m, int n, int k, double fAlpha, long hA, long hB, double fBeta, long hC, uint lda, uint ldb, uint ldc) |
| Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C More... | |
| void | gemm (bool bTransA, bool bTransB, int m, int n, int k, double fAlpha, long hA, long hB, double fBeta, long hC, uint lda, uint ldb, uint ldc, uint stridea, uint strideb, uint stridec, uint batch_count) |
| Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C More... | |
| void | geam (bool bTransA, bool bTransB, int m, int n, double fAlpha, long hA, long hB, double fBeta, long hC) |
| Perform a matrix-matrix addition/transposition operation: C = alpha transA (A) + beta transB (B) More... | |
| void | geam (bool bTransA, bool bTransB, int m, int n, float fAlpha, long hA, long hB, float fBeta, long hC) |
| Perform a matrix-matrix addition/transposition operation: C = alpha transA (A) + beta transB (B) More... | |
| void | geam (bool bTransA, bool bTransB, int m, int n, T fAlpha, long hA, long hB, T fBeta, long hC, int nAOffset=0, int nBOffset=0, int nCOffset=0) |
| Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C More... | |
| void | gemv (bool bTransA, int m, int n, double fAlpha, long hA, long hX, double fBeta, long hY) |
| Perform a matrix-vector multiplication operation: y = alpha transA (A) x + beta y (where x and y are vectors) More... | |
| void | gemv (bool bTransA, int m, int n, float fAlpha, long hA, long hX, float fBeta, long hY) |
| Perform a matrix-vector multiplication operation: y = alpha transA (A) x + beta y (where x and y are vectors) More... | |
| void | gemv (bool bTransA, int m, int n, T fAlpha, long hA, long hX, T fBeta, long hY, int nAOffset=0, int nXOffset=0, int nYOffset=0) |
| Perform a matrix-vector multiplication operation: y = alpha transA (A) x + beta y (where x and y are vectors) More... | |
| void | ger (int m, int n, double fAlpha, long hX, long hY, long hA) |
| Perform a vector-vector multiplication operation: A = x * (fAlpha * y) (where x and y are vectors and A is an m x n Matrix) More... | |
| void | ger (int m, int n, float fAlpha, long hX, long hY, long hA) |
| Perform a vector-vector multiplication operation: A = x * (fAlpha * y) (where x and y are vectors and A is an m x n Matrix) More... | |
| void | ger (int m, int n, T fAlpha, long hX, long hY, long hA) |
| Perform a vector-vector multiplication operation: A = x * (fAlpha * y) (where x and y are vectors and A is an m x n Matrix) More... | |
| void | axpy (int n, double fAlpha, long hX, long hY) |
| Multiply the vector X by a scalar and add the result to the vector Y. More... | |
| void | axpy (int n, float fAlpha, long hX, long hY) |
| Multiply the vector X by a scalar and add the result to the vector Y. More... | |
| void | axpy (int n, T fAlpha, long hX, long hY, int nXOff=0, int nYOff=0) |
| Multiply the vector X by a scalar and add the result to the vector Y. More... | |
| void | axpby (int n, double fAlpha, long hX, double fBeta, long hY) |
| Scale the vector x and then multiply the vector X by a scalar and add the result to the vector Y. More... | |
| void | axpby (int n, float fAlpha, long hX, float fBeta, long hY) |
| Scale the vector x and then multiply the vector X by a scalar and add the result to the vector Y. More... | |
| void | axpby (int n, T fAlpha, long hX, T fBeta, long hY) |
| Scale the vector x by Alpha and scale vector y by Beta and then add both together. More... | |
| void | mulbsx (int n, long hA, int nAOff, long hX, int nXOff, int nC, int nSpatialDim, bool bTranspose, long hB, int nBOff) |
| Multiply a matrix with a vector. More... | |
| void | divbsx (int n, long hA, int nAOff, long hX, int nXOff, int nC, int nSpatialDim, bool bTranspose, long hB, int nBOff) |
| Divide a matrix by a vector. More... | |
| void | matmul (uint nOuterCount, int m, int n, int k, long hA, long hB, long hC, double dfScale=1.0, bool bTransA=false, bool bTransB=false) |
| Perform matmul operation hC = matmul(hA, hB), where hA, hB and hC are all in row-major format. More... | |
| void | transposeHW (int n, int c, int h, int w, long hSrc, long hDst) |
| Transpose a n*c number of matrices along the height and width dimensions. All matrices are in row-major format. More... | |
| void | set_bounds (int n, double dfMin, double dfMax, long hX) |
| Set the bounds of all items within the data to a set range of values. More... | |
| void | scal (int n, double fAlpha, long hX, int nXOff=0) |
| Scales the data in X by a scaling factor. More... | |
| void | scal (int n, float fAlpha, long hX, int nXOff=0) |
| Scales the data in X by a scaling factor. More... | |
| void | scal (int n, T fAlpha, long hX, int nXOff=0) |
| Scales the data in X by a scaling factor. More... | |
| double | dot_double (int n, long hX, long hY) |
| Computes the dot product of X and Y. More... | |
| float | dot_float (int n, long hX, long hY) |
| Computes the dot product of X and Y. More... | |
| T | dot (int n, long hX, long hY, int nXOff=0, int nYOff=0) |
| Computes the dot product of X and Y. More... | |
| double | asum_double (int n, long hX, int nXOff=0) |
| Computes the sum of absolute values in X. More... | |
| float | asum_float (int n, long hX, int nXOff=0) |
| Computes the sum of absolute values in X. More... | |
| T | asum (int n, long hX, int nXOff=0) |
| Computes the sum of absolute values in X. More... | |
| void | scale (int n, double fAlpha, long hX, long hY) |
| Scales the values in X and places them in Y. More... | |
| void | scale (int n, float fAlpha, long hX, long hY) |
| Scales the values in X and places them in Y. More... | |
| void | scale (int n, T fAlpha, long hX, long hY, int nXOff=0, int nYOff=0) |
| Scales the values in X and places them in Y. More... | |
| void | scale_to_range (int n, long hX, long hY, double fMin, double fMax) |
| Scales the values in X and places the result in Y (can also run inline where X = Y). More... | |
| double | erf (double dfVal) |
| Calculates the erf() function. More... | |
| float | erf (float fVal) |
| Calculates the erf() function. More... | |
| T | erf (T fVal) |
| Calculates the erf() function. More... | |
| void | mask (int n, int nMaskDim, T fSearch, T fReplace, long hX, long hMask, long hY) |
| Mask the mask the data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination. More... | |
| void | mask (int n, int nMaskDim, double fSearch, double fReplace, long hX, long hMask, long hY) |
| Mask the mask the data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination. More... | |
| void | mask (int n, int nMaskDim, float fSearch, float fReplace, long hX, long hMask, long hY) |
| Mask the mask the data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination. More... | |
| void | mask_batch (int n, int nBatch, int nMaskDim, T fSearch, T fReplace, long hX, long hMask, long hY) |
| Mask the mask the batch of data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination. More... | |
| void | mask_batch (int n, int nBatch, int nMaskDim, double fSearch, double fReplace, long hX, long hMask, long hY) |
| Mask the mask the batch of data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination. More... | |
| void | mask_batch (int n, int nBatch, int nMaskDim, float fSearch, float fReplace, long hX, long hMask, long hY) |
| Mask the mask the batch of data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination. More... | |
| void | interp2 (int nChannels, long hData1, int nX1, int nY1, int nHeight1, int nWidth1, int nHeight1A, int nWidth1A, long hData2, int nX2, int nY2, int nHeight2, int nWidth2, int nHeight2A, int nWidth2A, bool bBwd=false) |
| Interpolates between two sizes within the spatial dimensions. More... | |
| void | add_scalar (int n, double fAlpha, long hY) |
| Adds a scalar value to each element of Y. More... | |
| void | add_scalar (int n, float fAlpha, long hY) |
| Adds a scalar value to each element of Y. More... | |
| void | add_scalar (int n, T fAlpha, long hY, int nYOff=0) |
| Adds a scalar value to each element of Y. More... | |
| void | add (int n, long hA, long hB, long hC, long hY) |
| Adds A, B and C and places the result in Y. More... | |
| void | add (int n, long hA, long hB, long hY) |
| Adds A to B and places the result in Y. More... | |
| void | add (int n, long hA, long hB, long hY, double dfAlpha) |
| Adds A to (B times scalar) and places the result in Y. More... | |
| void | add (int n, long hA, long hB, long hY, float fAlpha) |
| Adds A to (B times scalar) and places the result in Y. More... | |
| void | add (int n, long hA, long hB, long hY, double dfAlphaA, double dfAlphaB, int nAOff=0, int nBOff=0, int nYOff=0) |
| Adds A to (B times scalar) and places the result in Y. More... | |
| void | sub (int n, long hA, long hB, long hY, int nAOff=0, int nBOff=0, int nYOff=0, int nB=0) |
| Subtracts B from A and places the result in Y. More... | |
| void | mul (int n, long hA, long hB, long hY, int nAOff=0, int nBOff=0, int nYOff=0) |
| Multiplies each element of A with each element of B and places the result in Y. More... | |
| void | sub_and_dot (int n, int nN, int nInnerNum, long hA, long hB, long hY, int nAOff, int nBOff, int nYOff) |
| Subtracts every nInnterNum element of B from A and performs a dot product on the result. More... | |
| void | mul_scalar (int n, double fAlpha, long hY) |
| Mutlipy each element of Y by a scalar. More... | |
| void | mul_scalar (int n, float fAlpha, long hY) |
| Mutlipy each element of Y by a scalar. More... | |
| void | mul_scalar (int n, T fAlpha, long hY) |
| Mutlipy each element of Y by a scalar. More... | |
| void | div (int n, long hA, long hB, long hY) |
| Divides each element of A by each element of B and places the result in Y. More... | |
| void | abs (int n, long hA, long hY) |
| Calculates the absolute value of A and places the result in Y. More... | |
| void | exp (int n, long hA, long hY) |
| Calculates the exponent value of A and places the result in Y. More... | |
| void | exp (int n, long hA, long hY, int nAOff, int nYOff, double dfBeta) |
| Calculates the exponent value of A * beta and places the result in Y. More... | |
| void | log (int n, long hA, long hY) |
| Calculates the log value of A and places the result in Y. More... | |
| void | log (int n, long hA, long hY, double dfBeta, double dfAlpha=0) |
| Calculates the log value of (A * beta) + alpha, and places the result in Y. More... | |
| void | powx (int n, long hA, double fAlpha, long hY, int nAOff=0, int nYOff=0) |
| Calculates the A raised to the power alpha and places the result in Y. More... | |
| void | powx (int n, long hA, float fAlpha, long hY, int nAOff=0, int nYOff=0) |
| Calculates the A raised to the power alpha and places the result in Y. More... | |
| void | powx (int n, long hA, T fAlpha, long hY, int nAOff=0, int nYOff=0) |
| Calculates the A raised to the power alpha and places the result in Y. More... | |
| void | sign (int n, long hX, long hY, int nXOff=0, int nYOff=0) |
| Computes the sign of each element of X and places the result in Y. More... | |
| void | sqrt (int n, long hX, long hY) |
| Computes the square root of each element of X and places the result in Y. More... | |
| void | sqrt_scale (int nCount, long hX, long hY) |
| Scale the data by the sqrt of the data. y = sqrt(abs(x)) * sign(x) More... | |
| void | compare_signs (int n, long hA, long hB, long hY) |
| Compares the signs of each value in A and B and places the result in Y. More... | |
| void | max (int n, long hA, long hB, long hY) |
| Calculates the max of A and B and places the result in Y. This max is only computed on a per item basis, so the shape of Y = the shape of A and B and Y(0) contains the max of A(0) and B(0), etc. More... | |
| void | max_bwd (int n, long hAdata, long hBdata, long hYdiff, long hAdiff, long hBdiff) |
| Propagates the Y diff back to the max of A or B and places the result in A if its data has the max, or B if its data has the max. More... | |
| void | min (int n, long hA, long hB, long hY) |
| Calculates the min of A and B and places the result in Y. This min is only computed on a per item basis, so the shape of Y = the shape of A and B and Y(0) contains the min of A(0) and B(0), etc. More... | |
| double | max (int n, long hA, out long lPos, int nAOff=0, long hWork=0) |
| Finds the maximum value of A. More... | |
| double | min (int n, long hA, out long lPos, int nAOff=0, long hWork=0) |
| Finds the minimum value of A. More... | |
| Tuple< double, double, double, double > | minmax (int n, long hA, long hWork1, long hWork2, bool bDetectNans=false, int nAOff=0) |
| Finds the minimum and maximum values within A. More... | |
| void | minmax (int n, long hA, long hWork1, long hWork2, int nK, long hMin, long hMax, bool bNonZeroOnly) |
| Finds up to 'nK' minimum and maximum values within A. More... | |
| void | transpose (int n, long hX, long hY, long hXCounts, long hYCounts, long hMapping, int nNumAxes, long hBuffer) |
| Perform a transpose on X producing Y, similar to the numpy.transpose operation. More... | |
| double | sumsq (int n, long hW, long hA, int nAOff=0) |
| Calculates the sum of squares of A. More... | |
| double | sumsqdiff (int n, long hW, long hA, long hB, int nAOff=0, int nBOff=0) |
| Calculates the sum of squares of differences between A and B More... | |
| void | width (int n, long hMean, long hMin, long hMax, double dfAlpha, long hWidth) |
| Calculates the width values. More... | |
| bool | contains_point (int n, long hMean, long hWidth, long hX, long hWork, int nXOff=0) |
| Returns true if the point is contained within the bounds. More... | |
| void | denan (int n, long hX, double dfReplacement) |
| Replaces all NAN values witin X with a replacement value. More... | |
| void | im2col (long hDataIm, int nDataImOffset, int nChannels, int nHeight, int nWidth, int nKernelH, int nKernelW, int nPadH, int nPadW, int nStrideH, int nStrideW, int nDilationH, int nDilationW, long hDataCol, int nDataColOffset) |
| Rearranges image blocks into columns. More... | |
| void | im2col_nd (long hDataIm, int nDataImOffset, int nNumSpatialAxes, int nImCount, int nChannelAxis, long hImShape, long hColShape, long hKernelShape, long hPad, long hStride, long hDilation, long hDataCol, int nDataColOffset) |
| Rearranges image blocks into columns. More... | |
| void | col2im (long hDataCol, int nDataColOffset, int nChannels, int nHeight, int nWidth, int nKernelH, int nKernelW, int nPadH, int nPadW, int nStrideH, int nStrideW, int nDilationH, int nDilationW, long hDataIm, int nDataImOffset) |
| Rearranges the columns into image blocks. More... | |
| void | col2im_nd (long hDataCol, int nDataColOffset, int nNumSpatialAxes, int nColCount, int nChannelAxis, long hImShape, long hColShape, long hKernelShape, long hPad, long hStride, long hDilation, long hDataIm, int nDataImOffset) |
| Rearranges the columns into image blocks. More... | |
| void | channel_min (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, bool bReturnIdx=false) |
| Calculates the minimum value within each channel of X and places the result in Y. More... | |
| void | channel_max (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, bool bReturnIdx=false) |
| Calculates the maximum value within each channel of X and places the result in Y. More... | |
| void | channel_mean (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY) |
| Calculates the mean value of each channel of X and places the result in Y. More... | |
| void | channel_compare (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY) |
| Compares the values of the channels from X and places the result in Y where 1 is set if the values are equal otherwise 0 is set. More... | |
| void | channel_fillfrom (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, DIR dir) |
| Fills each channel with the the values stored in Src data where the X data continains nOuterNum x nChannels of data, (e.g. one item per channel) that is then copied to all nInnerNum elements of each channel in Y More... | |
| void | channel_fill (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, int nLabelDim, long hLabels, long hY) |
| Fills each channel with the channel item of Y with the data of X matching the label index specified by hLabels. More... | |
| void | channel_sub (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hA, long hX, long hY) |
| Subtracts the values across the channels of X from A and places the result in Y. More... | |
| void | channel_sub (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY) |
| Subtracts the values across the channels from X and places the result in Y. More... | |
| void | channel_sum (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, bool bSumAcrossChannels=true, DIR dir=DIR.FWD, int nChannelsY=-1) |
| Calculates the sum the the values either across or within each channel (depending on bSumAcrossChannels setting) of X and places the result in Y. More... | |
| void | channel_div (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, int nMethod=1) |
| Divides the values of the channels from X and places the result in Y. More... | |
| void | channel_mul (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, int nMethod=1) |
| Multiplies the values of the channels from X and places the result in Y. More... | |
| void | channel_mulv (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hA, long hX, long hC) |
| Multiplies the values in vector X by each channel in matrix A and places the result in matrix C. More... | |
| void | channel_scale (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hA, long hY) |
| Multiplies the values of the channels from X with the scalar values in B and places the result in Y. More... | |
| void | channel_dot (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hA, long hY) |
| Calculates the dot product the the values within each channel of X and places the result in Y. More... | |
| void | channel_duplicate (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY) |
| Duplicates each channel 'nInnerNum' of times in the destination. More... | |
| void | channel_percentile (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY, double dfPercentile) |
| Calculates the percentile along axis = 0. More... | |
| void | channel_op_fwd (OP op, int nCount, int nC, int nN1, int nSD1, int nN2, int nSD2, long hA, long hB, long hY) |
| Performs a channel operation forward on the data. More... | |
| void | channel_op_bwd (OP op, int nCount, int nC, int nN1, int nSD1, int nN2, int nSD2, int nCy, int nSDy, long hA, long hB, long hY, long hAd, long hBd, long hYd, long hWork) |
| Performs a channel operation backward on the data. More... | |
| void | channel_add (int nCount, int nOuterNum, int nChannels, int nBlocks, int nInnerNum, int nOffset, long hX, long hY, DIR dir) |
| Add data along channels similar to numpy split function but where the data is added instead of copied. More... | |
| void | channel_copy (int nCount, int nOuterNum, int nChannels, int nBlocks, int nInnerNum, int nOffset, long hX, long hY, DIR dir) |
| Copy data along channels similar to numpy split function. More... | |
| void | channel_copyall (int nCount, int nOuterNum, int nChannels, int nInnerNum, long hX, long hY) |
| Copy all data from X (shape 1,c,sd) to each num in Y (shape n,c,sd). More... | |
| void | sum (int nCount, int nOuterNum, int nInnerNum, long hX, long hY) |
| Calculates the sum of inner values of X and places the result in Y. More... | |
| void | rng_setseed (long lSeed) |
| Sets the random number generator seed used by random number operations. More... | |
| void | rng_uniform (int n, double fMin, double fMax, long hY) |
| Fill Y with random numbers using a uniform random distribution. More... | |
| void | rng_uniform (int n, float fMin, float fMax, long hY) |
| Fill Y with random numbers using a uniform random distribution. More... | |
| void | rng_uniform (int n, T fMin, T fMax, long hY) |
| Fill Y with random numbers using a uniform random distribution. More... | |
| void | rng_gaussian (int n, double fMu, double fSigma, long hY) |
| Fill Y with random numbers using a gaussian random distribution. More... | |
| void | rng_gaussian (int n, float fMu, float fSigma, long hY) |
| Fill Y with random numbers using a gaussian random distribution. More... | |
| void | rng_gaussian (int n, T fMu, T fSigma, long hY) |
| Fill Y with random numbers using a gaussian random distribution. More... | |
| void | rng_bernoulli (int n, double fNonZeroProb, long hY) |
| Fill Y with random numbers using a bernoulli random distribution. More... | |
| void | rng_bernoulli (int n, float fNonZeroProb, long hY) |
| Fill Y with random numbers using a bernoulli random distribution. More... | |
| void | rng_bernoulli (int n, T fNonZeroProb, long hY) |
| Fill Y with random numbers using a bernoulli random distribution. More... | |
| void | accuracy_fwd (int nCount, int nOuterNum, int nInnerNum, long hBottomData, long hBottomLabel, long hAccData, long hAccTotals, int? nIgnoreLabel, bool bLastElementOnly, int nBatch) |
| Performs the forward pass for the accuracy layer More... | |
| void | batchreidx_fwd (int nCount, int nInnerDim, long hBottomData, long hPermutData, long hTopData) |
| Performs the forward pass for batch re-index More... | |
| void | batchreidx_bwd (int nCount, int nInnerDim, long hTopDiff, long hTopIdx, long hBegins, long hCounts, long hBottomDiff) |
| Performs the backward pass for batch re-index More... | |
| void | embed_fwd (int nCount, long hBottomData, long hWeight, int nM, int nN, int nK, long hTopData) |
| Performs the forward pass for embed More... | |
| void | embed_bwd (int nCount, long hBottomData, long hTopDiff, int nM, int nN, int nK, long hWeightDiff) |
| Performs the backward pass for embed More... | |
| void | pooling_fwd (POOLING_METHOD method, int nCount, long hBottomData, int num, int nChannels, int nHeight, int nWidth, int nPooledHeight, int nPooledWidth, int nKernelH, int nKernelW, int nStrideH, int nStrideW, int nPadH, int nPadW, long hTopData, long hMask, long hTopMask) |
| Performs the forward pass for pooling using Cuda More... | |
| void | pooling_bwd (POOLING_METHOD method, int nCount, long hTopDiff, int num, int nChannels, int nHeight, int nWidth, int nPooledHeight, int nPooledWidth, int nKernelH, int nKernelW, int nStrideH, int nStrideW, int nPadH, int nPadW, long hBottomDiff, long hMask, long hTopMask) |
| Performs the backward pass for pooling using Cuda More... | |
| void | unpooling_fwd (POOLING_METHOD method, int nCount, long hBottomData, int num, int nChannels, int nHeight, int nWidth, int nPooledHeight, int nPooledWidth, int nKernelH, int nKernelW, int nStrideH, int nStrideW, int nPadH, int nPadW, long hTopData, long hMask) |
| Performs the forward pass for unpooling using Cuda More... | |
| void | unpooling_bwd (POOLING_METHOD method, int nCount, long hTopDiff, int num, int nChannels, int nHeight, int nWidth, int nPooledHeight, int nPooledWidth, int nKernelH, int nKernelW, int nStrideH, int nStrideW, int nPadH, int nPadW, long hBottomDiff, long hMask) |
| Performs the backward pass for unpooling using Cuda More... | |
| void | clip_fwd (int nCount, long hBottomData, long hTopData, T fMin, T fMax) |
| Performs a Clip forward pass in Cuda. More... | |
| void | clip_bwd (int nCount, long hTopDiff, long hBottomData, long hBottomDiff, T fMin, T fMax) |
| Performs a Clip backward pass in Cuda. More... | |
| void | math_fwd (int nCount, long hBottomData, long hTopData, MATH_FUNCTION function) |
| Performs a Math function forward pass in Cuda. More... | |
| void | math_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData, MATH_FUNCTION function) |
| Performs a Math function backward pass in Cuda. More... | |
| void | mean_error_loss_bwd (int nCount, long hPredicted, long hTarget, long hBottomDiff, MEAN_ERROR merr) |
| Performs a Mean Error Loss backward pass in Cuda. More... | |
| void | mish_fwd (int nCount, long hBottomData, long hTopData, double dfThreshold) |
| Performs a Mish forward pass in Cuda. More... | |
| void | mish_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData, double dfThreshold, int nMethod=0) |
| Performs a Mish backward pass in Cuda. More... | |
| void | gelu_fwd (int nCount, long hBottomData, long hTopData, bool bEnableBertVersion) |
| Performs a GELU forward pass in Cuda. More... | |
| void | gelu_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData, bool bEnableBertVersion) |
| Performs a GELU backward pass in Cuda. More... | |
| void | silu_fwd (int nCount, long hBottomData, long hTopData) |
| Performs the Sigmoid-weighted Linear Unit (SiLU) activation forward pass in Cuda. More... | |
| void | silu_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData) |
| Performs the Sigmoid-weighted Linear Unit (SiLU) activation backward pass in Cuda. More... | |
| void | softplus_fwd (int nCount, long hBottomData, long hTopData) |
| Performs the Softplus function forward, a smooth approximation of the ReLU function More... | |
| void | softplus_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData) |
| Performs the Softplus function backward, a smooth approximation of the ReLU function More... | |
| void | lecun_fwd (int nCount, long hBottomData, long hTopData) |
| Performs the LeCun's Tanh function forward More... | |
| void | lecun_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData) |
| Performs the LeCun's Tanh function backward More... | |
| void | serf_fwd (int nCount, long hBottomData, long hTopData, double dfThreshold) |
| Performs a Serf forward pass in Cuda. More... | |
| void | serf_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, long hBottomData, double dfThreshold) |
| Performs a Serf backward pass in Cuda. More... | |
| void | tanh_fwd (int nCount, long hBottomData, long hTopData) |
| Performs a TanH forward pass in Cuda. More... | |
| void | tanh_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff) |
| Performs a TanH backward pass in Cuda. More... | |
| void | sigmoid_fwd (int nCount, long hBottomData, long hTopData) |
| Performs a Sigmoid forward pass in Cuda. More... | |
| void | sigmoid_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff) |
| Performs a Sigmoid backward pass in Cuda. More... | |
| void | swish_bwd (int nCount, long hTopDiff, long hTopData, long hSigmoidOutputData, long hBottomDiff, double dfBeta) |
| Performs a Swish backward pass in Cuda. More... | |
| void | relu_fwd (int nCount, long hBottomData, long hTopData, T fNegativeSlope) |
| Performs a Rectifier Linear Unit (ReLU) forward pass in Cuda. More... | |
| void | relu_bwd (int nCount, long hTopDiff, long hTopData, long hBottomDiff, T fNegativeSlope) |
| Performs a Rectifier Linear Unit (ReLU) backward pass in Cuda. More... | |
| void | elu_fwd (int nCount, long hBottomData, long hTopData, double dfAlpha) |
| Performs a Exponential Linear Unit (ELU) forward pass in Cuda. More... | |
| void | elu_bwd (int nCount, long hTopDiff, long hTopData, long hBottomData, long hBottomDiff, double dfAlpha) |
| Performs a Exponential Linear Unit (ELU) backward pass in Cuda. More... | |
| void | dropout_fwd (int nCount, long hBottomData, long hMask, uint uiThreshold, T fScale, long hTopData) |
| Performs a dropout forward pass in Cuda. More... | |
| void | dropout_bwd (int nCount, long hTopDiff, long hMask, uint uiThreshold, T fScale, long hBottomDiff) |
| Performs a dropout backward pass in Cuda. More... | |
| void | bnll_fwd (int nCount, long hBottomData, long hTopData) |
| Performs a binomial normal log liklihod (BNLL) forward pass in Cuda. More... | |
| void | bnll_bwd (int nCount, long hTopDiff, long hBottomData, long hBottomDiff) |
| Performs a binomial normal log liklihod (BNLL) backward pass in Cuda. More... | |
| void | prelu_fwd (int nCount, int nChannels, int nDim, long hBottomData, long hTopData, long hSlopeData, int nDivFactor) |
| Performs Parameterized Rectifier Linear Unit (ReLU) forward pass in Cuda. More... | |
| void | prelu_bwd_param (int nCDim, int nNum, int nTopOffset, long hTopDiff, long hBottomData, long hBackBuffDiff) |
| Performs Parameterized Rectifier Linear Unit (ReLU) backward param pass in Cuda. More... | |
| void | prelu_bwd (int nCount, int nChannels, int nDim, long hTopDiff, long hBottomData, long hBottomDiff, long hSlopeData, int nDivFactor) |
| Performs Parameterized Rectifier Linear Unit (ReLU) backward pass in Cuda. More... | |
| void | softmaxloss_fwd (int nCount, long hProbData, long hLabel, long hLossData, int nOuterNum, int nDim, int nInnerNum, long hCounts, int? nIgnoreLabel) |
| Performs Softmax Loss forward pass in Cuda. More... | |
| void | softmaxloss_bwd (int nCount, long hTopData, long hLabel, long hBottomDiff, int nOuterNum, int nDim, int nInnerNum, long hCounts, int? nIgnoreLabel) |
| Performs Softmax Loss backward pass in Cuda. More... | |
| void | nllloss_fwd (int nCount, long hProbData, long hLabel, long hLossData, int nOuterNum, int nDim, int nInnerNum, long hCounts, int? nIgnoreLabel) |
| Performs NLL Loss forward pass in Cuda. More... | |
| void | nllloss_bwd (int nCount, long hTopData, long hLabel, long hBottomDiff, int nOuterNum, int nDim, int nInnerNum, long hCounts, int? nIgnoreLabel) |
| Performs NLL Loss backward pass in Cuda. More... | |
| void | max_fwd (int nCount, long hBottomDataA, long hBottomDataB, int nIdx, long hTopData, long hMask) |
| Performs a max forward pass in Cuda. More... | |
| void | max_bwd (int nCount, long hTopDiff, int nIdx, long hMask, long hBottomDiff) |
| Performs a max backward pass in Cuda. More... | |
| void | min_fwd (int nCount, long hBottomDataA, long hBottomDataB, int nIdx, long hTopData, long hMask) |
| Performs a min forward pass in Cuda. More... | |
| void | min_bwd (int nCount, long hTopDiff, int nIdx, long hMask, long hBottomDiff) |
| Performs a min backward pass in Cuda. More... | |
| void | crop_fwd (int nCount, int nNumAxes, long hSrcStrides, long hDstStrides, long hOffsets, long hBottomData, long hTopData) |
| Performs the crop forward operation. More... | |
| void | crop_bwd (int nCount, int nNumAxes, long hSrcStrides, long hDstStrides, long hOffsets, long hBottomDiff, long hTopDiff) |
| Performs the crop backward operation. More... | |
| void | concat_fwd (int nCount, long hBottomData, int nNumConcats, int nConcatInputSize, int nTopConcatAxis, int nBottomConcatAxis, int nOffsetConcatAxis, long hTopData) |
| Performs a concat forward pass in Cuda. More... | |
| void | concat_bwd (int nCount, long hTopDiff, int nNumConcats, int nConcatInputSize, int nTopConcatAxis, int nBottomConcatAxis, int nOffsetConcatAxis, long hBottomDiff) |
| Performs a concat backward pass in Cuda. More... | |
| void | slice_fwd (int nCount, long hBottomData, int nNumSlices, int nSliceSize, int nBottomSliceAxis, int nTopSliceAxis, int nOffsetSliceAxis, long hTopData) |
| Performs a slice forward pass in Cuda. More... | |
| void | slice_bwd (int nCount, long hTopDiff, int nNumSlices, int nSliceSize, int nBottomSliceAxis, int nTopSliceAxis, int nOffsetSliceAxis, long hBottomDiff) |
| Performs a slice backward pass in Cuda. More... | |
| void | tile_fwd (int nCount, long hBottomData, int nInnerDim, int nTiles, int nBottomTileAxis, long hTopData) |
| Performs a tile forward pass in Cuda. More... | |
| void | tile_bwd (int nCount, long hTopDiff, int nTileSize, int nTiles, int nBottomTileAxis, long hBottomDiff) |
| Performs a tile backward pass in Cuda. More... | |
| void | bias_fwd (int nCount, long hBottomData, long hBiasData, int nBiasDim, int nInnerDim, long hTopData) |
| Performs a bias forward pass in Cuda. More... | |
| void | scale_fwd (int nCount, long hX, long hScaleData, int nScaleDim, int nInnerDim, long hY, long hBiasData=0) |
| Performs a scale forward pass in Cuda. More... | |
| void | threshold_fwd (int nCount, double dfThreshold, long hX, long hY) |
| Performs a threshold pass in Cuda. More... | |
| void | cll_bwd (int nCount, int nChannels, double dfMargin, bool bLegacyVersion, double dfAlpha, long hY, long hDiff, long hDistSq, long hBottomDiff) |
| Performs a contrastive loss layer backward pass in Cuda. More... | |
| void | smoothl1_fwd (int nCount, long hX, long hY) |
| Performs the forward operation for the SmoothL1 loss. More... | |
| void | smoothl1_bwd (int nCount, long hX, long hY) |
| Performs the backward operation for the SmoothL1 loss. More... | |
| void | permute (int nCount, long hBottom, bool bFwd, long hPermuteOrder, long hOldSteps, long hNewSteps, int nNumAxes, long hTop) |
| Performs data permutation on the input and reorders the data which is placed in the output. More... | |
| void | gather_fwd (int nCount, long hBottom, long hTop, int nAxis, int nDim, int nDimAtAxis, int nM, int nN, long hIdx) |
| Performs a gather forward pass where data at specifies indexes along a given axis are copied to the output data. More... | |
| void | gather_bwd (int nCount, long hTop, long hBottom, int nAxis, int nDim, int nDimAtAxis, int nM, int nN, long hIdx) |
| Performs a gather backward pass where data at specifies indexes along a given axis are copied to the output data. More... | |
| void | lrn_fillscale (int nCount, long hBottomData, int nNum, int nChannels, int nHeight, int nWidth, int nSize, T fAlphaOverSize, T fK, long hScaleData) |
| Performs the fill scale operation used to calculate the LRN cross channel forward pass in Cuda. More... | |
| void | lrn_computeoutput (int nCount, long hBottomData, long hScaleData, T fNegativeBeta, long hTopData) |
| Computes the output used to calculate the LRN cross channel forward pass in Cuda. More... | |
| void | lrn_computediff (int nCount, long hBottomData, long hTopData, long hScaleData, long hTopDiff, int nNum, int nChannels, int nHeight, int nWidth, int nSize, T fNegativeBeta, T fCacheRatio, long hBottomDiff) |
| Computes the diff used to calculate the LRN cross channel backward pass in Cuda. More... | |
| void | sgd_update (int nCount, long hNetParamsDiff, long hHistoryData, T fMomentum, T fLocalRate) |
| Perform the Stochastic Gradient Descent (SGD) update More... | |
| void | nesterov_update (int nCount, long hNetParamsDiff, long hHistoryData, T fMomentum, T fLocalRate) |
| Perform the Nesterov update More... | |
| void | adagrad_update (int nCount, long hNetParamsDiff, long hHistoryData, T fDelta, T fLocalRate) |
| Perform the AdaGrad update More... | |
| void | adadelta_update (int nCount, long hNetParamsDiff, long hHistoryData1, long hHistoryData2, T fMomentum, T fDelta, T fLocalRate) |
| Perform the AdaDelta update More... | |
| void | adam_update (int nCount, long hNetParamsDiff, long hValM, long hValV, T fBeta1, T fBeta2, T fEpsHat, T fLearningRate, T fCorrection) |
| Perform the Adam update More... | |
| void | adamw_update (int nCount, long hNetParamsDiff, long hValM, long hValV, T fBeta1, T fBeta2, T fEpsHat, T fLearningRate, T fDecayRate, long hNetParamsData, int nStep) |
| Perform the AdamW update More... | |
| void | rmsprop_update (int nCount, long hNetParamsDiff, long hHistoryData, T fRmsDecay, T fDelta, T fLocalRate) |
| Perform the RMSProp update More... | |
| void | lstm_fwd (int t, int nN, int nH, int nI, long hWeight_h, long hWeight_i, long hClipData, int nClipOffset, long hTopData, int nTopOffset, long hCellData, int nCellOffset, long hPreGateData, int nPreGateOffset, long hGateData, int nGateOffset, long hHT1Data, int nHT1Offset, long hCT1Data, int nCT1Offset, long hHtoGateData, long hContext=0, long hWeight_c=0, long hCtoGetData=0) |
| Peforms the simple LSTM foward pass in Cuda. More... | |
| void | lstm_bwd (int t, int nN, int nH, int nI, double dfClippingThreshold, long hWeight_h, long hClipData, int nClipOffset, long hTopDiff, int nTopOffset, long hCellData, long hCellDiff, int nCellOffset, long hPreGateDiff, int nPreGateOffset, long hGateData, long hGateDiff, int nGateOffset, long hCT1Data, int nCT1Offset, long hDHT1Diff, int nDHT1Offset, long hDCT1Diff, int nDCT1Offset, long hHtoHData, long hContextDiff=0, long hWeight_c=0) |
| Peforms the simple LSTM backward pass in Cuda. More... | |
| void | lstm_unit_fwd (int nCount, int nHiddenDim, int nXCount, long hX, long hX_acts, long hC_prev, long hCont, long hC, long hH) |
| Peforms the simple LSTM foward pass in Cuda for a given LSTM unit. More... | |
| void | lstm_unit_bwd (int nCount, int nHiddenDim, int nXCount, long hC_prev, long hX_acts, long hC, long hH, long hCont, long hC_diff, long hH_diff, long hC_prev_diff, long hX_acts_diff, long hX_diff) |
| Peforms the simple LSTM backward pass in Cuda for a given LSTM unit. More... | |
| void | coeff_sum_fwd (int nCount, int nDim, int nNumOffset, double dfCoeff, long hCoeffData, long hBottom, long hTop) |
| Performs a coefficient sum foward pass in Cuda. More... | |
| void | coeff_sum_bwd (int nCount, int nDim, int nNumOffset, double dfCoeff, long hCoeffData, long hTopDiff, long hBottomDiff) |
| Performs a coefficient sum backward pass in Cuda. More... | |
| void | coeff_sub_fwd (int nCount, int nDim, int nNumOffset, double dfCoeff, long hCoeffData, long hBottom, long hTop) |
| Performs a coefficient sub foward pass in Cuda. More... | |
| void | coeff_sub_bwd (int nCount, int nDim, int nNumOffset, double dfCoeff, long hCoeffData, long hTopDiff, long hBottomDiff) |
| Performs a coefficient sub backward pass in Cuda. More... | |
| void | sigmoid_cross_entropy_fwd (int nCount, long hInput, long hTarget, long hLoss, bool bHasIgnoreLabel, int nIgnoreLabel, long hCountData) |
| Performs a sigmoid cross entropy forward pass in Cuda. More... | |
| void | sigmoid_cross_entropy_bwd (int nCount, int nIgnoreLabel, long hTarget, long hBottomDiff) |
| Performs a sigmoid cross entropy backward pass in Cuda when an ignore label is specified. More... | |
| void | softmax_cross_entropy_fwd (int nCount, long hProbData, long hLabel, long hLossDiff, long hLossData, int nOuterNum, int nDim, int nInnerNum, long hCounts, int? nIgnoreLabel) |
| Performs a softmax cross entropy forward pass in Cuda. More... | |
| void | softmax_cross_entropy_bwd (int nCount, int nIgnoreLabel, long hTarget, long hBottomDiff) |
| Performs a softmax cross entropy backward pass in Cuda when an ignore label is specified. More... | |
| void | debug () |
| The debug function is uses only during debugging the debug version of the low-level DLL. More... | |
| void | matrix_meancenter_by_column (int nWidth, int nHeight, long hA, long hB, long hY, bool bNormalize=false) |
| Mean center the data by columns, where each column is summed and then subtracted from each column value. More... | |
| void | gaussian_blur (int n, int nChannels, int nHeight, int nWidth, double dfSigma, long hX, long hY) |
| The gaussian_blur runs a Gaussian blurring operation over each channel of the data using the sigma. More... | |
| double | hamming_distance (int n, double dfThreshold, long hA, long hB, long hY, int nOffA=0, int nOffB=0, int nOffY=0) |
| The hamming_distance calculates the Hamming Distance between X and Y both of length n. More... | |
| void | calc_dft_coefficients (int n, long hX, int m, long hY) |
| Calculates the discrete Fourier Transform (DFT) coefficients across the frequencies 1...n/2 (Nyquest Limit) for the array of values in host memory referred to by hA. Return values are placed in the host memory referenced by hY. More... | |
| double[] | calculate_batch_distances (DistanceMethod distMethod, double dfThreshold, int nItemDim, long hSrc, long hTargets, long hWork, int[,] rgOffsets) |
| The calculate_batch_distances method calculates a set of distances based on the DistanceMethod specified. More... | |
| void | ReportMemory (Log log, string strLocation) |
| Report the memory use on the current GPU managed by the CudaDnn object. More... | |
Static Public Member Functions | |
| static string | GetCudaDnnDllPath () |
| Returns the path to the CudaDnnDll module to use for low level CUDA processing. More... | |
| static void | SetDefaultCudaPath (string strPath) |
| Used to optionally set the default path to the Low-Level Cuda Dnn DLL file. More... | |
| static ulong | basetype_size (bool bUseHalfSize) |
| Returns the base type size in bytes. More... | |
| static ulong | ConvertByteSizeToCount (ulong ulSizeInBytes) |
| Converts the byte size into the number of items in the base data type of float or double. More... | |
Protected Member Functions | |
| virtual void | Dispose (bool bDisposing) |
| Disposes this instance freeing up all of its host and GPU memory. More... | |
Properties | |
| ulong | TotalMemoryUsed [get] |
| Returns the total amount of GPU memory used by this instance. More... | |
| string | TotalMemoryUsedAsText [get] |
| Returns the total amount of memory used. More... | |
| long | KernelHandle [get] |
| Returns the Low-Level kernel handle used for this instance. Each Low-Level kernel maintains its own set of look-up tables for memory, streams, cuDnn constructs, etc. More... | |
| string | Path [get] |
| Specifies the file path used to load the Low-Level Cuda DNN Dll file. More... | |
| static string | DefaultPath [get] |
| Specifies the default path used t load the Low-Level Cuda DNN Dll file. More... | |
| int | OriginalDeviceID [get] |
| Returns the original device ID used to create the instance of CudaDnn. More... | |
| static ulong | BaseSize [get] |
| Returns the base data type size (e.g. float= 4, double = 8). More... | |
The CudaDnn object is the main interface to the Low-Level Cuda C++ DLL.
This is the transition location where C# meets C++.
| T | Specifies the base type float or double. Using float is recommended to conserve GPU memory. |
Definition at line 968 of file CudaDnn.cs.
| MyCaffe.common.CudaDnn< T >.CudaDnn | ( | int | nDeviceID, |
| DEVINIT | flags = (DEVINIT.CUBLAS | DEVINIT.CURAND), |
||
| long? | lSeed = null, |
||
| string | strPath = "", |
||
| bool | bResetFirst = false, |
||
| bool | bEnableMemoryTrace = false |
||
| ) |
The CudaDnn constructor.
| nDeviceID | Specifies the zero-based device (GPU) id. Note, if there are 5 GPU's in the system, the device ID's will be numbered 0, 1, 2, 3, 4. |
| flags | Specifies the flags under which to initialize the Low-Level Cuda system. |
| lSeed | Optionally specifies the random number generator seed. Typically this is only used during testing. |
| strPath | Specifies the file path of the Low-Level Cuda DNN Dll file. When NULL or empty, the Low-Level CudaDNNDll.dll
|
| bResetFirst | Specifies to reset the device before initialzing. IMPORTANT: It is only recommended to set this to true
|
| bEnableMemoryTrace | Optionally, specifies to enable the memory tracing (only supported in debug mode and dramatically slows down processing). |
Definition at line 1488 of file CudaDnn.cs.
| MyCaffe.common.CudaDnn< T >.CudaDnn | ( | CudaDnn< T > | cuda, |
| bool | bEnableGhostMemory | ||
| ) |
Alternate CudaDnn constructor.
| cuda | Specifies an already created CudaDn instance. The internal Cuda Control of this instance is used by the new instance. |
| bEnableGhostMemory | Specifies to enable the ghost memory used to estimate GPU memory usage without allocating any GPU memory. |
Definition at line 1587 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.abs | ( | int | n, |
| long | hA, | ||
| long | hY | ||
| ) |
Calculates the absolute value of A and places the result in Y.
Y = abs(X)
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7437 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.accuracy_fwd | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nInnerNum, | ||
| long | hBottomData, | ||
| long | hBottomLabel, | ||
| long | hAccData, | ||
| long | hAccTotals, | ||
| int? | nIgnoreLabel, | ||
| bool | bLastElementOnly, | ||
| int | nBatch | ||
| ) |
Performs the forward pass for the accuracy layer
| nCount | Specifies the number of items. |
| nOuterNum | Specifies the outer count. |
| nInnerNum | Specifies the inner count. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hBottomLabel | Specifies a handle to the bottom labels in GPU memory. |
| hAccData | Specifies a handle to temporary accuracy correct items in GPU memory. |
| hAccTotals | Specifies a handle to the temporary accuracy totals in GPU memory. |
| nIgnoreLabel | Optionally, specifies a label to igore. |
| bLastElementOnly | Optionally specifies to only test the last element in each set. |
| nBatch | Optionally specifies the batch size. |
Definition at line 8700 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.adadelta_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hHistoryData1, | ||
| long | hHistoryData2, | ||
| T | fMomentum, | ||
| T | fDelta, | ||
| T | fLocalRate | ||
| ) |
Perform the AdaDelta update
See ADADELTA: An Adaptive Learning Rate Method by Zeiler, 2012
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hHistoryData1 | Specifies a handle to history data in GPU memory. |
| hHistoryData2 | Specifies a handle to history data in GPU memory. |
| fMomentum | Specifies the momentum to use. |
| fDelta | Specifies the numerical stability factor. |
| fLocalRate | Specifies the local learning rate. |
Definition at line 10264 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.adagrad_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hHistoryData, | ||
| T | fDelta, | ||
| T | fLocalRate | ||
| ) |
Perform the AdaGrad update
See Adaptive Subgradient Methods for Online Learning and Stochastic Optimization by Duchi, et al., 2011
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hHistoryData | Specifies a handle to the history data in GPU memory. |
| fDelta | Specifies the numerical stability factor. |
| fLocalRate | Specifies the local learning rate. |
Definition at line 10243 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.adam_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hValM, | ||
| long | hValV, | ||
| T | fBeta1, | ||
| T | fBeta2, | ||
| T | fEpsHat, | ||
| T | fLearningRate, | ||
| T | fCorrection | ||
| ) |
Perform the Adam update
See Adam: A Method for Stochastic Optimization by Kingma, et al., 2014
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hValM | First moment. |
| hValV | Second moment. |
| fBeta1 | Momentum for first moment. |
| fBeta2 | Momentum for second moment. |
| fEpsHat | Small value used to avoid Nan. |
| fLearningRate | Learning rate. |
| fCorrection | Correction where Local Learning Rate = 'fCorrection' * 'fLearningRate' |
Definition at line 10287 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.adamw_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hValM, | ||
| long | hValV, | ||
| T | fBeta1, | ||
| T | fBeta2, | ||
| T | fEpsHat, | ||
| T | fLearningRate, | ||
| T | fDecayRate, | ||
| long | hNetParamsData, | ||
| int | nStep | ||
| ) |
Perform the AdamW update
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hValM | First moment. |
| hValV | Second moment. |
| fBeta1 | Momentum for first moment. |
| fBeta2 | Momentum for second moment. |
| fEpsHat | Small value used to avoid Nan. |
| fLearningRate | Learning rate. |
| fDecayRate | Optionally, enable detached weight decay for AdamW optimization using this decay rate (when 0, Adam update is used). |
| hNetParamsData | Optionally, specifies the net params weight data (used when fDecayRate != 0) |
| nStep | Optionally, specifies the current step - used with AdamW optimization updates. |
Definition at line 10313 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hC, | ||
| long | hY | ||
| ) |
Adds A, B and C and places the result in Y.
Y = A + B + C
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hC | Specifies a handle to the vector C in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7209 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY | ||
| ) |
Adds A to B and places the result in Y.
Y = A + B
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7227 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| double | dfAlpha | ||
| ) |
Adds A to (B times scalar) and places the result in Y.
Y = A + (B * alpha)
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| dfAlpha | Specifies a scalar int type double
|
Definition at line 7246 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| double | dfAlphaA, | ||
| double | dfAlphaB, | ||
| int | nAOff = 0, |
||
| int | nBOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Adds A to (B times scalar) and places the result in Y.
Y = A + (B * alpha)
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| dfAlphaA | Specifies a scalar int type 'T' applied to A. |
| dfAlphaB | Specifies a scalar int type 'T' applied to B. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A. |
| nBOff | Optionally, specifies an offset (in items, not bytes) into the memory of B. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 7288 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| float | fAlpha | ||
| ) |
Adds A to (B times scalar) and places the result in Y.
Y = A + (B * alpha)
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| fAlpha | Specifies a scalar int type float
|
Definition at line 7265 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add_scalar | ( | int | n, |
| double | fAlpha, | ||
| long | hY | ||
| ) |
Adds a scalar value to each element of Y.
Y = Y + alpha
| n | Specifies the number of items (not bytes) in the vector Y. |
| fAlpha | Specifies the scalar value in type double
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7161 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add_scalar | ( | int | n, |
| float | fAlpha, | ||
| long | hY | ||
| ) |
Adds a scalar value to each element of Y.
Y = Y + alpha
| n | Specifies the number of items (not bytes) in the vector Y. |
| fAlpha | Specifies the scalar value in type float
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7175 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.add_scalar | ( | int | n, |
| T | fAlpha, | ||
| long | hY, | ||
| int | nYOff = 0 |
||
| ) |
Adds a scalar value to each element of Y.
Y = Y + alpha
| n | Specifies the number of items (not bytes) in the vector Y. |
| fAlpha | Specifies the scalar value in type 'T'. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nYOff | Optionally, specifies an offset into Y. The default is 0. |
Definition at line 7190 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.AddTensor | ( | long | hCuDnn, |
| long | hSrcDesc, | ||
| long | hSrc, | ||
| int | nSrcOffset, | ||
| long | hDstDesc, | ||
| long | hDst, | ||
| int | nDstOffset | ||
| ) |
Add two tensors together.
| hCuDnn | Specifies a handle to the cuDnn instance. |
| hSrcDesc | Specifies a handle to the source tensor descriptor. |
| hSrc | Specifies a handle to the source GPU memory. |
| nSrcOffset | Specifies an offset within the GPU memory. |
| hDstDesc | Specifies a handle to the destination tensor descriptor. |
| hDst | Specifies a handle to the desination GPU memory. |
| nDstOffset | Specifies an offset within the GPU memory. |
Definition at line 3638 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.AddTensor | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hSrcDesc, | ||
| long | hSrc, | ||
| int | nSrcOffset, | ||
| T | fBeta, | ||
| long | hDstDesc, | ||
| long | hDst, | ||
| int | nDstOffset | ||
| ) |
Add two tensors together.
| hCuDnn | Specifies a handle to the cuDnn instance. |
| fAlpha | Specifies a scaling factor applied to the source GPU memory before the add. |
| hSrcDesc | Specifies a handle to the source tensor descriptor. |
| hSrc | Specifies a handle to the source GPU memory. |
| nSrcOffset | Specifies an offset within the GPU memory. |
| fBeta | Specifies a scaling factor applied to the destination GPU memory before the add. |
| hDstDesc | Specifies a handle to the destination tensor descriptor. |
| hDst | Specifies a handle to the desination GPU memory. |
| nDstOffset | Specifies an offset within the GPU memory. |
Definition at line 3655 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocHostBuffer | ( | long | lCapacity | ) |
Allocate a block of host memory with a specified capacity.
| lCapacity | Specifies the capacity to allocate (in items, not bytes). |
Definition at line 2581 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocMemory | ( | double[] | rgSrc, |
| long | hStream = 0 |
||
| ) |
Allocate a block of GPU memory and copy an array of doubles to it, optionally using a stream for the copy.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| rgSrc | Specifies an array of doubles to copy to the GPU. |
| hStream | Optionally specifies a stream to use for the copy. |
Definition at line 2314 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocMemory | ( | float[] | rgSrc, |
| long | hStream = 0 |
||
| ) |
Allocate a block of GPU memory and copy an array of float to it, optionally using a stream for the copy.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| rgSrc | Specifies an array of float to copy to the GPU. |
| hStream | Optionally specifies a stream to use for the copy. |
Definition at line 2326 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocMemory | ( | List< double > | rg | ) |
Allocate a block of GPU memory and copy a list of doubles to it.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| rg | Specifies a list of doubles to copy to the GPU. |
Definition at line 2291 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocMemory | ( | List< float > | rg | ) |
Allocate a block of GPU memory and copy a list of floats to it.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| rg | Specifies a list of floats to copy to the GPU. |
Definition at line 2302 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocMemory | ( | long | lCapacity, |
| bool | bHalfSize = false |
||
| ) |
Allocate a block of GPU memory with a specified capacity.
| lCapacity | Specifies the capacity to allocate (in items, not bytes). |
| bHalfSize | Optionally, specifies to use half size float memory - only available with the 'float' base type. |
Definition at line 2449 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocMemory | ( | T[] | rgSrc, |
| long | hStream = 0, |
||
| bool | bHalfSize = false |
||
| ) |
Allocate a block of GPU memory and copy an array of type 'T' to it, optionally using a stream for the copy.
| rgSrc | Specifies an array of 'T' to copy to the GPU. |
| hStream | Optionally, specifies a stream to use for the copy. |
| bHalfSize | Optionally, specifies to use half size float memory - only available with the 'float' base type. |
Definition at line 2338 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocPCAData | ( | int | nM, |
| int | nN, | ||
| int | nK, | ||
| out int | nCount | ||
| ) |
Allocates the GPU memory for the PCA Data.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| nM | Specifies the data width (number of rows). |
| nN | Specifies the data height (number of columns). |
| nK | Specifies the number of components (K <= N). |
| nCount | Returns the total number of items in the allocated data (nM * nN). |
Definition at line 5319 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocPCAEigenvalues | ( | int | nM, |
| int | nN, | ||
| int | nK, | ||
| out int | nCount | ||
| ) |
Allocates the GPU memory for the PCA eigenvalues.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| nM | Specifies the data width (number of rows). |
| nN | Specifies the data height (number of columns). |
| nK | Specifies the number of components (K <= N). |
| nCount | Returns the total number of items in the allocated data (nM * nN). |
Definition at line 5370 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocPCALoads | ( | int | nM, |
| int | nN, | ||
| int | nK, | ||
| out int | nCount | ||
| ) |
Allocates the GPU memory for the PCA loads.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| nM | Specifies the data width (number of rows). |
| nN | Specifies the data height (number of columns). |
| nK | Specifies the number of components (K <= N). |
| nCount | Returns the total number of items in the allocated data (nM * nN). |
Definition at line 5353 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.AllocPCAScores | ( | int | nM, |
| int | nN, | ||
| int | nK, | ||
| out int | nCount | ||
| ) |
Allocates the GPU memory for the PCA scores.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| nM | Specifies the data width (number of rows). |
| nN | Specifies the data height (number of columns). |
| nK | Specifies the number of components (K <= N). |
| nCount | Returns the total number of items in the allocated data (nM * nN). |
Definition at line 5336 of file CudaDnn.cs.
| T MyCaffe.common.CudaDnn< T >.asum | ( | int | n, |
| long | hX, | ||
| int | nXOff = 0 |
||
| ) |
Computes the sum of absolute values in X.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| nXOff | Optionally, specifies an offset (in items, not bytes) into the memory of X. |
Definition at line 6901 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.asum_double | ( | int | n, |
| long | hX, | ||
| int | nXOff = 0 |
||
| ) |
Computes the sum of absolute values in X.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| nXOff | Optionally, specifies an offset (in items, not bytes) into the memory of X. |
Definition at line 6871 of file CudaDnn.cs.
| float MyCaffe.common.CudaDnn< T >.asum_float | ( | int | n, |
| long | hX, | ||
| int | nXOff = 0 |
||
| ) |
Computes the sum of absolute values in X.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| nXOff | Optionally, specifies an offset (in items, not bytes) into the memory of X. |
Definition at line 6886 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.axpby | ( | int | n, |
| double | fAlpha, | ||
| long | hX, | ||
| double | fBeta, | ||
| long | hY | ||
| ) |
Scale the vector x and then multiply the vector X by a scalar and add the result to the vector Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scalar to multiply where the scalar is of type double
|
| hX | Specifies a handle to the vector X in GPU memory. |
| fBeta | Specifies the scaling factor to apply to vector X, where the scaling factor is of type double
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6595 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.axpby | ( | int | n, |
| float | fAlpha, | ||
| long | hX, | ||
| float | fBeta, | ||
| long | hY | ||
| ) |
Scale the vector x and then multiply the vector X by a scalar and add the result to the vector Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scalar to multiply where the scalar is of type float
|
| hX | Specifies a handle to the vector X in GPU memory. |
| fBeta | Specifies the scaling factor to apply to vector X, where the scaling factor is of type float
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6611 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.axpby | ( | int | n, |
| T | fAlpha, | ||
| long | hX, | ||
| T | fBeta, | ||
| long | hY | ||
| ) |
Scale the vector x by Alpha and scale vector y by Beta and then add both together.
Y = (X * fAlpha) + (Y * fBeta)
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scalar to multiply where the scalar is of type 'T'. |
| hX | Specifies a handle to the vector X in GPU memory. |
| fBeta | Specifies the scaling factor to apply to vector X, where the scaling factor is of type 'T'. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6629 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.axpy | ( | int | n, |
| double | fAlpha, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Multiply the vector X by a scalar and add the result to the vector Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scalar to multiply where the scalar is of type double
|
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6544 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.axpy | ( | int | n, |
| float | fAlpha, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Multiply the vector X by a scalar and add the result to the vector Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scalar to multiply where the scalar is of type float
|
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6559 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.axpy | ( | int | n, |
| T | fAlpha, | ||
| long | hX, | ||
| long | hY, | ||
| int | nXOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Multiply the vector X by a scalar and add the result to the vector Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scalar to multiply where the scalar is of type 'T'. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nXOff | Optionally, specifies an offset (in items, not bytes) into the memory of X. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 6576 of file CudaDnn.cs.
|
static |
Returns the base type size in bytes.
| bUseHalfSize | Specifies whether or not to use half size or the base size. |
Definition at line 1899 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.BatchNormBackward | ( | long | hCuDnn, |
| BATCHNORM_MODE | mode, | ||
| T | fAlphaDiff, | ||
| T | fBetaDiff, | ||
| T | fAlphaParamDiff, | ||
| T | fBetaParamDiff, | ||
| long | hBwdBottomDesc, | ||
| long | hBottomData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff, | ||
| long | hBwdScaleBiasMeanVarDesc, | ||
| long | hScaleData, | ||
| long | hScaleDiff, | ||
| long | hBiasDiff, | ||
| double | dfEps, | ||
| long | hSaveMean, | ||
| long | hSaveInvVar | ||
| ) |
Run the batch norm backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| mode | Specifies the batch normalization mode. |
| fAlphaDiff | Specifies the alpha value applied to the diff. |
| fBetaDiff | Specifies the beta value applied to the diff. |
| fAlphaParamDiff | Specifies the alpha value applied to the param diff. |
| fBetaParamDiff | Specifies the beta value applied to the param diff. |
| hBwdBottomDesc | Specifies a handle to the backward bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data tensor. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff tensor. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff tensor. |
| hBwdScaleBiasMeanVarDesc | Specifies a handle to the backward scale bias mean var descriptor. |
| hScaleData | Specifies a handle to the scale data tensor. |
| hScaleDiff | Specifies a handle to the scale diff tensor. |
| hBiasDiff | Specifies a handle to the bias diff tensor. |
| dfEps | Specifies the epsilon value. |
| hSaveMean | Specifies a handle to the saved mean tensor. |
| hSaveInvVar | Specifies a handle to the saved variance tensor. |
Definition at line 4191 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.BatchNormForward | ( | long | hCuDnn, |
| BATCHNORM_MODE | mode, | ||
| T | fAlpha, | ||
| T | fBeta, | ||
| long | hFwdBottomDesc, | ||
| long | hBottomData, | ||
| long | hFwdTopDesc, | ||
| long | hTopData, | ||
| long | hFwdScaleBiasMeanVarDesc, | ||
| long | hScaleData, | ||
| long | hBiasData, | ||
| double | dfFactor, | ||
| long | hGlobalMean, | ||
| long | hGlobalVar, | ||
| double | dfEps, | ||
| long | hSaveMean, | ||
| long | hSaveInvVar, | ||
| bool | bTraining | ||
| ) |
Run the batch norm forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| mode | Specifies the batch normalization mode. |
| fAlpha | Specifies the alpha value. |
| fBeta | Specifies the beta value. |
| hFwdBottomDesc | Specifies a handle to the forward bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data tensor. |
| hFwdTopDesc | Specifies a handle to the forward top tensor descriptor. |
| hTopData | Specifies a handle to the top tensor. |
| hFwdScaleBiasMeanVarDesc | Specifies a handle to the forward scale bias mean variance descriptor. |
| hScaleData | Specifies a handle to the scale tensor. |
| hBiasData | Specifies a handle to the bias tensor. |
| dfFactor | Specifies a scaling factor. |
| hGlobalMean | Specifies a handle to the global mean tensor. |
| hGlobalVar | Specifies a handle to the global variance tensor. |
| dfEps | Specifies the epsilon value to avoid dividing by zero. |
| hSaveMean | Specifies a handle to the saved mean tensor. |
| hSaveInvVar | Specifies a handle to the saved variance tensor. |
| bTraining | Specifies that this is a training pass when true, and a testing pass when false. |
Definition at line 4161 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.batchreidx_bwd | ( | int | nCount, |
| int | nInnerDim, | ||
| long | hTopDiff, | ||
| long | hTopIdx, | ||
| long | hBegins, | ||
| long | hCounts, | ||
| long | hBottomDiff | ||
| ) |
Performs the backward pass for batch re-index
| nCount | Specifies the number of items. |
| nInnerDim | Specifies the inner dimension. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopIdx | Specifies a handle to the top indexes in GPU memory. |
| hBegins | Specifies a handle to the begin data in GPU memory. |
| hCounts | Specifies a handle to the counts in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 8745 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.batchreidx_fwd | ( | int | nCount, |
| int | nInnerDim, | ||
| long | hBottomData, | ||
| long | hPermutData, | ||
| long | hTopData | ||
| ) |
Performs the forward pass for batch re-index
| nCount | Specifies the number of items. |
| nInnerDim | Specifies the inner dimension. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hPermutData | Specifies a handle to the permuation data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 8727 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.bias_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hBiasData, | ||
| int | nBiasDim, | ||
| int | nInnerDim, | ||
| long | hTopData | ||
| ) |
Performs a bias forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| hBiasData | Specifies a handle to the bias data in GPU memory. |
| nBiasDim | Specifies the bias dimension. |
| nInnerDim | NEEDS REVIEW |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9958 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.bnll_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hBottomData, | ||
| long | hBottomDiff | ||
| ) |
Performs a binomial normal log liklihod (BNLL) backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 9516 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.bnll_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs a binomial normal log liklihod (BNLL) forward pass in Cuda.
Computes 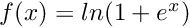
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9501 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.calc_dft_coefficients | ( | int | n, |
| long | hX, | ||
| int | m, | ||
| long | hY | ||
| ) |
Calculates the discrete Fourier Transform (DFT) coefficients across the frequencies 1...n/2 (Nyquest Limit) for the array of values in host memory referred to by hA. Return values are placed in the host memory referenced by hY.
| n | Specifies the number of items. |
| hX | Specifies a handle to the host memory holding the input values. |
| m | Specifies the number of items in hY, must = n/2 (Nyquest Limit) |
| hY | Specifies a handle to the host memory holding the n/2 output values (Nyquest Limit) |
Definition at line 11027 of file CudaDnn.cs.
| double[] MyCaffe.common.CudaDnn< T >.calculate_batch_distances | ( | DistanceMethod | distMethod, |
| double | dfThreshold, | ||
| int | nItemDim, | ||
| long | hSrc, | ||
| long | hTargets, | ||
| long | hWork, | ||
| int | rgOffsets[,] | ||
| ) |
The calculate_batch_distances method calculates a set of distances based on the DistanceMethod specified.
| distMethod | Specifies the DistanceMethod to use (i.e. HAMMING or EUCLIDEAN). |
| dfThreshold | Specifies the threshold used when binarifying the values for the HAMMING distance. This parameter is ignored when calculating the EUCLIDEAN distance. |
| nItemDim | Specifies the dimension of a single item. |
| hSrc | Specifies the GPU memory containing the source items. |
| hTargets | Specifies the GPU memory containing the target items that are compared against the source items. |
| hWork | Specifies the GPU memory containing the work memory - this must be the same size as the maximum size of the src or targets. |
| rgOffsets | Specifies the array of offset pairs where the first offset is into the source and the second is into the target. |
Definition at line 11046 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_add | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nBlocks, | ||
| int | nInnerNum, | ||
| int | nOffset, | ||
| long | hX, | ||
| long | hY, | ||
| DIR | dir | ||
| ) |
Add data along channels similar to numpy split function but where the data is added instead of copied.
| nCount | Specifies the total number of elements in Y which = count(X)/nBlocks in length. |
| nOuterNum | Specifies the number of items. |
| nChannels | Specifies the number of channels. |
| nBlocks | Specifies the number of blocks in each channel. |
| nInnerNum | Specifies the dimension of each inner dim within the channel. |
| nOffset | Specifies the offset of the inner dim. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| dir | Specifies the direction of data flow (0 = fwd X->Y, 1 = bwd Y->X). |
Definition at line 8437 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_compare | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Compares the values of the channels from X and places the result in Y where 1 is set if the values are equal otherwise 0 is set.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory of length nOuterNum. |
Definition at line 8133 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_copy | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nBlocks, | ||
| int | nInnerNum, | ||
| int | nOffset, | ||
| long | hX, | ||
| long | hY, | ||
| DIR | dir | ||
| ) |
Copy data along channels similar to numpy split function.
| nCount | Specifies the total number of elements in Y which = count(X)/nBlocks in length. |
| nOuterNum | Specifies the number of items. |
| nChannels | Specifies the number of channels. |
| nBlocks | Specifies the number of blocks in each channel. |
| nInnerNum | Specifies the dimension of each inner dim within the channel. |
| nOffset | Specifies the offset of the inner dim. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| dir | Specifies the direction of data flow (0 = fwd X->Y, 1 = bwd Y->X). |
Definition at line 8457 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_copyall | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Copy all data from X (shape 1,c,sd) to each num in Y (shape n,c,sd).
| nCount | Specifies the full count of Y. |
| nOuterNum | Specifies the outer num of Y. |
| nChannels | Specifies the channels in X and Y. |
| nInnerNum | Specifies the spatial dimension of X and Y. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8474 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_div | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| int | nMethod = 1 |
||
| ) |
Divides the values of the channels from X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nMethod | Specifies the method of traversing the channel, nMethod = 1 (the default) is used by the SoftmaxLayer and nMethod = 2 is used by the GRNLayer. |
Definition at line 8254 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_dot | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hA, | ||
| long | hY | ||
| ) |
Calculates the dot product the the values within each channel of X and places the result in Y.
| nCount | Specifies the number of elements. |
| nOuterNum | Specifies the number of images. |
| nChannels | Specifies the number of channels per image. |
| nInnerNum | Specifies the dimension of each image. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8326 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_duplicate | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Duplicates each channel 'nInnerNum' of times in the destination.
| nCount | Specifies the total number of elements in Y which = count(X)*nInnerDim in length. |
| nOuterNum | Specifies the number of items. |
| nChannels | Specifies the number of channels. |
| nInnerNum | Specifies the dimension of each inner dim within the channel. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8343 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_fill | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| int | nLabelDim, | ||
| long | hLabels, | ||
| long | hY | ||
| ) |
Fills each channel with the channel item of Y with the data of X matching the label index specified by hLabels.
| nCount | Specifies the number of items in Y. |
| nOuterNum | Specifies the num of Y and Labels. |
| nChannels | Specifies the channel size of Y and X. |
| nInnerNum | Specifies the spatial dimension of X and Y, but is normally 1. |
| hX | Specifies the GPU memory containing the encodings (usually centroids) of each label 0, ... max label. |
| nLabelDim | Specifies the dimension of the label channels. A value > 1 indicates that more than one label are stored per channel in which case only the first label is used. |
| hLabels | Specifies the label ordering that determines how Y is filled using data from X. |
| hY | Specifies the GPU memory of the output data. |
This function is used to fill a blob with data matching a set of labels. For example in a 3 item encoding based system with 4 labels: X = 4 channels of 3 items each (e.g. an encoding for each label). The values of hLabels show the ordering for which to fill hY with the labeled encodings. So if hLabels = 0, 2, 1, 3, 1, then Y = size { 5, 3, 1, 1 }, 5 items each with encoding sizes of 3 items which are then filled with the encoding at position 0, (for label 0), followed by the encoding for label 2, then 1, 3 and ending with the encoding for 1 as specified by the labels.
Definition at line 8179 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_fillfrom | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| DIR | dir | ||
| ) |
Fills each channel with the the values stored in Src data where the X data continains nOuterNum x nChannels of data, (e.g. one item per channel) that is then copied to all nInnerNum elements of each channel in Y
| nCount | Specifies the number of items in Y. |
| nOuterNum | Specifies the num of Y and Labels. |
| nChannels | Specifies the channel size of Y and X. |
| nInnerNum | Specifies the spatial dimension of X and Y, but is normally 1. |
| hX | Specifies the GPU memory containing the src data of shape (nOuterNum, nChannels, 1). |
| hY | Specifies the GPU memory of the output data where the X src data is copied where each item per channel is filled across all nInnerNum elements of Y. Y should have shape (nOuterNum, nChannels, nInnerNum). |
| dir | Specifies the direction of data flow. When FWD X->Y, when BWD Y->X |
Definition at line 8152 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_max | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| bool | bReturnIdx = false |
||
| ) |
Calculates the maximum value within each channel of X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| bReturnIdx | Optionally, specifies to return the index of the maximum value, otherwise the maximum value is returned. |
Definition at line 8099 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_mean | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Calculates the mean value of each channel of X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8116 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_min | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| bool | bReturnIdx = false |
||
| ) |
Calculates the minimum value within each channel of X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| bReturnIdx | Optionally, specifies to return the index of the minimum value, otherwise the minimum value is returned. |
Definition at line 8081 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_mul | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| int | nMethod = 1 |
||
| ) |
Multiplies the values of the channels from X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nMethod | Specifies the method of traversing the channel, nMethod = 1 (the default) is used by the SoftmaxLayer and nMethod = 2 is used by the GRNLayer. |
Definition at line 8272 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_mulv | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hA, | ||
| long | hX, | ||
| long | hC | ||
| ) |
Multiplies the values in vector X by each channel in matrix A and places the result in matrix C.
| nCount | Specifies the number of elements in A. |
| nOuterNum | Specifies the number of items within A. |
| nChannels | Specifies the number of channels per item of A. |
| nInnerNum | Specifies the dimension of each item in A and X. |
| hA | Specifies a handle to the matrix A in GPU memory. |
| hX | Specifies a handle to the vector X in GPU memory (must be of length nInnerDim). |
| hC | Specifies a handle to the matrix C in GPU memory where the results are placed (matrix A and C are the same shape). |
Definition at line 8290 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_op_bwd | ( | OP | op, |
| int | nCount, | ||
| int | nC, | ||
| int | nN1, | ||
| int | nSD1, | ||
| int | nN2, | ||
| int | nSD2, | ||
| int | nCy, | ||
| int | nSDy, | ||
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| long | hAd, | ||
| long | hBd, | ||
| long | hYd, | ||
| long | hWork | ||
| ) |
Performs a channel operation backward on the data.
| op | Specifies the operation to perform. |
| nCount | Specifies the number of items in Y which should equal max(nN1, nN2) x nC x max(nSD1, nSD2). |
| nC | Specifies the channels in both A, B and Y. |
| nN1 | Specifies the number of items in A. |
| nSD1 | Specifies the spatial dimension of each item of A. |
| nN2 | Specifies the number of items in B. |
| nSD2 | Specifies the spatial dimension of each item of B. |
| nCy | Specifies the channels of each item of Y. |
| nSDy | Specifies the spatial dimension of each item of Y. |
| hA | Specifies a handle to the memory of A which has the size nN1 x nC1 x nSD1. |
| hB | Specifies a handle to the memory of B which has the size nN2 x nC2 x nSD2. |
| hY | Specifies a handle to the memory where the result is placed during FWD with size max(nN1, nN2) x nC x max(nSD1, nSD2). |
| hAd | Optionally, specifies a handle to the memory of the diff for A (filled during BWD) with size nN1, nC, nSD1. |
| hBd | Optionally, specifies a handle to the memory of the diff for b (filled during BWD) with size nN2, nC, nSD2. |
| hYd | Optionally, specifies a handle to the memory of the diff for Y (used during BWD). |
| hWork | Optionally, specifies a handle to work memory with the same size as Y (used during BWD) |
Definition at line 8413 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_op_fwd | ( | OP | op, |
| int | nCount, | ||
| int | nC, | ||
| int | nN1, | ||
| int | nSD1, | ||
| int | nN2, | ||
| int | nSD2, | ||
| long | hA, | ||
| long | hB, | ||
| long | hY | ||
| ) |
Performs a channel operation forward on the data.
| op | Specifies the operation to perform. |
| nCount | Specifies the number of items in Y which should equal max(nN1, nN2) x nC x max(nSD1, nSD2). |
| nC | Specifies the channels in both A, B and Y. |
| nN1 | Specifies the number of items in A. |
| nSD1 | Specifies the spatial dimension of each item of A. |
| nN2 | Specifies the number of items in B. |
| nSD2 | Specifies the spatial dimension of each item of B. |
| hA | Specifies a handle to the memory of A which has the size nN1 x nC1 x nSD1. |
| hB | Specifies a handle to the memory of B which has the size nN2 x nC2 x nSD2. |
| hY | Specifies a handle to the memory where the result is placed during FWD with size max(nN1, nN2) x nC x max(nSD1, nSD2). |
Definition at line 8382 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_percentile | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| double | dfPercentile | ||
| ) |
Calculates the percentile along axis = 0.
| nCount | Specifies the total number of elements in Y which = count(X)*nInnerDim in length. |
| nOuterNum | Specifies the number of items. |
| nChannels | Specifies the number of channels. |
| nInnerNum | Specifies the dimension of each inner dim within the channel. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| dfPercentile | Specifies the percentile to calculate. |
Definition at line 8361 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_scale | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hA, | ||
| long | hY | ||
| ) |
Multiplies the values of the channels from X with the scalar values in B and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of items within X and B. |
| nChannels | Specifies the number of channels per item of X and B. |
| nInnerNum | Specifies the dimension of each data item in X (B should have data dimension = 1). |
| hX | Specifies a handle to the vector X in GPU memory. |
| hA | Specifies a handle to the vector B containing the scalar values, one per num * channel. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8308 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_sub | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hA, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Subtracts the values across the channels of X from A and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8197 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_sub | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Subtracts the values across the channels from X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8214 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.channel_sum | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY, | ||
| bool | bSumAcrossChannels = true, |
||
| DIR | dir = DIR.FWD, |
||
| int | nChannelsY = -1 |
||
| ) |
Calculates the sum the the values either across or within each channel (depending on bSumAcrossChannels setting) of X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of images within X. |
| nChannels | Specifies the number of channels per image of X. |
| nInnerNum | Specifies the dimension of each image in X. |
| hX | Specifies a handle to the vector X in GPU memory (with expected size nOuterNum, nChannels, nInnerNum). |
| hY | Specifies a handle to the vector Y in GPU memory (with expected size nOuterNum, nChannels, 1). |
| bSumAcrossChannels | Specifies to sum across channels (true), or within each channel (false), default = true. |
" <param name="dir">Optionally, specifies the direction (default = DIR.FWD). When DIR.BWD is used, data flows from Y to X where Y data is copied to X and duplicated across the channels of Y. When using bSumAcrossChannels = true, ordering is based on Y ordering Y(c1,c2,c3,c1,c2,c3,c1,c2,c3), and when using bSumAcrossChannels = false, ordering is based on X ordering Y(c1,c1,c1,c2,c2,c2,c3,c3,c3).</param> <param name="nChannelsY">Optionally, specifies the channels of Y (used in special case where Y channels = 1)
Definition at line 8236 of file CudaDnn.cs.
| bool MyCaffe.common.CudaDnn< T >.CheckMemoryAttributes | ( | long | hSrc, |
| int | nSrcDeviceID, | ||
| long | hDst, | ||
| int | nDstDeviceID | ||
| ) |
Check the memory attributes of two memory blocks on different devices to see if they are compatible for peer-to-peer memory transfers.
| hSrc | Specifies the handle to the source memory. |
| nSrcDeviceID | Specifies the device id where the source memory resides. |
| hDst | Specifies the handle to the destination memory. |
| nDstDeviceID | Specifies the device id where the destination memory resides. |
Definition at line 2160 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.clip_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hBottomData, | ||
| long | hBottomDiff, | ||
| T | fMin, | ||
| T | fMax | ||
| ) |
Performs a Clip backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| fMin | Specifies the bottom value to clip to. |
| fMax | Specifies the top value to clip to. |
Definition at line 8931 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.clip_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| T | fMin, | ||
| T | fMax | ||
| ) |
Performs a Clip forward pass in Cuda.
Calculation ![$ Y[i] = \max(min, \min(max,X[i])) $](form_63.png)
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| fMin | Specifies the bottom value to clip to. |
| fMax | Specifies the top value to clip to. |
Definition at line 8914 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.cll_bwd | ( | int | nCount, |
| int | nChannels, | ||
| double | dfMargin, | ||
| bool | bLegacyVersion, | ||
| double | dfAlpha, | ||
| long | hY, | ||
| long | hDiff, | ||
| long | hDistSq, | ||
| long | hBottomDiff | ||
| ) |
Performs a contrastive loss layer backward pass in Cuda.
See Dimensionality Reduction by Learning an Invariant Mapping by Hadsel, et al., 2006
| nCount | Specifies the number of items. |
| nChannels | Specifies the number of channels. |
| dfMargin | Specifies the margin to use. The default is 1.0. |
| bLegacyVersion | When false
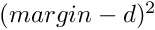 , otherwise the legacy version is used where , otherwise the legacy version is used where 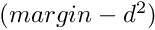 . The default is . The default is false
|
| dfAlpha | NEEDS REVIEW |
| hY | Specifies the Y data in GPU memory used to determine similar pairs. |
| hDiff | Specifies the diff in GPU memory. |
| hDistSq | Specifies the distance squared data in GPU memory. |
| hBottomDiff | Specifies the bottom diff in GPU memory. |
Definition at line 10025 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.coeff_sub_bwd | ( | int | nCount, |
| int | nDim, | ||
| int | nNumOffset, | ||
| double | dfCoeff, | ||
| long | hCoeffData, | ||
| long | hTopDiff, | ||
| long | hBottomDiff | ||
| ) |
Performs a coefficient sub backward pass in Cuda.
| nCount | Specifies the number of items. |
| nDim | Specifies the dimension of the data where the data is sized 'num' x 'dim'. |
| nNumOffset | Specifies the offset applied to the coefficent indexing. |
| dfCoeff | Specifies a primary coefficient value applied to each input before summing. |
| hCoeffData | Optionally specifies a handle to coefficient data that is applied to the primary coefficient. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 10537 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.coeff_sub_fwd | ( | int | nCount, |
| int | nDim, | ||
| int | nNumOffset, | ||
| double | dfCoeff, | ||
| long | hCoeffData, | ||
| long | hBottom, | ||
| long | hTop | ||
| ) |
Performs a coefficient sub foward pass in Cuda.
| nCount | Specifies the number of items. |
| nDim | Specifies the dimension of the data where the data is sized 'num' x 'dim'. |
| nNumOffset | Specifies the offset applied to the coefficent indexing. |
| dfCoeff | Specifies a primary coefficient value applied to each input before summing. |
| hCoeffData | Optionally specifies a handle to coefficient data that is applied to the primary coefficient. |
| hBottom | Specifies a handle to the bottom data in GPU memory. |
| hTop | Specifies a handle to the top data in GPU memory. |
Definition at line 10518 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.coeff_sum_bwd | ( | int | nCount, |
| int | nDim, | ||
| int | nNumOffset, | ||
| double | dfCoeff, | ||
| long | hCoeffData, | ||
| long | hTopDiff, | ||
| long | hBottomDiff | ||
| ) |
Performs a coefficient sum backward pass in Cuda.
| nCount | Specifies the number of items. |
| nDim | Specifies the dimension of the data where the data is sized 'num' x 'dim'. |
| nNumOffset | Specifies the offset applied to the coefficent indexing. |
| dfCoeff | Specifies a primary coefficient value applied to each input before summing. |
| hCoeffData | Optionally specifies a handle to coefficient data that is applied to the primary coefficient. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 10500 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.coeff_sum_fwd | ( | int | nCount, |
| int | nDim, | ||
| int | nNumOffset, | ||
| double | dfCoeff, | ||
| long | hCoeffData, | ||
| long | hBottom, | ||
| long | hTop | ||
| ) |
Performs a coefficient sum foward pass in Cuda.
| nCount | Specifies the number of items. |
| nDim | Specifies the dimension of the data where the data is sized 'num' x 'dim'. |
| nNumOffset | Specifies the offset applied to the coefficent indexing. |
| dfCoeff | Specifies a primary coefficient value applied to each input before summing. |
| hCoeffData | Optionally specifies a handle to coefficient data that is applied to the primary coefficient. |
| hBottom | Specifies a handle to the bottom data in GPU memory. |
| hTop | Specifies a handle to the top data in GPU memory. |
Definition at line 10481 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.col2im | ( | long | hDataCol, |
| int | nDataColOffset, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nKernelH, | ||
| int | nKernelW, | ||
| int | nPadH, | ||
| int | nPadW, | ||
| int | nStrideH, | ||
| int | nStrideW, | ||
| int | nDilationH, | ||
| int | nDilationW, | ||
| long | hDataIm, | ||
| int | nDataImOffset | ||
| ) |
Rearranges the columns into image blocks.
| hDataCol | Specifies a handle to the column data in GPU memory. |
| nDataColOffset | Specifies an offset into the column memory. |
| nChannels | Specifies the number of channels in the image. |
| nHeight | Specifies the height of the image. |
| nWidth | Specifies the width of the image. |
| nKernelH | Specifies the kernel height. |
| nKernelW | Specifies the kernel width. |
| nPadH | Specifies the pad applied to the height. |
| nPadW | Specifies the pad applied to the width. |
| nStrideH | Specifies the stride along the height. |
| nStrideW | Specifies the stride along the width. |
| nDilationH | Specifies the dilation along the height. |
| nDilationW | Specifies the dilation along the width. |
| hDataIm | Specifies a handle to the image block in GPU memory. |
| nDataImOffset | Specifies an offset into the image block memory. |
Definition at line 8039 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.col2im_nd | ( | long | hDataCol, |
| int | nDataColOffset, | ||
| int | nNumSpatialAxes, | ||
| int | nColCount, | ||
| int | nChannelAxis, | ||
| long | hImShape, | ||
| long | hColShape, | ||
| long | hKernelShape, | ||
| long | hPad, | ||
| long | hStride, | ||
| long | hDilation, | ||
| long | hDataIm, | ||
| int | nDataImOffset | ||
| ) |
Rearranges the columns into image blocks.
| hDataCol | Specifies a handle to the column data in GPU memory. |
| nDataColOffset | Specifies an offset into the column memory. |
| nNumSpatialAxes | Specifies the number of spatial axes. |
| nColCount | Specifies the number of kernels. |
| nChannelAxis | Specifies the axis containing the channel. |
| hImShape | Specifies a handle to the image shape data in GPU memory. |
| hColShape | Specifies a handle to the column shape data in GPU memory. |
| hKernelShape | Specifies a handle to the kernel shape data in GPU memory. |
| hPad | Specifies a handle to the pad data in GPU memory. |
| hStride | Specifies a handle to the stride data in GPU memory. |
| hDilation | Specifies a handle to the dilation data in GPU memory. |
| hDataIm | Specifies a handle to the image block in GPU memory. |
| nDataImOffset | Specifies an offset into the image block memory. |
Definition at line 8063 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.compare_signs | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY | ||
| ) |
Compares the signs of each value in A and B and places the result in Y.
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7653 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.concat_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| int | nNumConcats, | ||
| int | nConcatInputSize, | ||
| int | nTopConcatAxis, | ||
| int | nBottomConcatAxis, | ||
| int | nOffsetConcatAxis, | ||
| long | hBottomDiff | ||
| ) |
Performs a concat backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nNumConcats | Specifies the number of concatenations. |
| nConcatInputSize | Specifies the concatenation input size. |
| nTopConcatAxis | NEEDS REVIEW |
| nBottomConcatAxis | NEEDS REVIEW |
| nOffsetConcatAxis | NEEDS REVIEW |
| hBottomDiff | Specifies a handle to the Bottom diff in GPU memory. |
Definition at line 9869 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.concat_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| int | nNumConcats, | ||
| int | nConcatInputSize, | ||
| int | nTopConcatAxis, | ||
| int | nBottomConcatAxis, | ||
| int | nOffsetConcatAxis, | ||
| long | hTopData | ||
| ) |
Performs a concat forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| nNumConcats | Specifies the number of concatenations. |
| nConcatInputSize | Specifies the concatenation input size. |
| nTopConcatAxis | Specifies the top axis to concatenate. |
| nBottomConcatAxis | NEEDS REVIEW |
| nOffsetConcatAxis | NEEDS REVIEW |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9849 of file CudaDnn.cs.
| bool MyCaffe.common.CudaDnn< T >.contains_point | ( | int | n, |
| long | hMean, | ||
| long | hWidth, | ||
| long | hX, | ||
| long | hWork, | ||
| int | nXOff = 0 |
||
| ) |
Returns true if the point is contained within the bounds.
| n | Specifies the number of items. |
| hMean | Specifies a handle to the mean values in GPU memory. |
| hWidth | Specifies a handle to the width values in GPU memory. |
| hX | Specifies a handle to the X values in GPU memory. |
| hWork | Specifies a handle to the work data in GPU memory. |
| nXOff | Optionally, specifies an offset into the X vector (default = 0). |
Definition at line 7943 of file CudaDnn.cs.
|
static |
Converts the byte size into the number of items in the base data type of float or double.
| ulSizeInBytes | Specifies the size in bytes to convert. |
Definition at line 2438 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionBackwardBias | ( | long | hCuDnn, |
| long | hTopDesc, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| long | hBiasDesc, | ||
| long | hBiasDiff, | ||
| int | nBiasOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution backward pass on the bias.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| hBiasDesc | Specifies a handle to the bias tensor descriptor. |
| hBiasDiff | Specifies a handle to the bias diff in GPU memory. |
| nBiasOffset | Specifies an offset into the diff memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3901 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionBackwardBias | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hTopDesc, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| T | fBeta, | ||
| long | hBiasDesc, | ||
| long | hBiasDiff, | ||
| int | nBiasOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution backward pass on the bias.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBiasDesc | Specifies a handle to the bias tensor descriptor. |
| hBiasDiff | Specifies a handle to the bias diff in GPU memory. |
| nBiasOffset | Specifies an offset into the diff memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3919 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionBackwardData | ( | long | hCuDnn, |
| long | hFilterDesc, | ||
| long | hWeight, | ||
| int | nWeightOffset, | ||
| long | hTopDesc, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| long | hConvDesc, | ||
| CONV_BWD_DATA_ALGO | algoBwd, | ||
| long | hWorkspace, | ||
| int | nWorkspaceOffset, | ||
| ulong | lWorkspaceSize, | ||
| long | hBottomDesc, | ||
| long | hBottomDiff, | ||
| int | nBottomOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution backward pass on the data.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hWeight | Specifies a handle to the weight data in GPU memory. |
| nWeightOffset | Specifies an offset into the weight memory (in items, not bytes). |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| algoBwd | Specifies the algorithm to use when performing the backward operation. |
| hWorkspace | Specifies a handle to the GPU memory to use for the workspace. |
| nWorkspaceOffset | Specifies an offset into the workspace memory. |
| lWorkspaceSize | Specifies the size of the workspace memory (in bytes). |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| nBottomOffset | Specifies an offset into the bottom memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3999 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionBackwardData | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hFilterDesc, | ||
| long | hWeight, | ||
| int | nWeightOffset, | ||
| long | hTopDesc, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| long | hConvDesc, | ||
| CONV_BWD_DATA_ALGO | algoBwd, | ||
| long | hWorkspace, | ||
| int | nWorkspaceOffset, | ||
| ulong | lWorkspaceSize, | ||
| T | fBeta, | ||
| long | hBottomDesc, | ||
| long | hBottomDiff, | ||
| int | nBottomOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution backward pass on the data.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hWeight | Specifies a handle to the weight data in GPU memory. |
| nWeightOffset | Specifies an offset into the weight memory (in items, not bytes). |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| algoBwd | Specifies the algorithm to use when performing the backward operation. |
| hWorkspace | Specifies a handle to the GPU memory to use for the workspace. |
| nWorkspaceOffset | Specifies an offset into the workspace memory. |
| lWorkspaceSize | Specifies the size of the workspace memory (in bytes). |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| nBottomOffset | Specifies an offset into the bottom memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 4025 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionBackwardFilter | ( | long | hCuDnn, |
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| int | nBottomOffset, | ||
| long | hTopDesc, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| long | hConvDesc, | ||
| CONV_BWD_FILTER_ALGO | algoBwd, | ||
| long | hWorkspace, | ||
| int | nWorkspaceOffset, | ||
| ulong | lWorkspaceSize, | ||
| long | hFilterDesc, | ||
| long | hWeightDiff, | ||
| int | nWeightOffset, | ||
| bool | bSyncStream | ||
| ) |
Perform a convolution backward pass on the filter.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| nBottomOffset | Specifies an offset into the bottom memory (in items, not bytes). |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| algoBwd | Specifies the algorithm to use when performing the backward operation. |
| hWorkspace | Specifies a handle to the GPU memory to use for the workspace. |
| nWorkspaceOffset | Specifies an offset into the workspace memory. |
| lWorkspaceSize | Specifies the size of the workspace memory (in bytes). |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hWeightDiff | Specifies a handle to the weight diff in GPU memory. |
| nWeightOffset | Specifies an offset into the weight memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3946 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionBackwardFilter | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| int | nBottomOffset, | ||
| long | hTopDesc, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| long | hConvDesc, | ||
| CONV_BWD_FILTER_ALGO | algoBwd, | ||
| long | hWorkspace, | ||
| int | nWorkspaceOffset, | ||
| ulong | lWorkspaceSize, | ||
| T | fBeta, | ||
| long | hFilterDesc, | ||
| long | hWeightDiff, | ||
| int | nWeightOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution backward pass on the filter.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| nBottomOffset | Specifies an offset into the bottom memory (in items, not bytes). |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| algoBwd | Specifies the algorithm to use when performing the backward operation. |
| hWorkspace | Specifies a handle to the GPU memory to use for the workspace. |
| nWorkspaceOffset | Specifies an offset into the workspace memory. |
| lWorkspaceSize | Specifies the size of the workspace memory (in bytes). |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hWeightDiff | Specifies a handle to the weight diff in GPU memory. |
| nWeightOffset | Specifies an offset into the weight memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3972 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionForward | ( | long | hCuDnn, |
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| int | nBottomOffset, | ||
| long | hFilterDesc, | ||
| long | hWeight, | ||
| int | nWeightOffset, | ||
| long | hConvDesc, | ||
| CONV_FWD_ALGO | algoFwd, | ||
| long | hWorkspace, | ||
| int | nWorkspaceOffset, | ||
| ulong | lWorkspaceSize, | ||
| long | hTopDesc, | ||
| long | hTopData, | ||
| int | nTopOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| nBottomOffset | Specifies an offset into the bottom memory (in items, not bytes). |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hWeight | Specifies a handle to the weight data in GPU memory. |
| nWeightOffset | Specifies an offset into the weight memory (in items, not bytes). |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| algoFwd | Specifies the algorithm to use for the foward operation. |
| hWorkspace | Specifies a handle to the GPU memory to use for the workspace. |
| nWorkspaceOffset | Specifies an offset into the workspace memory. |
| lWorkspaceSize | Specifies the size of the workspace memory (in bytes). |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3856 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ConvolutionForward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| int | nBottomOffset, | ||
| long | hFilterDesc, | ||
| long | hWeight, | ||
| int | nWeightOffset, | ||
| long | hConvDesc, | ||
| CONV_FWD_ALGO | algoFwd, | ||
| long | hWorkspace, | ||
| int | nWorkspaceOffset, | ||
| ulong | lWorkspaceSize, | ||
| T | fBeta, | ||
| long | hTopDesc, | ||
| long | hTopData, | ||
| int | nTopOffset, | ||
| bool | bSyncStream = true |
||
| ) |
Perform a convolution forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| nBottomOffset | Specifies an offset into the bottom memory (in items, not bytes). |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hWeight | Specifies a handle to the weight data in GPU memory. |
| nWeightOffset | Specifies an offset into the weight memory (in items, not bytes). |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| algoFwd | Specifies the algorithm to use for the foward operation. |
| hWorkspace | Specifies a handle to the GPU memory to use for the workspace. |
| nWorkspaceOffset | Specifies an offset into the workspace memory. |
| lWorkspaceSize | Specifies the size of the workspace memory (in bytes). |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| nTopOffset | Specifies an offset into the top memory (in items, not bytes). |
| bSyncStream | Optionally, specifies whether or not to syncrhonize the stream. The default = true. |
Definition at line 3882 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.copy | ( | int | nCount, |
| int | nNum, | ||
| int | nDim, | ||
| long | hSrc1, | ||
| long | hSrc2, | ||
| long | hDst, | ||
| long | hSimilar, | ||
| bool | bInvert = false |
||
| ) |
Copy similar items of length 'nDim' from hSrc1 (where hSimilar(i) = 1) and dissimilar items of length 'nDim' from hSrc2 (where hSimilar(i) = 0).
| nCount | Specifies the total data length of hSrc1, hSrc2 and hDst. |
| nNum | Specifis the number of outer items in hSrc1, hSrc2, hDst, and the number of elements in hSimilar. |
| nDim | Specifies the inner dimension of hSrc1, hSrc2 and hDst. |
| hSrc1 | Specifies a handle to the GPU memory of source 1. |
| hSrc2 | Specifies a handle to the GPU memory of source 2. |
| hDst | Specifies a handle to the GPU memory of the destination. |
| hSimilar | Specifies a handle to the GPU memory of the similar data. |
| bInvert | Optionally, specifies whether or not to invert the similar values (e.g. copy when similar = 0 instead of similar = 1) |
Definition at line 6035 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.copy | ( | int | nCount, |
| long | hSrc, | ||
| long | hDst, | ||
| int | nSrcOffset = 0, |
||
| int | nDstOffset = 0, |
||
| long | hStream = -1, |
||
| bool? | bSrcHalfSizeOverride = null, |
||
| bool? | bDstHalfSizeOverride = null |
||
| ) |
Copy data from one block of GPU memory to another.
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| nCount | Specifies the number of items (not bytes) to copy. |
| hSrc | Specifies a handle to GPU memory containing the source data. |
| hDst | Specifies a handle to GPU memory containing the destination data. |
| nSrcOffset | Optionally specifies the offset into the source data where the copying starts. |
| nDstOffset | Optionally specifies the offset into the destination data where the copying starts. |
| hStream | Optionally, specifies a handle to a stream to use for the operation. |
| bSrcHalfSizeOverride | Optionally, specifies and override for the half size state of the source (default = null, which is ignored). |
| bDstHalfSizeOverride | Optionally, specifies and override for the half size state of the destination (default = null, which is ignored). |
Definition at line 6007 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.copy_batch | ( | int | nCount, |
| int | nNum, | ||
| int | nDim, | ||
| long | hSrcData, | ||
| long | hSrcLbl, | ||
| int | nDstCount, | ||
| long | hDstCache, | ||
| long | hWorkDevData, | ||
| int | nLabelStart, | ||
| int | nLabelCount, | ||
| int | nCacheSize, | ||
| long | hCacheHostCursors, | ||
| long | hWorkDataHost | ||
| ) |
Copy a batch of labeled items into a cache organized by label where older data is removed and replaced by newer data.
| nCount | Specifies the total data length of hSrc. |
| nNum | Specifis the number of outer items in hSrc1, hSrc2, hDst, and the number of elements in hSimilar. |
| nDim | Specifies the inner dimension of hSrc1, hSrc2 and hDst. |
| hSrcData | Specifies a handle to the GPU memory of source data. |
| hSrcLbl | Specifies a handle to the GPU memory of source labels. |
| nDstCount | Specifies the total data length of the hDstCache |
| hDstCache | Specifies a handle to the GPU memory of the destination cache. |
| hWorkDevData | Specifies a handle to the GPU memory of the device work data that is the same size as the hDstCache. |
| nLabelStart | Specifies the first label of all possible labels. |
| nLabelCount | Specifies the total number of labels (expects labels to be sequential from 'nLabelStart'). |
| nCacheSize | Specifies the size of each labeled data cache. |
| hCacheHostCursors | Specifies a handle to host memmory (allocated using AllocateHostBuffer) containing the label cursors - there should be 'nLabelCount' cursors. |
| hWorkDataHost | Specifies a handle to host memory (allocated using AllocateHostBuffer) used for work - must be nNum in item length. |
NOTE: The cache size must be set at a sufficient size that covers the maximum number items for any given label within a batch, otherwise cached items will be overwritten for items in the current batch.
Definition at line 6062 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.copy_expand | ( | int | n, |
| int | nNum, | ||
| int | nDim, | ||
| long | hX, | ||
| long | hA | ||
| ) |
Expand a vector of length 'nNum' into a matrix of size 'nNum' x 'nDim' by copying each value of the vector into all elements of the corresponding matrix row.
| n | Specifies the total number of items in the matrix 'A' |
| nNum | Specifies the total number of rows in the matrix 'A' and the total number of items in the vector 'X'. |
| nDim | Specifies the total number of columns in the matrix 'A'. |
| hX | Specifies the 'nNum' length vector to expand. |
| hA | Specifies the 'nNum' x 'nDim' matrix. |
Definition at line 6182 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.copy_sequence | ( | int | n, |
| long | hSrc, | ||
| int | nSrcStep, | ||
| int | nSrcStartIdx, | ||
| int | nCopyCount, | ||
| int | nCopyDim, | ||
| long | hDst, | ||
| int | nDstStep, | ||
| int | nDstStartIdx, | ||
| int | nSrcSpatialDim, | ||
| int | nDstSpatialDim, | ||
| int | nSrcSpatialDimStartIdx = 0, |
||
| int | nDstSpatialDimStartIdx = 0, |
||
| int | nSpatialDimCount = -1 |
||
| ) |
Copy a sequence from a source to a destination and allow for skip steps.
| n | Specifies the total number of items in src. |
| hSrc | Specifies a handle to the source GPU memory. |
| nSrcStep | Specifies the stepping used across the source. |
| nSrcStartIdx | Specifies the starting index into the source. |
| nCopyCount | Specifies the number of items to copy. |
| nCopyDim | Specifies the dimension to copy (which x spatial dim = total copy amount). |
| hDst | Specifies a handle to the destination GPU memory. |
| nDstStep | Specifies the steping used across the desination. |
| nDstStartIdx | Specifies the starting index where data is to be copied in the destination. |
| nSrcSpatialDim | Specifies the src spatial dim of each item copied. Src and Dst spatial dims should be equal when nSpatialDimCount is not used. |
| nDstSpatialDim | Specifies the dst spatial dim of each item copied. Src and Dst spatial dims should be equal when nSpatialDimCount is not used. |
| nSrcSpatialDimStartIdx | Optionally, specifies the start index within the source spatial dim to start the copy (default = 0) |
| nDstSpatialDimStartIdx | Optionally, specifies the start index within the destination spatial dim to start the copy (default = 0) |
| nSpatialDimCount | Optionally, specifies the number of items to copy from within the spatial dim (default = -1, copy all) |
Definition at line 6165 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.copy_sequence | ( | int | nK, |
| int | nNum, | ||
| int | nDim, | ||
| long | hSrcData, | ||
| long | hSrcLbl, | ||
| int | nSrcCacheCount, | ||
| long | hSrcCache, | ||
| int | nLabelStart, | ||
| int | nLabelCount, | ||
| int | nCacheSize, | ||
| long | hCacheHostCursors, | ||
| bool | bOutputLabels, | ||
| List< long > | rghTop, | ||
| List< int > | rgnTopCount, | ||
| long | hWorkDataHost, | ||
| bool | bCombinePositiveAndNegative = false, |
||
| int | nSeed = 0 |
||
| ) |
Copy a sequence of cached items, organized by label, into an anchor, positive (if nK > 0), and negative blobs.
| nK | Specifies the output type expected where: nK = 0, outputs to 2 tops (anchor and one negative), or nK > 0, outputs to 2 + nK tops (anchor, positive, nK negatives). The rghTop and rgnTopCount must be sized accordingly. |
| nNum | Specifis the number of outer items in hSrc1, hSrc2, hDst, and the number of elements in hSimilar. |
| nDim | Specifies the inner dimension of hSrc1, hSrc2 and hDst. |
| hSrcData | Specifies a handle to the GPU memory of source data. |
| hSrcLbl | Specifies a handle to the GPU memory of source labels. |
| nSrcCacheCount | Specifis the number of items in hSrcCache (nCacheSize * nLabelCount). |
| hSrcCache | Specifies a handle to the cached labeled data. |
| nLabelStart | Specifies the first label of all possible labels. |
| nLabelCount | Specifies the total number of labels (expects labels to be sequential from 'nLabelStart'). |
| nCacheSize | Specifies the size of each labeled data cache. |
| hCacheHostCursors | Specifies a handle to host memmory containing the label cursors - there should be 'nLabelCount' cursors. |
| bOutputLabels | Specifies whether or not to output labels or not. When true, one additional top is expected for the labels. |
| rghTop | Specifies a list of the GPU memory for each top item. The number of top items expected depends on the 'nK' value. |
| rgnTopCount | Specifies a list of the item count for each top item. The number of top items expected depends on the 'nK' value. |
| hWorkDataHost | Specifies a handle to host memory (allocated using AllocateHostBuffer) used for work - must be nNum in item length and must be the same hWorkDataHost passed to 'copy_batch'. |
| bCombinePositiveAndNegative | Optionally, specifies to combine the positive and negative items by alternating between each and placing both in Top[1], while also making sure the output labels reflect the alternation. |
| nSeed | Optionally, specifies a seed for the random number generator (default = 0, which igores this parameter). |
Receiving an error ERROR_BATCH_TOO_SMALL indicates that the batch size is too small and does not have enough labels to choose from. Each batch should have at least two instances of each labeled item.
NOTE: When 'nK' = 1 and 'bCombinePositiveAndNegative' = true, the label output has a dimension of 2, and and the tops used are as follows: top(0) = anchor; top(1) = alternating negative/positive, top(2) = labels if 'bOutputLabels' = true.
Definition at line 6095 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.CopyDeviceToHost | ( | long | lCount, |
| long | hGpuSrc, | ||
| long | hHostDst | ||
| ) |
Copy from GPU memory to Host memory.
| lCount | Specifies the number of items (of base type each) to copy. |
| hGpuSrc | Specifies the GPU memory containing the source data. |
| hHostDst | Specifies the Host memory containing the host destination. |
Definition at line 2554 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.CopyHostToDevice | ( | long | lCount, |
| long | hHostSrc, | ||
| long | hGpuDst | ||
| ) |
Copy from Host memory to GPU memory.
| lCount | Specifies the number of items (of base type each) to copy. |
| hHostSrc | Specifies the Host memory containing the host source data. |
| hGpuDst | Specifies the GPU memory containing the destination. |
Definition at line 2568 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateConvolutionDesc | ( | ) |
Create a new instance of a convolution descriptor for use with NVIDIA's cuDnn.
Definition at line 3747 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateCuDNN | ( | long | hStream = 0 | ) |
Create a new instance of NVIDIA's cuDnn.
| hStream | Specifies a stream used by cuDnn. |
Definition at line 3263 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateDropoutDesc | ( | ) |
Create a new instance of a dropout descriptor for use with NVIDIA's cuDnn.
Definition at line 4203 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateExtension | ( | string | strExtensionDllPath | ) |
Create an instance of an Extension DLL.
| strExtensionDllPath | Specifies the file path to the extension DLL. |
Definition at line 3456 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateFilterDesc | ( | ) |
Create a new instance of a filter descriptor for use with NVIDIA's cuDnn.
Definition at line 3668 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateImageOp | ( | int | nNum, |
| double | dfBrightnessProb, | ||
| double | dfBrightnessDelta, | ||
| double | dfContrastProb, | ||
| double | dfContrastLower, | ||
| double | dfContrastUpper, | ||
| double | dfSaturationProb, | ||
| double | dfSaturationLower, | ||
| double | dfSaturationUpper, | ||
| long | lRandomSeed = 0 |
||
| ) |
Create a new ImageOp used to perform image operations on the GPU.
| nNum | Specifies the number of items (usually the blob.num). |
| dfBrightnessProb | Specifies the brightness probability [0,1]. |
| dfBrightnessDelta | Specifies the brightness delta. |
| dfContrastProb | Specifies the contrast probability [0,1] |
| dfContrastLower | Specifies the contrast lower bound value. |
| dfContrastUpper | Specifies the contrast upper bound value. |
| dfSaturationProb | Specifies the saturation probability [0,1] |
| dfSaturationLower | Specifies the saturation lower bound value. |
| dfSaturationUpper | Specifies the saturation upper bound value. |
| lRandomSeed | Optionally, specifies the random seed or 0 to ignore (default = 0). |
Definition at line 3153 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateLayerNorm | ( | int | nGpuID, |
| int | nCount, | ||
| int | nOuterNum, | ||
| int | nChannels, | ||
| int | nInnerNum, | ||
| float | fEps = 1e-10f |
||
| ) |
Create the Cuda version of LayerNorm
| nGpuID | Specifies the GPUID to use. |
| nCount | Specifies the total number of items in the input (and output). |
| nOuterNum | Specifies the outer number of items (e.g., num) |
| nChannels | Specifies the number of channels in the data. |
| nInnerNum | Specifies the spatial dimentions of the inner data. |
| fEps | Optionally, specifies the epsilon value to avoid numeric issues (default = 1e-10). |
Definition at line 5828 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateLRNDesc | ( | ) |
Create a new instance of a LRN descriptor for use with NVIDIA's cuDnn.
Definition at line 4308 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateMemoryPointer | ( | long | hData, |
| long | lOffset, | ||
| long | lCount | ||
| ) |
Creates a memory pointer into an already existing block of GPU memory.
| hData | Specifies a handle to the GPU memory. |
| lOffset | Specifies the offset into the GPU memory (in items, not bytes), where the pointer is to start. |
| lCount | Specifies the number of items (not bytes) in the 'virtual' memory block pointed to by the memory pointer. |
Definition at line 3028 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateMemoryTest | ( | out ulong | ulTotalNumBlocks, |
| out double | dfMemAllocatedInGB, | ||
| out ulong | ulMemStartAddr, | ||
| out ulong | ulBlockSize, | ||
| double | dfPctToAllocate = 1.0 |
||
| ) |
Creates a new memory test on the current GPU.
| ulTotalNumBlocks | Returns the total number of blocks available to test. |
| dfMemAllocatedInGB | Returns the total amount of allocated memory, specified in GB. |
| ulMemStartAddr | Returns the start address of the memory test. |
| ulBlockSize | Returns the block size of the memory to be tested. |
| dfPctToAllocate | Specifies the percentage of avaiable memory to test, where 1.0 = 100%. |
Definition at line 3069 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateNCCL | ( | int | nDeviceId, |
| int | nCount, | ||
| int | nRank, | ||
| Guid | guid | ||
| ) |
Create an instance of NVIDIA's NCCL 'Nickel'
| nDeviceId | Specifies the device where this instance of NCCL is going to run. |
| nCount | Specifies the total number of NCCL instances used. |
| nRank | Specifies the zero-based rank of this instance of NCCL. |
| guid | Specifies the unique Guid for this isntance of NCCL. |
Definition at line 3297 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreatePCA | ( | int | nMaxIterations, |
| int | nM, | ||
| int | nN, | ||
| int | nK, | ||
| long | hData, | ||
| long | hScoresResult, | ||
| long | hLoadsResult, | ||
| long | hResiduals = 0, |
||
| long | hEigenvalues = 0 |
||
| ) |
Creates a new PCA instance and returns the handle to it.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| nMaxIterations | Specifies the number of iterations to run. |
| nM | Specifies the data width (number of rows). |
| nN | Specifies the data height (number of columns). |
| nK | Specifies the number of components (K less than or equal to N). |
| hData | Specifies a handle to the data allocated using AllocatePCAData. |
| hScoresResult | Specifies a handle to the data allocated using AllocatePCAScores. |
| hLoadsResult | Specifies a handle to the data allocated using AllocatePCALoads. |
| hResiduals | Specifies a handle to the data allocated using AllocatePCAData. |
| hEigenvalues | Specifies a handle to the data allocated using AllocatePCAEigenvalues. |
Definition at line 5392 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreatePoolingDesc | ( | ) |
Create a new instance of a pooling descriptor for use with NVIDIA's cuDnn.
Definition at line 4037 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateRnn8 | ( | ) |
Create the RNN8.
Definition at line 5160 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateRnnDataDesc | ( | ) |
Create the RNN Data Descriptor.
Definition at line 4652 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateRnnDesc | ( | ) |
Create the RNN Descriptor.
Definition at line 4733 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateSSD | ( | int | nNumClasses, |
| bool | bShareLocation, | ||
| int | nLocClasses, | ||
| int | nBackgroundLabelId, | ||
| bool | bUseDiffcultGt, | ||
| SSD_MINING_TYPE | miningType, | ||
| SSD_MATCH_TYPE | matchType, | ||
| float | fOverlapThreshold, | ||
| bool | bUsePriorForMatching, | ||
| SSD_CODE_TYPE | codeType, | ||
| bool | bEncodeVariantInTgt, | ||
| bool | bBpInside, | ||
| bool | bIgnoreCrossBoundaryBbox, | ||
| bool | bUsePriorForNms, | ||
| SSD_CONF_LOSS_TYPE | confLossType, | ||
| SSD_LOC_LOSS_TYPE | locLossType, | ||
| float | fNegPosRatio, | ||
| float | fNegOverlap, | ||
| int | nSampleSize, | ||
| bool | bMapObjectToAgnostic, | ||
| bool | bNmsParam, | ||
| float? | fNmsThreshold = null, |
||
| int? | nNmsTopK = null, |
||
| float? | fNmsEta = null |
||
| ) |
Create an instance of the SSD GPU support.
| nNumClasses | Specifies the number of classes. |
| bShareLocation | Specifies whether or not to share the location. |
| nLocClasses | Specifies the number of location classes. |
| nBackgroundLabelId | Specifies the background label ID. |
| bUseDiffcultGt | Specifies whether or not to use difficult ground truths. |
| miningType | Specifies the mining type to use. |
| matchType | Specifies the matching method to use. |
| fOverlapThreshold | Specifies the overlap threshold for each box. |
| bUsePriorForMatching | Specifies whether or not to use priors for matching. |
| codeType | Specifies the code type to use. |
| bEncodeVariantInTgt | Specifies whether or not to encode the variant in the target. |
| bBpInside | Specifies whether or not the BP is inside or not. |
| bIgnoreCrossBoundaryBbox | Specifies whether or not to ignore cross boundary boxes. |
| bUsePriorForNms | Specifies whether or not to use priors for NMS. |
| confLossType | Specifies the confidence loss type. |
| locLossType | Specifies the location loss type. |
| fNegPosRatio | Specifies the negative/positive ratio to use. |
| fNegOverlap | Specifies the negative overlap to use. |
| nSampleSize | Specifies the sample size. |
| bMapObjectToAgnostic | Specifies whether or not to map objects to agnostic or not. |
| bNmsParam | Specifies whether or not the NMS parameters are specified. |
| fNmsThreshold | Specifies the NMS threshold, which is only used when the 'bNmsParam' = true. |
| nNmsTopK | Specifies the NMS top-k selection, which is only used when the 'bNmsParam' = true. |
| fNmsEta | Specifies the NMS eta, which is only used when the 'bNmsParam' = true. |
Definition at line 5482 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateStream | ( | bool | bNonBlocking = false, |
| int | nIndex = -1 |
||
| ) |
Create a new stream on the current GPU.
| bNonBlocking | When false
|
| nIndex | Specifies an index for the stream where indexed streams are shared when the index = 0 or greater. |
Definition at line 3209 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.CreateTensorDesc | ( | ) |
Create a new instance of a tensor descriptor for use with NVIDIA's cuDnn.
Definition at line 3518 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.crop_bwd | ( | int | nCount, |
| int | nNumAxes, | ||
| long | hSrcStrides, | ||
| long | hDstStrides, | ||
| long | hOffsets, | ||
| long | hBottomDiff, | ||
| long | hTopDiff | ||
| ) |
Performs the crop backward operation.
| nCount | Specifies the count. |
| nNumAxes | Specifies the number of axes in the bottom. |
| hSrcStrides | Specifies a handle to the GPU memory containing the source strides. |
| hDstStrides | Specifies a handle to the GPU memory containing the destination strides. |
| hOffsets | Specifies a handle to the GPU memory containing the offsets. |
| hBottomDiff | Specifies a handle to the bottom data in GPU memory. |
| hTopDiff | Specifies a handle to the top data in GPU memory. |
Definition at line 9830 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.crop_fwd | ( | int | nCount, |
| int | nNumAxes, | ||
| long | hSrcStrides, | ||
| long | hDstStrides, | ||
| long | hOffsets, | ||
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs the crop forward operation.
| nCount | Specifies the count. |
| nNumAxes | Specifies the number of axes in the bottom. |
| hSrcStrides | Specifies a handle to the GPU memory containing the source strides. |
| hDstStrides | Specifies a handle to the GPU memory containing the destination strides. |
| hOffsets | Specifies a handle to the GPU memory containing the offsets. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9812 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.debug | ( | ) |
The debug function is uses only during debugging the debug version of the low-level DLL.
Definition at line 10637 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.denan | ( | int | n, |
| long | hX, | ||
| double | dfReplacement | ||
| ) |
Replaces all NAN values witin X with a replacement value.
| n | Specifies the number of items (not bytes) in the vector X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| dfReplacement | Specifies the replacement value. |
Definition at line 7963 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DeriveBatchNormDesc | ( | long | hFwdScaleBiasMeanVarDesc, |
| long | hFwdBottomDesc, | ||
| long | hBwdScaleBiasMeanVarDesc, | ||
| long | hBwdBottomDesc, | ||
| BATCHNORM_MODE | mode | ||
| ) |
Derive the batch norm descriptors for both the forward and backward passes.
| hFwdScaleBiasMeanVarDesc | Specifies a handle to the scale bias mean var tensor descriptor for the forward pass. |
| hFwdBottomDesc | Specifies a handle to the forward bottom tensor descriptor. |
| hBwdScaleBiasMeanVarDesc | Specifies a handle to the scale bias mean var tensor descriptor for the backward pass. |
| hBwdBottomDesc | Specifies a handle to the backward bottom tensor descriptor. |
| mode |
Definition at line 4132 of file CudaDnn.cs.
| bool MyCaffe.common.CudaDnn< T >.DeviceCanAccessPeer | ( | int | nSrcDeviceID, |
| int | nPeerDeviceID | ||
| ) |
Query whether or not two devices can access each other via peer-to-peer memory copies.
| nSrcDeviceID | Specifies the device id of the source. |
| nPeerDeviceID | Specifies the device id of the peer to the source device. |
Definition at line 2240 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DeviceDisablePeerAccess | ( | int | nPeerDeviceID | ) |
Disables peer-to-peer access between the current device used by the CudaDnn instance and a peer device.
| nPeerDeviceID | Specifies the device id of the peer device. |
Definition at line 2270 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DeviceEnablePeerAccess | ( | int | nPeerDeviceID | ) |
Enables peer-to-peer access between the current device used by the CudaDnn instance and a peer device.
| nPeerDeviceID | Specifies the device id of the peer device. |
Definition at line 2258 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DisableGhostMemory | ( | ) |
Disables the ghost memory, if enabled.
Definition at line 1775 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.Dispose | ( | ) |
Disposes this instance freeing up all of its host and GPU memory.
Definition at line 1629 of file CudaDnn.cs.
|
protectedvirtual |
Disposes this instance freeing up all of its host and GPU memory.
| bDisposing | When true, specifies that the call is from a Dispose call. |
Definition at line 1612 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DistortImage | ( | long | h, |
| int | nCount, | ||
| int | nNum, | ||
| int | nDim, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Distort an image using the ImageOp handle provided.
| h | Specifies a handle to the ImageOp that defines how the image will be distorted. |
| nCount | Specifies the total number of data elements within 'hX' and 'hY'. |
| nNum | Specifies the number of items to be distorted (typically blob.num) in 'hX' and 'hY'. |
| nDim | Specifies the dimension of each item. |
| hX | Specifies a handle to the GPU memory containing the source data to be distorted. |
| hY | Specifies a handle to the GPU memory containing the destination of the distortion. |
Definition at line 3188 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.div | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY | ||
| ) |
Divides each element of A by each element of B and places the result in Y.
Y = A / B (element by element)
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7420 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.divbsx | ( | int | n, |
| long | hA, | ||
| int | nAOff, | ||
| long | hX, | ||
| int | nXOff, | ||
| int | nC, | ||
| int | nSpatialDim, | ||
| bool | bTranspose, | ||
| long | hB, | ||
| int | nBOff | ||
| ) |
Divide a matrix by a vector.
| n | Specifies the number of items. |
| hA | Specifies the matrix to divide. |
| nAOff | Specifies the offset to apply to the GPU memory of hA. |
| hX | Specifies the divisor vector. |
| nXOff | Specifies the offset to apply to the GPU memory of hX. |
| nC | Specifies the number of channels. |
| nSpatialDim | Specifies the spatial dimension. |
| bTranspose | Specifies whether or not to transpose the matrix. |
| hB | Specifies the output matrix. |
| nBOff | Specifies the offset to apply to the GPU memory of hB. |
Definition at line 6671 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DivisiveNormalizationBackward | ( | long | hCuDnn, |
| long | hNormDesc, | ||
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| long | hTopDiff, | ||
| long | hTemp1, | ||
| long | hTemp2, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Performs a Devisive Normalization backward pass.
See What is the Best Feature Learning Procedure in Hierarchical Recognition Architectures? by Jarrett, et al.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hNormDesc | Specifies a handle to an LRN descriptor. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTemp1 | Temporary data in GPU memory. |
| hTemp2 | Temporary data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4433 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DivisiveNormalizationForward | ( | long | hCuDnn, |
| long | hNormDesc, | ||
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| long | hTemp1, | ||
| long | hTemp2, | ||
| T | fBeta, | ||
| long | hTopDataDesc, | ||
| long | hTopData | ||
| ) |
Performs a Devisive Normalization forward pass.
See What is the Best Feature Learning Procedure in Hierarchical Recognition Architectures? by Jarrett, et al.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hNormDesc | Specifies a handle to an LRN descriptor. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTemp1 | Temporary data in GPU memory. |
| hTemp2 | Temporary data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4408 of file CudaDnn.cs.
| T MyCaffe.common.CudaDnn< T >.dot | ( | int | n, |
| long | hX, | ||
| long | hY, | ||
| int | nXOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Computes the dot product of X and Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nXOff | Optionally, specifies an offset (in items, not bytes) into the memory of X. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 6847 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.dot_double | ( | int | n, |
| long | hX, | ||
| long | hY | ||
| ) |
Computes the dot product of X and Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6815 of file CudaDnn.cs.
| float MyCaffe.common.CudaDnn< T >.dot_float | ( | int | n, |
| long | hX, | ||
| long | hY | ||
| ) |
Computes the dot product of X and Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6830 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.dropout_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hMask, | ||
| uint | uiThreshold, | ||
| T | fScale, | ||
| long | hBottomDiff | ||
| ) |
Performs a dropout backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU memory. |
| uiThreshold | Specifies the threshold value: when mask value are less than the threshold, the data item is 'dropped out' by setting the data item to zero. |
| fScale | Specifies a scale value applied to each item that is not dropped out. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 9484 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.dropout_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hMask, | ||
| uint | uiThreshold, | ||
| T | fScale, | ||
| long | hTopData | ||
| ) |
Performs a dropout forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU memory. |
| uiThreshold | Specifies the threshold value: when mask value are less than the threshold, the data item is 'dropped out' by setting the data item to zero. |
| fScale | Specifies a scale value applied to each item that is not dropped out. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9464 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DropoutBackward | ( | long | hCuDnn, |
| long | hDropoutDesc, | ||
| long | hTopDesc, | ||
| long | hTop, | ||
| long | hBottomDesc, | ||
| long | hBottom, | ||
| long | hReserved | ||
| ) |
Performs a dropout backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hDropoutDesc | Specifies a handle to the dropout descriptor. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTop | Specifies a handle to the top data in GPU memory. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottom | Specifies a handle to the bottom data in GPU memory. |
| hReserved | Specifies a handle to the reseved data in GPU memory. |
Definition at line 4296 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.DropoutForward | ( | long | hCuDnn, |
| long | hDropoutDesc, | ||
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| long | hTopDesc, | ||
| long | hTopData, | ||
| long | hReserved | ||
| ) |
Performs a dropout forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hDropoutDesc | Specifies a handle to the dropout descriptor. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hReserved | Specifies a handle to the reseved data in GPU memory. |
Definition at line 4278 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.elu_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomData, | ||
| long | hBottomDiff, | ||
| double | dfAlpha | ||
| ) |
Performs a Exponential Linear Unit (ELU) backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| dfAlpha | Specifies the alpha value. |
Definition at line 9444 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.elu_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| double | dfAlpha | ||
| ) |
Performs a Exponential Linear Unit (ELU) forward pass in Cuda.
Calculates 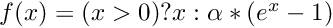
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| dfAlpha | Specifies the alpha value. |
Definition at line 9424 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.EluBackward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform a Elu backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4513 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.EluForward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDataDesc, | ||
| long | hTopData | ||
| ) |
Perform a Elu forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4491 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.embed_bwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopDiff, | ||
| int | nM, | ||
| int | nN, | ||
| int | nK, | ||
| long | hWeightDiff | ||
| ) |
Performs the backward pass for embed
| nCount | Specifies the number of items in the bottom data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nM | NEEDS REVIEW |
| nN | NEEDS REVIEW |
| nK | NEEDS REVIEW |
| hWeightDiff | Specifies a handle to the weight diff in GPU memory. |
Definition at line 8781 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.embed_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hWeight, | ||
| int | nM, | ||
| int | nN, | ||
| int | nK, | ||
| long | hTopData | ||
| ) |
Performs the forward pass for embed
| nCount | Specifies the number of items in the bottom data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hWeight | Specifies a handle to the weight data in GPU memory. |
| nM | NEEDS REVIEW |
| nN | NEEDS REVIEW |
| nK | NEEDS REVIEW |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 8763 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.erf | ( | double | dfVal | ) |
Calculates the erf() function.
| dfVal | Specifies the input value. |
Definition at line 6986 of file CudaDnn.cs.
| float MyCaffe.common.CudaDnn< T >.erf | ( | float | fVal | ) |
Calculates the erf() function.
| fVal | Specifies the input value. |
Definition at line 6996 of file CudaDnn.cs.
| T MyCaffe.common.CudaDnn< T >.erf | ( | T | fVal | ) |
Calculates the erf() function.
| fVal | Specifies the input value. |
Definition at line 7006 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.exp | ( | int | n, |
| long | hA, | ||
| long | hY | ||
| ) |
Calculates the exponent value of A and places the result in Y.
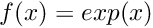
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7454 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.exp | ( | int | n, |
| long | hA, | ||
| long | hY, | ||
| int | nAOff, | ||
| int | nYOff, | ||
| double | dfBeta | ||
| ) |
Calculates the exponent value of A * beta and places the result in Y.
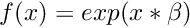
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Specifies an offset (in items, not bytes) into the memory of A. |
| nYOff | Specifies an offset (in items, not bytes) into the memory of Y. |
| dfBeta | Specifies the scalar as type double
|
Definition at line 7471 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.fill | ( | int | n, |
| int | nDim, | ||
| long | hSrc, | ||
| int | nSrcOff, | ||
| int | nCount, | ||
| long | hDst | ||
| ) |
Fill data from the source data 'n' times in the destination.
| n | Specifies the number of times to copy the source data. |
| nDim | Specifies the number of source items to copy. |
| hSrc | Specifies a handle to the GPU memory of the source data. |
| nSrcOff | Specifies an offset into the GPU memory where the source data copy starts. |
| nCount | Specifies the total number of items in the destination. This value must be >= n * nDim. |
| hDst | Specifies the handle to the GPU memory where the data is to be copied. |
Definition at line 6199 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeConvolutionDesc | ( | long | h | ) |
Free a convolution descriptor instance.
| h | Specifies the handle to the convolution descriptor instance. |
Definition at line 3765 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeCuDNN | ( | long | h | ) |
Free an instance of cuDnn.
| h | Specifies the handle to cuDnn. |
Definition at line 3281 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeDropoutDesc | ( | long | h | ) |
Free a dropout descriptor instance.
| h | Specifies the handle to the dropout descriptor instance. |
Definition at line 4221 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeExtension | ( | long | hExtension | ) |
Free an instance of an Extension.
| hExtension | Specifies the handle to the Extension. |
Definition at line 3474 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeFilterDesc | ( | long | h | ) |
Free a filter descriptor instance.
| h | Specifies the handle to the filter descriptor instance. |
Definition at line 3686 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeHostBuffer | ( | long | hMem | ) |
Free previously allocated host memory.
| hMem | Specifies the handle to the host memory. |
Definition at line 2602 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeImageOp | ( | long | h | ) |
Free an image op, freeing up all GPU memory used.
| h | Specifies the handle to the image op. |
Definition at line 3171 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeLayerNorm | ( | long | hLayerNorm | ) |
Free the instance of LayerNorm GPU support.
| hLayerNorm | Specifies the handle to the LayerNorm instance. |
Definition at line 5846 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeLRNDesc | ( | long | h | ) |
Free a LRN descriptor instance.
| h | Specifies the handle to the LRN descriptor instance. |
Definition at line 4326 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeMemory | ( | long | hMem | ) |
Free previously allocated GPU memory.
| hMem | Specifies the handle to the GPU memory. |
Definition at line 2517 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeMemoryPointer | ( | long | hData | ) |
Frees a memory pointer.
| hData | Specifies the handle to the memory pointer. |
Definition at line 3046 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeMemoryTest | ( | long | h | ) |
Free a memory test, freeing up all GPU memory used.
| h | Specifies the handle to the memory test. |
Definition at line 3095 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeNCCL | ( | long | hNccl | ) |
Free an instance of NCCL.
| hNccl | Specifies the handle to NCCL. |
Definition at line 3355 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreePCA | ( | long | hPCA | ) |
Free the PCA instance associated with handle.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| hPCA | Specifies a handle to the PCA instance to free. |
Definition at line 5446 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreePoolingDesc | ( | long | h | ) |
Free a pooling descriptor instance.
| h | Specifies the handle to the pooling descriptor instance. |
Definition at line 4055 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeRnn8 | ( | long | h | ) |
Free an existing RNN8.
| h | Specifies the handle to the RNN8 created with CreateRnn8 |
Definition at line 5178 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeRnnDataDesc | ( | long | h | ) |
Free an existing RNN Data descriptor.
| h | Specifies the handle to the RNN Data descriptor created with CreateRnnDataDesc |
Definition at line 4672 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeRnnDesc | ( | long | h | ) |
Free an existing RNN descriptor.
| h | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
Definition at line 4751 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeSSD | ( | long | hSSD | ) |
Free the instance of SSD GPU support.
| hSSD | Specifies the handle to the SSD instance. |
Definition at line 5637 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeStream | ( | long | h | ) |
Free a stream.
| h | Specifies the handle to the stream. |
Definition at line 3227 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.FreeTensorDesc | ( | long | h | ) |
Free a tensor descriptor instance.
| h | Specifies the handle to the tensor descriptor instance. |
Definition at line 3536 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gather_bwd | ( | int | nCount, |
| long | hTop, | ||
| long | hBottom, | ||
| int | nAxis, | ||
| int | nDim, | ||
| int | nDimAtAxis, | ||
| int | nM, | ||
| int | nN, | ||
| long | hIdx | ||
| ) |
Performs a gather backward pass where data at specifies indexes along a given axis are copied to the output data.
| nCount | Specifies the number of items. |
| hTop | Specifies the input data. |
| hBottom | Specifies the output data. |
| nAxis | Specifies the axis along which to copy. |
| nDim | Specifies the dimension of each item at each index. |
| nDimAtAxis | Specifies the dimension at the axis. |
| nM | Specifies the M dimension. |
| nN | Specifies the M dimension. |
| hIdx | Specifies the indexes of the data to gather. |
Definition at line 10122 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gather_fwd | ( | int | nCount, |
| long | hBottom, | ||
| long | hTop, | ||
| int | nAxis, | ||
| int | nDim, | ||
| int | nDimAtAxis, | ||
| int | nM, | ||
| int | nN, | ||
| long | hIdx | ||
| ) |
Performs a gather forward pass where data at specifies indexes along a given axis are copied to the output data.
| nCount | Specifies the number of items. |
| hBottom | Specifies the input data. |
| hTop | Specifies the output data. |
| nAxis | Specifies the axis along which to copy. |
| nDim | Specifies the dimension of each item at each index. |
| nDimAtAxis | Specifies the dimension at the axis. |
| nM | Specifies the M dimension. |
| nN | Specifies the M dimension. |
| hIdx | Specifies the indexes of the data to gather. |
Definition at line 10102 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gaussian_blur | ( | int | n, |
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| double | dfSigma, | ||
| long | hX, | ||
| long | hY | ||
| ) |
The gaussian_blur runs a Gaussian blurring operation over each channel of the data using the sigma.
The gaussian blur operation runs a 3x3 patch, initialized with the gaussian distribution using the formula 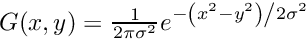
| n | Specifies the number of items in the memory of 'X'. |
| nChannels | Specifies the number of channels (i.e. 3 for RGB, 1 for B/W). |
| nHeight | Specifies the height of each item. |
| nWidth | Specifies the width of each item. |
| dfSigma | Specifies the sigma used in the gaussian blur. |
| hX | Specifies a handle to GPU memory containing the source data to blur. |
| hY | Specifies a handle to GPU memory where the blurred information is placed. |
Definition at line 10980 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.geam | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| double | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| double | fBeta, | ||
| long | hC | ||
| ) |
Perform a matrix-matrix addition/transposition operation: C = alpha transA (A) + beta transB (B)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A, B and C. |
| n | Specifies the height (number of rows) of A, B and C. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type double
|
| hA | Specifies a handle to the data for A in GPU memory. |
| hB | Specifies a handle to the data for B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type double
|
| hC | Specifies a handle to the data for C in GPU memory. |
Definition at line 6366 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.geam | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| float | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| float | fBeta, | ||
| long | hC | ||
| ) |
Perform a matrix-matrix addition/transposition operation: C = alpha transA (A) + beta transB (B)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A, B and C. |
| n | Specifies the height (number of rows) of A, B and C. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type double
|
| hA | Specifies a handle to the data for A in GPU memory. |
| hB | Specifies a handle to the data for B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type double
|
| hC | Specifies a handle to the data for C in GPU memory. |
Definition at line 6386 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.geam | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| T | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| T | fBeta, | ||
| long | hC, | ||
| int | nAOffset = 0, |
||
| int | nBOffset = 0, |
||
| int | nCOffset = 0 |
||
| ) |
Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A and C. |
| n | Specifies the height (number of rows) of B and C. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type 'T'. |
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hB | Specifies a handle to the data for matrix B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type 'T'. |
| hC | Specifies a handle to the data for matrix C in GPU memory. |
| nAOffset | Specifies an offset (in items, not bytes) into the memory of A. |
| nBOffset | Specifies an offset (in items, not bytes) into the memory of B. |
| nCOffset | Specifies an offset (in items, not bytes) into the memory of C. |
Definition at line 6409 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gelu_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData, | ||
| bool | bEnableBertVersion | ||
| ) |
Performs a GELU backward pass in Cuda.
Computes the GELU gradient. When bEnableBertVersion=false (default) Computes the GELU non-linearity  where
where 

with 
When bEnableBertVersion=true,  Note, see Wolfram Alpha with 'derivative of d/dx = 0.5 * x * (1.0 + tanh(sqrt(2.0/PI) * (x + 0.044715 * x^3)))'
Note, see Wolfram Alpha with 'derivative of d/dx = 0.5 * x * (1.0 + tanh(sqrt(2.0/PI) * (x + 0.044715 * x^3)))'
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
| bEnableBertVersion | Specifies to use the BERT version, or default version. |
Definition at line 9098 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gelu_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| bool | bEnableBertVersion | ||
| ) |
Performs a GELU forward pass in Cuda.
When bEnableBertVersion=false (default) Computes the GELU non-linearity where
with
When bEnableBertVersion=True Computes the GELU non-linearity  .
.
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| bEnableBertVersion | Specifies to use the BERT version or the default version. |
Definition at line 9064 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemm | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| double | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| double | fBeta, | ||
| long | hC | ||
| ) |
Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A and C. |
| n | Specifies the height (number of rows) of B and C. |
| k | Specifies the width (number of columns) of A and B. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type double
|
| hA | Specifies a handle to the data for A in GPU memory. |
| hB | Specifies a handle to the data for B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type double
|
| hC | Specifies a handle to the data for C in GPU memory. |
Definition at line 6236 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemm | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| double | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| double | fBeta, | ||
| long | hC, | ||
| uint | lda, | ||
| uint | ldb, | ||
| uint | ldc | ||
| ) |
Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A and C. |
| n | Specifies the height (number of rows) of B and C. |
| k | Specifies the width (number of columns) of A and B. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type 'T'. |
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hB | Specifies a handle to the data for matrix B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type 'T'. |
| hC | Specifies a handle to the data for matrix C in GPU memory. |
| lda | Specifies the leading dimension of A. |
| ldb | Specifies the leading dimension of B. |
| ldc | Specifies the leading dimension of C. |
Definition at line 6312 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemm | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| double | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| double | fBeta, | ||
| long | hC, | ||
| uint | lda, | ||
| uint | ldb, | ||
| uint | ldc, | ||
| uint | stridea, | ||
| uint | strideb, | ||
| uint | stridec, | ||
| uint | batch_count | ||
| ) |
Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A and C. |
| n | Specifies the height (number of rows) of B and C. |
| k | Specifies the width (number of columns) of A and B. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type 'T'. |
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hB | Specifies a handle to the data for matrix B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type 'T'. |
| hC | Specifies a handle to the data for matrix C in GPU memory. |
| lda | Specifies the leading dimension of A. |
| ldb | Specifies the leading dimension of B. |
| ldc | Specifies the leading dimension of C. |
| stridea | Specifies the stride of matrix A |
| strideb | Specifies the stride of matrix B |
| stridec | Specifies the stride of matrix C |
| batch_count | Specifies the number of matricies. |
Definition at line 6343 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemm | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| float | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| float | fBeta, | ||
| long | hC | ||
| ) |
Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A and C. |
| n | Specifies the height (number of rows) of B and C. |
| k | Specifies the width (number of columns) of A and B. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type float
|
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hB | Specifies a handle to the data for matrix B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type float
|
| hC | Specifies a handle to the data for matrix C in GPU memory. |
Definition at line 6257 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemm | ( | bool | bTransA, |
| bool | bTransB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| T | fAlpha, | ||
| long | hA, | ||
| long | hB, | ||
| T | fBeta, | ||
| long | hC, | ||
| int | nAOffset = 0, |
||
| int | nBOffset = 0, |
||
| int | nCOffset = 0, |
||
| int | nGroups = 1, |
||
| int | nGroupOffsetA = 0, |
||
| int | nGroupOffsetB = 0, |
||
| int | nGroupOffsetC = 0 |
||
| ) |
Perform a matrix-matrix multiplication operation: C = alpha transB (B) transA (A) + beta C
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| bTransB | Specifies whether or not to transpose B. |
| m | Specifies the width (number of columns) of A and C. |
| n | Specifies the height (number of rows) of B and C. |
| k | Specifies the width (number of columns) of A and B. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type 'T'. |
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hB | Specifies a handle to the data for matrix B in GPU memory. |
| fBeta | Specifies a scalar multiplied by C where the scalar is of type 'T'. |
| hC | Specifies a handle to the data for matrix C in GPU memory. |
| nAOffset | Specifies an offset (in items, not bytes) into the memory of A. |
| nBOffset | Specifies an offset (in items, not bytes) into the memory of B. |
| nCOffset | Specifies an offset (in items, not bytes) into the memory of C. |
| nGroups | Optionally, specifies the number of groups (default = 1). |
| nGroupOffsetA | Optionally, specifies an offset multiplied by the current group 'g' and added to the AOffset (default = 0). |
| nGroupOffsetB | Optionally, specifies an offset multiplied by the current group 'g' and added to the BOffset (default = 0). |
| nGroupOffsetC | Optionally, specifies an offset multiplied by the current group 'g' and added to the COffset (default = 0). |
Definition at line 6285 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemv | ( | bool | bTransA, |
| int | m, | ||
| int | n, | ||
| double | fAlpha, | ||
| long | hA, | ||
| long | hX, | ||
| double | fBeta, | ||
| long | hY | ||
| ) |
Perform a matrix-vector multiplication operation: y = alpha transA (A) x + beta y (where x and y are vectors)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| m | Specifies the width (number of columns) of A. |
| n | Specifies the height (number of rows) of A. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type double
|
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hX | Specifies a handle to the data for vector x in GPU memory. |
| fBeta | Specifies a scalar multiplied by y where the scalar is of type double
|
| hY | Specifies a handle to the data for vectory y in GPU memory. |
Definition at line 6431 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemv | ( | bool | bTransA, |
| int | m, | ||
| int | n, | ||
| float | fAlpha, | ||
| long | hA, | ||
| long | hX, | ||
| float | fBeta, | ||
| long | hY | ||
| ) |
Perform a matrix-vector multiplication operation: y = alpha transA (A) x + beta y (where x and y are vectors)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| m | Specifies the width (number of columns) of A. |
| n | Specifies the height (number of rows) of A. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type float
|
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hX | Specifies a handle to the data for vector x in GPU memory. |
| fBeta | Specifies a scalar multiplied by y where the scalar is of type float
|
| hY | Specifies a handle to the data for vectory y in GPU memory. |
Definition at line 6450 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.gemv | ( | bool | bTransA, |
| int | m, | ||
| int | n, | ||
| T | fAlpha, | ||
| long | hA, | ||
| long | hX, | ||
| T | fBeta, | ||
| long | hY, | ||
| int | nAOffset = 0, |
||
| int | nXOffset = 0, |
||
| int | nYOffset = 0 |
||
| ) |
Perform a matrix-vector multiplication operation: y = alpha transA (A) x + beta y (where x and y are vectors)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| bTransA | Specifies whether or not to transpose A. |
| m | Specifies the width (number of columns) of A. |
| n | Specifies the height (number of rows) of A. |
| fAlpha | Specifies a scalar multiplied by the data where the scalar is of type 'T'. |
| hA | Specifies a handle to the data for matrix A in GPU memory. |
| hX | Specifies a handle to the data for vector X in GPU memory. |
| fBeta | Specifies a scalar multiplied by Y where the scalar is of type 'T' |
| hY | Specifies a handle to the data for vectory y in GPU memory. |
| nAOffset | Specifies an offset (in items, not bytes) into the memory of A. |
| nXOffset | Specifies an offset (in items, not bytes) into the memory of X. |
| nYOffset | Specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 6472 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ger | ( | int | m, |
| int | n, | ||
| double | fAlpha, | ||
| long | hX, | ||
| long | hY, | ||
| long | hA | ||
| ) |
Perform a vector-vector multiplication operation: A = x * (fAlpha * y) (where x and y are vectors and A is an m x n Matrix)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| m | Specifies the length of X and rows in A (m x n). |
| n | Specifies the length of Y and cols in A (m x n). |
| fAlpha | Specifies a scalar multiplied by y where the scalar is of type 'T'. |
| hX | Specifies a handle to the data for matrix X (m in length) in GPU memory. |
| hY | Specifies a handle to the data for vector Y (n in length) in GPU memory. |
| hA | Specifies a handle to the data for matrix A (m x n) in GPU memory. |
Definition at line 6492 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ger | ( | int | m, |
| int | n, | ||
| float | fAlpha, | ||
| long | hX, | ||
| long | hY, | ||
| long | hA | ||
| ) |
Perform a vector-vector multiplication operation: A = x * (fAlpha * y) (where x and y are vectors and A is an m x n Matrix)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| m | Specifies the length of X and rows in A (m x n). |
| n | Specifies the length of Y and cols in A (m x n). |
| fAlpha | Specifies a scalar multiplied by y where the scalar is of type 'T'. |
| hX | Specifies a handle to the data for matrix X (m in length) in GPU memory. |
| hY | Specifies a handle to the data for vector Y (n in length) in GPU memory. |
| hA | Specifies a handle to the data for matrix A (m x n) in GPU memory. |
Definition at line 6509 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ger | ( | int | m, |
| int | n, | ||
| T | fAlpha, | ||
| long | hX, | ||
| long | hY, | ||
| long | hA | ||
| ) |
Perform a vector-vector multiplication operation: A = x * (fAlpha * y) (where x and y are vectors and A is an m x n Matrix)
This function uses NVIDIA's cuBlas but with a different parameter ordering.
| m | Specifies the length of X and rows in A (m x n). |
| n | Specifies the length of Y and cols in A (m x n). |
| fAlpha | Specifies a scalar multiplied by y where the scalar is of type 'T'. |
| hX | Specifies a handle to the data for matrix X (m in length) in GPU memory. |
| hY | Specifies a handle to the data for vector Y (n in length) in GPU memory. |
| hA | Specifies a handle to the data for matrix A (m x n) in GPU memory. |
Definition at line 6526 of file CudaDnn.cs.
| T[] MyCaffe.common.CudaDnn< T >.get | ( | int | nCount, |
| long | hHandle, | ||
| int | nIdx = -1 |
||
| ) |
Queries the GPU memory by copying it into an array of type 'T'.
| nCount | Specifies the number of items. |
| hHandle | Specifies a handle to GPU memory. |
| nIdx | When -1, all values in the GPU memory are queried, otherwise, only the value at the index nIdx is returned. |
Definition at line 5985 of file CudaDnn.cs.
| double[] MyCaffe.common.CudaDnn< T >.get_double | ( | int | nCount, |
| long | hHandle, | ||
| int | nIdx = -1 |
||
| ) |
Queries the GPU memory by copying it into an array of
double
| nCount | Specifies the number of items. |
| hHandle | Specifies a handle to GPU memory. |
| nIdx | When -1, all values in the GPU memory are queried, otherwise, only the value at the index nIdx is returned. |
Definition at line 5961 of file CudaDnn.cs.
| float[] MyCaffe.common.CudaDnn< T >.get_float | ( | int | nCount, |
| long | hHandle, | ||
| int | nIdx = -1 |
||
| ) |
Queries the GPU memory by copying it into an array of
float
| nCount | Specifies the number of items. |
| hHandle | Specifies a handle to GPU memory. |
| nIdx | When -1, all values in the GPU memory are queried, otherwise, only the value at the index nIdx is returned. |
Definition at line 5973 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.GetConvolutionInfo | ( | long | hCuDnn, |
| long | hBottomDesc, | ||
| long | hFilterDesc, | ||
| long | hConvDesc, | ||
| long | hTopDesc, | ||
| ulong | lWorkspaceSizeLimitInBytes, | ||
| bool | bUseTensorCores, | ||
| out CONV_FWD_ALGO | algoFwd, | ||
| out ulong | lWsSizeFwd, | ||
| out CONV_BWD_FILTER_ALGO | algoBwdFilter, | ||
| out ulong | lWsSizeBwdFilter, | ||
| out CONV_BWD_DATA_ALGO | algoBwdData, | ||
| out ulong | lWsSizeBwdData, | ||
| CONV_FWD_ALGO | preferredFwdAlgo = CONV_FWD_ALGO.NONE |
||
| ) |
Queryies the algorithms and workspace sizes used for a given convolution descriptor.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hFilterDesc | Specifies a handle to the filter descriptor. |
| hConvDesc | Specifies a handle to the convolution descriptor. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| lWorkspaceSizeLimitInBytes | Specifies the workspace limits (in bytes). |
| bUseTensorCores | Specifies whether or not to use tensor cores (this parameter must match the setting of the 'bUseTensorCores' specified in the 'SetConvolutionDesc' method. |
| algoFwd | Returns the algorithm used for the convolution foward. |
| lWsSizeFwd | Returns the workspace size (in bytes) for the convolution foward. |
| algoBwdFilter | Returns the algorithm used for the backward filter. |
| lWsSizeBwdFilter | Returns the workspace size (int bytes) for the backward filter. |
| algoBwdData | Returns the algorithm for the backward data. |
| lWsSizeBwdData | Returns the workspace (in bytes) for the backward data. |
| preferredFwdAlgo | Optionally, specifies a preferred forward algo to attempt to use for forward convolution. The new algo is only used if the current device supports it. |
Definition at line 3810 of file CudaDnn.cs.
|
static |
Returns the path to the CudaDnnDll module to use for low level CUDA processing.
Definition at line 1638 of file CudaDnn.cs.
| int MyCaffe.common.CudaDnn< T >.GetDeviceCount | ( | ) |
Query the number of devices (gpu's) installed.
Definition at line 2127 of file CudaDnn.cs.
| int MyCaffe.common.CudaDnn< T >.GetDeviceID | ( | ) |
Returns the current device id set within Cuda.
Definition at line 2013 of file CudaDnn.cs.
| string MyCaffe.common.CudaDnn< T >.GetDeviceInfo | ( | int | nDeviceID, |
| bool | bVerbose = false |
||
| ) |
Query the device information of a device.
| nDeviceID | Specifies the device id. |
| bVerbose | When true, more detailed information is returned. |
Definition at line 2064 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.GetDeviceMemory | ( | out double | dfFree, |
| out double | dfUsed, | ||
| out bool | bCudaCallUsed, | ||
| int | nDeviceID = -1 |
||
| ) |
Queries the amount of total, free and used memory on a given GPU.
| dfFree | Specifies the amount of free memory in GB. |
| dfUsed | Specifies the amount of used memory in GB. |
| bCudaCallUsed | Specifies whether or not the used memory is an estimate calculated using the Low-Level Cuda DNN Dll handle table. |
| nDeviceID | Specifies the specific device id to query, or if -1, uses calculates an estimate of the memory used using the current low-level Cuda DNN Dll handle table. |
Definition at line 2182 of file CudaDnn.cs.
| string MyCaffe.common.CudaDnn< T >.GetDeviceName | ( | int | nDeviceID | ) |
Query the name of a device.
| nDeviceID | Specifies the device id. |
Definition at line 2035 of file CudaDnn.cs.
| string MyCaffe.common.CudaDnn< T >.GetDeviceP2PInfo | ( | int | nDeviceID | ) |
Query the peer-to-peer information of a device.
| nDeviceID | Specifies the device id. |
Definition at line 2049 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.GetDropoutInfo | ( | long | hCuDnn, |
| long | hBottomDesc, | ||
| out ulong | ulStateCount, | ||
| out ulong | ulReservedCount | ||
| ) |
Query the dropout state and reserved counts.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| ulStateCount | Returns the state count. |
| ulReservedCount | Returns the reserved count. |
Definition at line 4252 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.GetHostBufferCapacity | ( | long | hMem | ) |
Returns the host memory capacity.
| hMem | Specfies the host memory. |
Definition at line 2621 of file CudaDnn.cs.
| T[] MyCaffe.common.CudaDnn< T >.GetHostMemory | ( | long | hMem | ) |
Retrieves the host memory as an array of type 'T'
| hMem | Specifies the handle to the host memory. |
Definition at line 2662 of file CudaDnn.cs.
| double[] MyCaffe.common.CudaDnn< T >.GetHostMemoryDouble | ( | long | hMem | ) |
Retrieves the host memory as an array of doubles.
This function converts the output array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the host memory. |
Definition at line 2641 of file CudaDnn.cs.
| float[] MyCaffe.common.CudaDnn< T >.GetHostMemoryFloat | ( | long | hMem | ) |
Retrieves the host memory as an array of floats.
This function converts the output array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the host memory. |
Definition at line 2652 of file CudaDnn.cs.
| T[] MyCaffe.common.CudaDnn< T >.GetMemory | ( | long | hMem, |
| long | lCount = -1 |
||
| ) |
Retrieves the GPU memory as an array of type 'T'
| hMem | Specifies the handle to the GPU memory. |
| lCount | Optionally, specifies a count of items to retrieve. |
Definition at line 2700 of file CudaDnn.cs.
| double[] MyCaffe.common.CudaDnn< T >.GetMemoryDouble | ( | long | hMem, |
| long | lCount = -1 |
||
| ) |
Retrieves the GPU memory as an array of doubles.
This function converts the output array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| lCount | Optionally, specifies a count of items to retrieve. |
Definition at line 2677 of file CudaDnn.cs.
| float[] MyCaffe.common.CudaDnn< T >.GetMemoryFloat | ( | long | hMem, |
| long | lCount = -1 |
||
| ) |
Retrieves the GPU memory as an array of float.
This function converts the output array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| lCount | Optionally, specifies a count of items to retrieve. |
Definition at line 2689 of file CudaDnn.cs.
| int MyCaffe.common.CudaDnn< T >.GetMultiGpuBoardGroupID | ( | int | nDeviceID | ) |
Query the mutli-gpu board group id for a device.
| nDeviceID | Specifies the device id. |
Definition at line 2109 of file CudaDnn.cs.
| string MyCaffe.common.CudaDnn< T >.GetRequiredCompute | ( | out int | nMinMajor, |
| out int | nMinMinor | ||
| ) |
The GetRequiredCompute function returns the Major and Minor compute values required by the current CudaDNN DLL used.
| nMinMajor | Specifies the minimum required major compute value. |
| nMinMinor | Specifies the minimum required minor compute value. |
Together the Major.Minor compute values define the minimum required compute for the CudaDNN DLL used.
Definition at line 2216 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.GetRnn8MemorySizes | ( | long | hCuDnn, |
| long | hRnn, | ||
| out ulong | szWtCount, | ||
| out ulong | szWorkSize, | ||
| out ulong | szReservedSize | ||
| ) |
Returns the memory sizes required for the RNN8.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnn | Specifies the handle to the RNN8 created with CreateRnn8. |
| szWtCount | Returns the required weight count (in items). |
| szWorkSize | Returns the rquired work size (in bytes). |
| szReservedSize | Returns the required reserved size (in bytes). |
Definition at line 5221 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.GetRnnLinLayerParams | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| int | nLayer, | ||
| long | hXDesc, | ||
| long | hWtDesc, | ||
| long | hWtData, | ||
| int | nLinLayer, | ||
| out int | nWtCount, | ||
| out long | hWt, | ||
| out int | nBiasCount, | ||
| out long | hBias | ||
| ) |
Returns the linear layer parameters (weights).
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| nLayer | Specifies the current layer index. |
| hXDesc | Specifies the input data elelement descriptor. |
| hWtDesc | Specifies the weight descriptor. |
| hWtData | Specifies the weight memory containing all weights. |
| nLinLayer | Specifies the linear layer index (e.g. LSTM has 8 linear layers, RNN has 2) |
| nWtCount | Returns the number of weight items. |
| hWt | Returns a handle to the weight GPU memory. |
| nBiasCount | Returns the number of bias items. |
| hBias | Returns a handle to the bias GPU memory. |
Definition at line 4837 of file CudaDnn.cs.
| int MyCaffe.common.CudaDnn< T >.GetRnnParamCount | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| long | hXDesc | ||
| ) |
Returns the RNN parameter count.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| hXDesc | Specifies the handle to the first X descriptor. |
Definition at line 4785 of file CudaDnn.cs.
| ulong MyCaffe.common.CudaDnn< T >.GetRnnWorkspaceCount | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| long | hXDesc, | ||
| out ulong | nReservedCount | ||
| ) |
Returns the workspace and reserved counts.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| hXDesc | Specifies a handle to the data descriptor created with CreateRnnDataDesc. |
| nReservedCount | Returns the reserved count needed. |
Definition at line 4807 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.hamming_distance | ( | int | n, |
| double | dfThreshold, | ||
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| int | nOffA = 0, |
||
| int | nOffB = 0, |
||
| int | nOffY = 0 |
||
| ) |
The hamming_distance calculates the Hamming Distance between X and Y both of length n.
To calculate the hamming distance first, X and Y are bitified where each element is converted to 1 if > than the threshold, or 0 otherwise. Next, the bitified versions of X and Y are subtracted from one another, and the Asum of the result is returned, which is the number of bits that are different, thus the Hamming distance.
| n | Specifies the number of elements to compare in both X and Y. |
| dfThreshold | Specifies the threshold used to 'bitify' both X and Y |
| hA | Specifies the handle to the GPU memory containing the first vector to compare. |
| hB | Specifies the handle to the GPU memory containing the second vector to compare. |
| hY | Specifies the handle to the GPU memory where the hamming difference (bitified A - bitified B) is placed. |
| nOffA | Optionally, specifies an offset into the GPU memory of A, the default is 0. |
| nOffB | Optionally, specifies an offset into the GPU memory of B, the default is 0. |
| nOffY | Optionally, specifies an offset into the GPU memory of Y, the default is 0. |
Definition at line 11005 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.im2col | ( | long | hDataIm, |
| int | nDataImOffset, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nKernelH, | ||
| int | nKernelW, | ||
| int | nPadH, | ||
| int | nPadW, | ||
| int | nStrideH, | ||
| int | nStrideW, | ||
| int | nDilationH, | ||
| int | nDilationW, | ||
| long | hDataCol, | ||
| int | nDataColOffset | ||
| ) |
Rearranges image blocks into columns.
| hDataIm | Specifies a handle to the image block in GPU memory. |
| nDataImOffset | Specifies an offset into the image block memory. |
| nChannels | Specifies the number of channels in the image. |
| nHeight | Specifies the height of the image. |
| nWidth | Specifies the width of the image. |
| nKernelH | Specifies the kernel height. |
| nKernelW | Specifies the kernel width. |
| nPadH | Specifies the pad applied to the height. |
| nPadW | Specifies the pad applied to the width. |
| nStrideH | Specifies the stride along the height. |
| nStrideW | Specifies the stride along the width. |
| nDilationH | Specifies the dilation along the height. |
| nDilationW | Specifies the dilation along the width. |
| hDataCol | Specifies a handle to the column data in GPU memory. |
| nDataColOffset | Specifies an offset into the column memory. |
Definition at line 7989 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.im2col_nd | ( | long | hDataIm, |
| int | nDataImOffset, | ||
| int | nNumSpatialAxes, | ||
| int | nImCount, | ||
| int | nChannelAxis, | ||
| long | hImShape, | ||
| long | hColShape, | ||
| long | hKernelShape, | ||
| long | hPad, | ||
| long | hStride, | ||
| long | hDilation, | ||
| long | hDataCol, | ||
| int | nDataColOffset | ||
| ) |
Rearranges image blocks into columns.
| hDataIm | Specifies a handle to the image block in GPU memory. |
| nDataImOffset | Specifies an offset into the image block memory. |
| nNumSpatialAxes | Specifies the number of spatial axes. |
| nImCount | Specifies the number of kernels. |
| nChannelAxis | Specifies the axis containing the channel. |
| hImShape | Specifies a handle to the image shape data in GPU memory. |
| hColShape | Specifies a handle to the column shape data in GPU memory. |
| hKernelShape | Specifies a handle to the kernel shape data in GPU memory. |
| hPad | Specifies a handle to the pad data in GPU memory. |
| hStride | Specifies a handle to the stride data in GPU memory. |
| hDilation | Specifies a handle to the dilation data in GPU memory. |
| hDataCol | Specifies a handle to the column data in GPU memory. |
| nDataColOffset | Specifies an offset into the column memory. |
Definition at line 8013 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.InitializeRnn8Weights | ( | long | hCuDnn, |
| long | hRnn, | ||
| long | hWt, | ||
| RNN_FILLER_TYPE | wtFt, | ||
| double | fWtVal, | ||
| double | fWtVal2, | ||
| RNN_FILLER_TYPE | biasFt, | ||
| double | fBiasVal, | ||
| double | fBiasVal2 | ||
| ) |
Initialize the RNN8 weights
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnn | Specifies the handle to the RNN8 created with CreateRnn8. |
| hWt | Specifies the handle to the GPU data containing the weights to be initialized. |
| wtFt | Specifies the weight filler type. |
| fWtVal | Specifies the weight filler value. |
| fWtVal2 | Specifies a secondary weight filler value. |
| biasFt | Specifies the bias filler type. |
| fBiasVal | Specifies the bias filler value. |
| fBiasVal2 | Specifies a secondary bias filler value. |
Definition at line 5251 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.interp2 | ( | int | nChannels, |
| long | hData1, | ||
| int | nX1, | ||
| int | nY1, | ||
| int | nHeight1, | ||
| int | nWidth1, | ||
| int | nHeight1A, | ||
| int | nWidth1A, | ||
| long | hData2, | ||
| int | nX2, | ||
| int | nY2, | ||
| int | nHeight2, | ||
| int | nWidth2, | ||
| int | nHeight2A, | ||
| int | nWidth2A, | ||
| bool | bBwd = false |
||
| ) |
Interpolates between two sizes within the spatial dimensions.
| nChannels | Specifies the channels (usually num * channels) |
| hData1 | Specifies the input data when bBwd=false and the output data when bBwd=true. |
| nX1 | Specifies the offset along the x axis for data1. |
| nY1 | Specifies the offset along the y axis for data1. |
| nHeight1 | Specifies the effective height for data1. |
| nWidth1 | Specifies the effective width for data1. |
| nHeight1A | Specifies the input height for data1. |
| nWidth1A | Specifies the input width for data1. |
| hData2 | Specifies the output data when bBwd=false and the input data when bBwd=true. |
| nX2 | Specifies the offset along the x axis for data2. |
| nY2 | Specifies the offset along the y axis for data2. |
| nHeight2 | Specifies the effective height for data2. |
| nWidth2 | Specifies the effective width for data2. |
| nHeight2A | Specifies the output height for data2. |
| nWidth2A | Specifies the output width for data2. |
| bBwd | Optionally, specifies to perform the backward operation from data2 to data1, otherwise the operation performs on data1 to data2. (default = false). |
Definition at line 7138 of file CudaDnn.cs.
| bool MyCaffe.common.CudaDnn< T >.IsRnn8Supported | ( | ) |
Returns whether or not RNN8 is supported.
Definition at line 5142 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.KernelAdd | ( | int | nCount, |
| long | hA, | ||
| long | hDstKernel, | ||
| long | hB, | ||
| long | hC | ||
| ) |
Add memory from one kernel to memory residing on another kernel.
| nCount | Specifies the number of items within both A and B. |
| hA | Specifies the handle to the memory A. |
| hDstKernel | Specifies the kernel where the memory B and the desitnation memory C reside. |
| hB | Specifies the handle to the memory B (for which A will be added). |
| hC | Specifies the destination data where A+B will be placed. |
Definition at line 1848 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.KernelCopy | ( | int | nCount, |
| long | hSrc, | ||
| int | nSrcOffset, | ||
| long | hDstKernel, | ||
| long | hDst, | ||
| int | nDstOffset, | ||
| long | hHostBuffer, | ||
| long | hHostKernel = -1, |
||
| long | hStream = -1, |
||
| long | hSrcKernel = -1 |
||
| ) |
Copy memory from the look-up tables in one kernel to another.
| nCount | Specifies the number of items to copy. |
| hSrc | Specifies the handle to the source memory. |
| nSrcOffset | Specifies the offset (in items, not bytes) from which to start the copy in the source memory. |
| hDstKernel | Specifies the destination kernel holding the look-up table and memory where the data is to be copied. |
| hDst | Specifies the handle to the destination memory where the data is to be copied. |
| nDstOffset | Specifies the offset (in items, not bytes) where the copy to to be placed within the destination data. |
| hHostBuffer | Specifies the handle to the host buffer to be used when transfering the data from one kernel to another. |
| hHostKernel | Optionally, specifies the handle to the kernel holding the look-up table for the host buffer. |
| hStream | Optionally, specifies the handle to the CUDA stream to use for the transfer. |
| hSrcKernel | Optionally, specifies the handle to the source kernel. |
Definition at line 1829 of file CudaDnn.cs.
| long MyCaffe.common.CudaDnn< T >.KernelCopyNccl | ( | long | hSrcKernel, |
| long | hSrcNccl | ||
| ) |
Copies an Nccl handle from one kernel to the current kernel of the current CudaDnn instance.
Nccl handles are created on the main Kernel, but when used must transferred to the destination kernel (running on a different thread) where the secondary Nccl handle is used.
| hSrcKernel | Specifies the source kernel (typically where the Nccl handle was created). |
| hSrcNccl | Specifies the source Nccl handle to be copied. |
Definition at line 1866 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.LayerNormBackward | ( | long | hLayerNorm, |
| long | hYdata, | ||
| long | hYdiff, | ||
| long | hXdiff | ||
| ) |
Run the LayerNorm backward pass.
| hLayerNorm | Specifies the handle to the LayerNorm instance. |
| hYdata | Specifies the normalized output data. |
| hYdiff | Specifies the input diff to be un-normalized. |
| hXdiff | Specifies the un-normalized output diff. |
Definition at line 5875 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.LayerNormForward | ( | long | hLayerNorm, |
| long | hXdata, | ||
| long | hYdata | ||
| ) |
Run the LayerNorm forward pass.
| hLayerNorm | Specifies the handle to the LayerNorm instance. |
| hXdata | Specifies the input data to be normalized. |
| hYdata | Specifies the normalized output data. |
Definition at line 5860 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lecun_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData | ||
| ) |
Performs the LeCun's Tanh function backward
Computes the LeCun non-linearity 

| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
Definition at line 9225 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lecun_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs the LeCun's Tanh function forward
Computes the LeCun non-linearity
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9203 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.log | ( | int | n, |
| long | hA, | ||
| long | hY | ||
| ) |
Calculates the log value of A and places the result in Y.
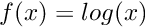
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7488 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.log | ( | int | n, |
| long | hA, | ||
| long | hY, | ||
| double | dfBeta, | ||
| double | dfAlpha = 0 |
||
| ) |
Calculates the log value of (A * beta) + alpha, and places the result in Y.
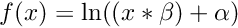
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| dfBeta | Specifies the scalar as type double
|
| dfAlpha | Optionally, specifies a scalar added to the value before taking the log. |
Definition at line 7504 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lrn_computediff | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| long | hScaleData, | ||
| long | hTopDiff, | ||
| int | nNum, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nSize, | ||
| T | fNegativeBeta, | ||
| T | fCacheRatio, | ||
| long | hBottomDiff | ||
| ) |
Computes the diff used to calculate the LRN cross channel backward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hScaleData | Specifies a handle to the scale data in GPU memory. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nNum | Specifies the number of input items. |
| nChannels | Specifies the number of channels per input item. |
| nHeight | Specifies the height of each input item. |
| nWidth | Specifies the width of each input item. |
| nSize | NEEDS REVIEW |
| fNegativeBeta | Specifies the negative beta value. |
| fCacheRatio | NEEDS REVIEW |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 10184 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lrn_computeoutput | ( | int | nCount, |
| long | hBottomData, | ||
| long | hScaleData, | ||
| T | fNegativeBeta, | ||
| long | hTopData | ||
| ) |
Computes the output used to calculate the LRN cross channel forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| hScaleData | Specifies a handle to the scale data in GPU memory. |
| fNegativeBeta | Specifies the negative beta value. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 10159 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lrn_fillscale | ( | int | nCount, |
| long | hBottomData, | ||
| int | nNum, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nSize, | ||
| T | fAlphaOverSize, | ||
| T | fK, | ||
| long | hScaleData | ||
| ) |
Performs the fill scale operation used to calculate the LRN cross channel forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| nNum | Specifies the number of input items. |
| nChannels | Specifies the number of channels per input item. |
| nHeight | Specifies the height of each input item. |
| nWidth | Specifies the width of each input item. |
| nSize | NEEDS REVIEW |
| fAlphaOverSize | Specifies the alpha value over the size. |
| fK | Specifies the k value. |
| hScaleData | Specifies a handle to the scale data in GPU memory. |
Definition at line 10143 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.LRNCrossChannelBackward | ( | long | hCuDnn, |
| long | hNormDesc, | ||
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform LRN cross channel backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hNormDesc | Specifies a handle to an LRN descriptor. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4384 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.LRNCrossChannelForward | ( | long | hCuDnn, |
| long | hNormDesc, | ||
| T | fAlpha, | ||
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDesc, | ||
| long | hTopData | ||
| ) |
Perform LRN cross channel forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hNormDesc | Specifies a handle to an LRN descriptor. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4361 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lstm_bwd | ( | int | t, |
| int | nN, | ||
| int | nH, | ||
| int | nI, | ||
| double | dfClippingThreshold, | ||
| long | hWeight_h, | ||
| long | hClipData, | ||
| int | nClipOffset, | ||
| long | hTopDiff, | ||
| int | nTopOffset, | ||
| long | hCellData, | ||
| long | hCellDiff, | ||
| int | nCellOffset, | ||
| long | hPreGateDiff, | ||
| int | nPreGateOffset, | ||
| long | hGateData, | ||
| long | hGateDiff, | ||
| int | nGateOffset, | ||
| long | hCT1Data, | ||
| int | nCT1Offset, | ||
| long | hDHT1Diff, | ||
| int | nDHT1Offset, | ||
| long | hDCT1Diff, | ||
| int | nDCT1Offset, | ||
| long | hHtoHData, | ||
| long | hContextDiff = 0, |
||
| long | hWeight_c = 0 |
||
| ) |
Peforms the simple LSTM backward pass in Cuda.
See LSTM with Working Memory by Pulver, et al., 2016
| t | Specifies the step within the sequence. |
| nN | Specifies the batch size. |
| nH | Specifies the number of hidden units. |
| nI | Specifies the number the input size. |
| dfClippingThreshold | |
| hWeight_h | Specifies a handle to the GPU memory holding the 'h' weights. |
| hClipData | Specifies a handle to the GPU memory holding the clip data. |
| nClipOffset | Specifies the clip offset for this step within the sequence. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTopOffset | Specifies an offset into the top diff memory. |
| hCellData | Specifies a handle to the GPU memory holding the 'c_t' data. |
| hCellDiff | Specifies a handle to the GPU memory holding the 'c_t' gradients. |
| nCellOffset | Specifies the c_t offset for this step within the sequence. |
| hPreGateDiff | Specifies a handle to the GPU memory holding the pre-gate gradients. |
| nPreGateOffset | Specifies the pre-gate offset for this step within the sequence. |
| hGateData | Specifies a handle to the GPU memory holding the gate data. |
| hGateDiff | Specifies a handle to the GPU memory holding the gate gradients. |
| nGateOffset | Specifies the gate data offset for this step within the sequence. |
| hCT1Data | Specifies a handle to the GPU memory holding the CT1 data. |
| nCT1Offset | Specifies the CT1 offset for this step within the sequence. |
| hDHT1Diff | Specifies a handle to the GPU DHT1 gradients. |
| nDHT1Offset | Specifies the DHT1 offset for this step within the sequence. |
| hDCT1Diff | Specifies a handle to the DCT1 gradients. |
| nDCT1Offset | Specifies the DCT1 offset for this step within the sequence. |
| hHtoHData | Specifies a handle to the GPU memory holding the H to H data. |
| hContextDiff | Optionally, specifies the handle to the GPU memory holding the context diff, or 0 when not used. |
| hWeight_c | Optionally, specifies the handle to the GPU memory holding the 'c' weights, or 0 when not used. |
Definition at line 10413 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lstm_fwd | ( | int | t, |
| int | nN, | ||
| int | nH, | ||
| int | nI, | ||
| long | hWeight_h, | ||
| long | hWeight_i, | ||
| long | hClipData, | ||
| int | nClipOffset, | ||
| long | hTopData, | ||
| int | nTopOffset, | ||
| long | hCellData, | ||
| int | nCellOffset, | ||
| long | hPreGateData, | ||
| int | nPreGateOffset, | ||
| long | hGateData, | ||
| int | nGateOffset, | ||
| long | hHT1Data, | ||
| int | nHT1Offset, | ||
| long | hCT1Data, | ||
| int | nCT1Offset, | ||
| long | hHtoGateData, | ||
| long | hContext = 0, |
||
| long | hWeight_c = 0, |
||
| long | hCtoGetData = 0 |
||
| ) |
Peforms the simple LSTM foward pass in Cuda.
See LSTM with Working Memory by Pulver, et al., 2016
| t | Specifies the step within the sequence. |
| nN | Specifies the batch size. |
| nH | Specifies the number of hidden units. |
| nI | Specifies the number the input size. |
| hWeight_h | Specifies a handle to the GPU memory holding the 'h' weights. |
| hWeight_i | Specifies a handle to the GPU memory holding the 'i' weights. |
| hClipData | Specifies a handle to the GPU memory holding the clip data. |
| nClipOffset | Specifies the clip offset for this step within the sequence. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| nTopOffset | Specifies an offset into the top data memory. |
| hCellData | Specifies a handle to the GPU memory holding the 'c_t' data. |
| nCellOffset | Specifies the c_t offset for this step within the sequence. |
| hPreGateData | Specifies a handle to the GPU memory holding the pre-gate data. |
| nPreGateOffset | Specifies the pre-gate offset for this step within the sequence. |
| hGateData | Specifies a handle to the GPU memory holding the gate data. |
| nGateOffset | Specifies the gate data offset for this step within the sequence. |
| hHT1Data | Specifies a handle to the GPU memory holding the HT1 data. |
| nHT1Offset | Specifies the HT1 offset for this step within the sequence. |
| hCT1Data | Specifies a handle to the GPU memory holding the CT1 data. |
| nCT1Offset | Specifies the CT1 offset for this step within the sequence. |
| hHtoGateData | Specifies a handle to the GPU memory holding the H to Gate data. |
| hContext | Optionally, specifies the attention context, or 0 when not used. |
| hWeight_c | Optionally, specifies the attention context weights, or 0 when not used. |
| hCtoGetData | Optionally, specifies the attention context to gate data, or 0 when not used. |
Definition at line 10372 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lstm_unit_bwd | ( | int | nCount, |
| int | nHiddenDim, | ||
| int | nXCount, | ||
| long | hC_prev, | ||
| long | hX_acts, | ||
| long | hC, | ||
| long | hH, | ||
| long | hCont, | ||
| long | hC_diff, | ||
| long | hH_diff, | ||
| long | hC_prev_diff, | ||
| long | hX_acts_diff, | ||
| long | hX_diff | ||
| ) |
Peforms the simple LSTM backward pass in Cuda for a given LSTM unit.
See LSTM with Working Memory by Pulver, et al., 2016
| nCount | NEEDS REVIEW |
| nHiddenDim | NEEDS REVIEW |
| nXCount | NEEDS REVIEW |
| hC_prev | NEEDS REVIEW |
| hX_acts | NEEDS REVIEW |
| hC | NEEDS REVIEW |
| hH | NEEDS REVIEW |
| hCont | NEEDS REVIEW |
| hC_diff | NEEDS REVIEW |
| hH_diff | NEEDS REVIEW |
| hC_prev_diff | NEEDS REVIEW |
| hX_acts_diff | NEEDS REVIEW |
| hX_diff | NEEDS REVIEW |
Definition at line 10463 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.lstm_unit_fwd | ( | int | nCount, |
| int | nHiddenDim, | ||
| int | nXCount, | ||
| long | hX, | ||
| long | hX_acts, | ||
| long | hC_prev, | ||
| long | hCont, | ||
| long | hC, | ||
| long | hH | ||
| ) |
Peforms the simple LSTM foward pass in Cuda for a given LSTM unit.
See LSTM with Working Memory by Pulver, et al., 2016
| nCount | NEEDS REVIEW |
| nHiddenDim | NEEDS REVIEW |
| nXCount | NEEDS REVIEW |
| hX | NEEDS REVIEW |
| hX_acts | NEEDS REVIEW |
| hC_prev | NEEDS REVIEW |
| hCont | NEEDS REVIEW |
| hC | NEEDS REVIEW |
| hH | NEEDS REVIEW |
Definition at line 10436 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mask | ( | int | n, |
| int | nMaskDim, | ||
| double | fSearch, | ||
| double | fReplace, | ||
| long | hX, | ||
| long | hMask, | ||
| long | hY | ||
| ) |
Mask the mask the data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination.
| n | Specifies the number of items. |
| nMaskDim | Specifies the number of items in the mask. |
| fSearch | Specifies the value within the mask to replace. |
| fReplace | Specifies the replacement value. |
| hX | Specifies a handle to the GPU memory of the source. |
| hMask | Specifies a handle to the GPU memory of the mask (containing the 'fSearch' values) |
| hY | Specifies a handle to the GPU memory of the destination. |
Definition at line 7048 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mask | ( | int | n, |
| int | nMaskDim, | ||
| float | fSearch, | ||
| float | fReplace, | ||
| long | hX, | ||
| long | hMask, | ||
| long | hY | ||
| ) |
Mask the mask the data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination.
| n | Specifies the number of items. |
| nMaskDim | Specifies the number of items in the mask. |
| fSearch | Specifies the value within the mask to replace. |
| fReplace | Specifies the replacement value. |
| hX | Specifies a handle to the GPU memory of the source. |
| hMask | Specifies a handle to the GPU memory of the mask (containing the 'fSearch' values) |
| hY | Specifies a handle to the GPU memory of the destination. |
Definition at line 7063 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mask | ( | int | n, |
| int | nMaskDim, | ||
| T | fSearch, | ||
| T | fReplace, | ||
| long | hX, | ||
| long | hMask, | ||
| long | hY | ||
| ) |
Mask the mask the data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination.
| n | Specifies the number of items. |
| nMaskDim | Specifies the number of items in the mask. |
| fSearch | Specifies the value within the mask to replace. |
| fReplace | Specifies the replacement value. |
| hX | Specifies a handle to the GPU memory of the source. |
| hMask | Specifies a handle to the GPU memory of the mask (containing the 'fSearch' values) |
| hY | Specifies a handle to the GPU memory of the destination. |
Definition at line 7030 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mask_batch | ( | int | n, |
| int | nBatch, | ||
| int | nMaskDim, | ||
| double | fSearch, | ||
| double | fReplace, | ||
| long | hX, | ||
| long | hMask, | ||
| long | hY | ||
| ) |
Mask the mask the batch of data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination.
| n | Specifies the number of items. |
| nBatch | Specifies the batch size. |
| nMaskDim | Specifies the number of items in the mask. |
| fSearch | Specifies the value within the mask to replace. |
| fReplace | Specifies the replacement value. |
| hX | Specifies a handle to the GPU memory of the source. |
| hMask | Specifies a handle to the GPU memory of the mask (containing the 'fSearch' values) |
| hY | Specifies a handle to the GPU memory of the destination. |
Definition at line 7098 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mask_batch | ( | int | n, |
| int | nBatch, | ||
| int | nMaskDim, | ||
| float | fSearch, | ||
| float | fReplace, | ||
| long | hX, | ||
| long | hMask, | ||
| long | hY | ||
| ) |
Mask the mask the batch of data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination.
| n | Specifies the number of items. |
| nBatch | Specifies the batch size. |
| nMaskDim | Specifies the number of items in the mask. |
| fSearch | Specifies the value within the mask to replace. |
| fReplace | Specifies the replacement value. |
| hX | Specifies a handle to the GPU memory of the source. |
| hMask | Specifies a handle to the GPU memory of the mask (containing the 'fSearch' values) |
| hY | Specifies a handle to the GPU memory of the destination. |
Definition at line 7114 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mask_batch | ( | int | n, |
| int | nBatch, | ||
| int | nMaskDim, | ||
| T | fSearch, | ||
| T | fReplace, | ||
| long | hX, | ||
| long | hMask, | ||
| long | hY | ||
| ) |
Mask the mask the batch of data in the source with the mask by replacing all values 'fSearch' found in the mask with 'fReplace' in the destination.
| n | Specifies the number of items. |
| nBatch | Specifies the batch size. |
| nMaskDim | Specifies the number of items in the mask. |
| fSearch | Specifies the value within the mask to replace. |
| fReplace | Specifies the replacement value. |
| hX | Specifies a handle to the GPU memory of the source. |
| hMask | Specifies a handle to the GPU memory of the mask (containing the 'fSearch' values) |
| hY | Specifies a handle to the GPU memory of the destination. |
Definition at line 7079 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.math_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData, | ||
| MATH_FUNCTION | function | ||
| ) |
Performs a Math function backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
| function | Specifies the mathematical function to use. |
Definition at line 8966 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.math_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| MATH_FUNCTION | function | ||
| ) |
Performs a Math function forward pass in Cuda.
Calculation ![$ Y[i] = function(X[i]) $](form_64.png)
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| function | Specifies the mathematical function to use. |
Definition at line 8949 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.matmul | ( | uint | nOuterCount, |
| int | m, | ||
| int | n, | ||
| int | k, | ||
| long | hA, | ||
| long | hB, | ||
| long | hC, | ||
| double | dfScale = 1.0, |
||
| bool | bTransA = false, |
||
| bool | bTransB = false |
||
| ) |
Perform matmul operation hC = matmul(hA, hB), where hA, hB and hC are all in row-major format.
| nOuterCount | Specifies the outer count (e.g. batch * channels) |
| m | Specifies the |
| n | |
| k | |
| hA | Specifies the handle to GPU memory holding the mxk matrix A (in row-major format) |
| hB | Specifies the handle to GPU memory holding the kxn matrix B (in row-major format) |
| hC | Specifies the handle to GPU memory holding the mxn matrix C (in row-major format) where the result is placed. |
| dfScale | Specifies the scale value applied to matrix B in hB (default = 1.0) |
| bTransA | Specifies to transpose matrix A (default = false). |
| bTransB | Specifies to transpose matrix B (default = false). |
Definition at line 6695 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.matrix_meancenter_by_column | ( | int | nWidth, |
| int | nHeight, | ||
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| bool | bNormalize = false |
||
| ) |
Mean center the data by columns, where each column is summed and then subtracted from each column value.
| nWidth | Number of columns in the matrix (dimension D) |
| nHeight | Number of rows in the matrix (dimension N) |
| hA | Input data matrix - N x D matrix (N rows, D columns) |
| hB | Column sums vector - D x 1 vector containing the sum of each column. |
| hY | Output data matrix - N x D matrix (N rows, D columns) containing mean centering of the input data matrix. |
| bNormalize | When true, each data item is divided by N to normalize each row item by column. |
Definition at line 10725 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.max | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY | ||
| ) |
Calculates the max of A and B and places the result in Y. This max is only computed on a per item basis, so the shape of Y = the shape of A and B and Y(0) contains the max of A(0) and B(0), etc.
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7669 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.max | ( | int | n, |
| long | hA, | ||
| out long | lPos, | ||
| int | nAOff = 0, |
||
| long | hWork = 0 |
||
| ) |
Finds the maximum value of A.
This function uses NVIDIA's Thrust.
| n | Specifies the number of items (not bytes) in the vectors A. |
| hA | Specifies a handle to the vector A in GPU memory. |
| lPos | Returns the position of the maximum value. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A (default = 0). |
| hWork | Optionally, specifies the handle to GPU memory in the size of A, which when specified is used in the extended version of max val. The extended version does not use thrust, and does not calculate 'lPos', which is always returned as -1 when using the extended version. (default = 0, use non extended version) |
Definition at line 7724 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.max_bwd | ( | int | n, |
| long | hAdata, | ||
| long | hBdata, | ||
| long | hYdiff, | ||
| long | hAdiff, | ||
| long | hBdiff | ||
| ) |
Propagates the Y diff back to the max of A or B and places the result in A if its data has the max, or B if its data has the max.
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hAdata | Specifies a handle to the data vector A in GPU memory. |
| hBdata | Specifies a handle to the data vector B in GPU memory. |
| hYdiff | Specifies a handle to the diff vector Y in GPU memory. |
| hAdiff | Specifies a handle to the mutable diff vector A in GPU memory. |
| hBdiff | Specifies a handle to the mutable diff vector B in GPU memory. |
Definition at line 7686 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.max_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| int | nIdx, | ||
| long | hMask, | ||
| long | hBottomDiff | ||
| ) |
Performs a max backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nIdx | Specifies the blob index used to test the mask. |
| hMask | Specifies a handle to the mask data in GPU. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 9758 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.max_fwd | ( | int | nCount, |
| long | hBottomDataA, | ||
| long | hBottomDataB, | ||
| int | nIdx, | ||
| long | hTopData, | ||
| long | hMask | ||
| ) |
Performs a max forward pass in Cuda.
Calculation: ![$ Y[i] = max(A[i], B[i]) $](form_74.png)
| nCount | Specifies the number of items. |
| hBottomDataA | Specifies a handle to the Bottom A data in GPU memory. |
| hBottomDataB | Specifies a handle to the Bottom B data in GPU memory. |
| nIdx | Specifies the blob index used to set the mask. |
| hTopData | Specifies a handle to the Top data in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU. |
Definition at line 9742 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mean_error_loss_bwd | ( | int | nCount, |
| long | hPredicted, | ||
| long | hTarget, | ||
| long | hBottomDiff, | ||
| MEAN_ERROR | merr | ||
| ) |
Performs a Mean Error Loss backward pass in Cuda.
The gradient is set to: +1 when predicted greater than target, -1 when predicted less than target, 0 when predicted equal to target. if propagate_down[1] == true.
| nCount | Specifies the number of items. |
| hPredicted | Specifies a handle to the predicted data in GPU memory. |
| hTarget | Specifies a handle to the target data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| merr | Specifies the type of mean error to run. |
Definition at line 8991 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.min | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY | ||
| ) |
Calculates the min of A and B and places the result in Y. This min is only computed on a per item basis, so the shape of Y = the shape of A and B and Y(0) contains the min of A(0) and B(0), etc.
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7702 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.min | ( | int | n, |
| long | hA, | ||
| out long | lPos, | ||
| int | nAOff = 0, |
||
| long | hWork = 0 |
||
| ) |
Finds the minimum value of A.
This function uses NVIDIA's Thrust.
| n | Specifies the number of items (not bytes) in the vectors A. |
| hA | Specifies a handle to the vector A in GPU memory. |
| lPos | Returns the position of the minimum value. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A (default = 0). |
| hWork | Optionally, specifies the handle to GPU memory in the size of A, which when specified is used in the extended version of max val. The extended version does not use thrust, and does not calculate 'lPos', which is always returned as -1 when using the extended version. (default = 0, use non extended version) |
Definition at line 7772 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.min_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| int | nIdx, | ||
| long | hMask, | ||
| long | hBottomDiff | ||
| ) |
Performs a min backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nIdx | Specifies the blob index used to test the mask. |
| hMask | Specifies a handle to the mask data in GPU. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 9794 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.min_fwd | ( | int | nCount, |
| long | hBottomDataA, | ||
| long | hBottomDataB, | ||
| int | nIdx, | ||
| long | hTopData, | ||
| long | hMask | ||
| ) |
Performs a min forward pass in Cuda.
Calculation: ![$ Y[i] = min(A[i], B[i]) $](form_75.png)
| nCount | Specifies the number of items. |
| hBottomDataA | Specifies a handle to the Bottom A data in GPU memory. |
| hBottomDataB | Specifies a handle to the Bottom B data in GPU memory. |
| nIdx | Specifies the blob index used to set the mask. |
| hTopData | Specifies a handle to the Top data in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU. |
Definition at line 9778 of file CudaDnn.cs.
| Tuple< double, double, double, double > MyCaffe.common.CudaDnn< T >.minmax | ( | int | n, |
| long | hA, | ||
| long | hWork1, | ||
| long | hWork2, | ||
| bool | bDetectNans = false, |
||
| int | nAOff = 0 |
||
| ) |
Finds the minimum and maximum values within A.
| n | Specifies the number of items (not bytes) in the vector A. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hWork1 | Specifies a handle to workspace data in GPU memory. To get the size of the workspace memory, call this function with hA = 0. |
| hWork2 | Specifies a handle to workspace data in GPU memory. To get the size of the workspace memory, call this function with hA = 0. |
| bDetectNans | Optionally, specifies whether or not to detect Nans. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A. |
Definition at line 7818 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.minmax | ( | int | n, |
| long | hA, | ||
| long | hWork1, | ||
| long | hWork2, | ||
| int | nK, | ||
| long | hMin, | ||
| long | hMax, | ||
| bool | bNonZeroOnly | ||
| ) |
Finds up to 'nK' minimum and maximum values within A.
| n | Specifies the number of items (not bytes) in the vector A. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hWork1 | Specifies a handle to workspace data in GPU memory. To get the size of the workspace memory, call this function with hA = 0. |
| hWork2 | Specifies a handle to workspace data in GPU memory. To get the size of the workspace memory, call this function with hA = 0. |
| nK | Specifies the number of min and max values to find. |
| hMin | Specifies a handle to host memory allocated with AllocHostBuffer in the length 'nK' where the min values are placed. |
| hMax | Specifies a handle to host memory allocated with AllocHostBuffer in the length 'nK' where the min values are placed. |
| bNonZeroOnly | Specifies whether or not to exclude zero from the min and max calculations. |
Definition at line 7843 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mish_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData, | ||
| double | dfThreshold, | ||
| int | nMethod = 0 |
||
| ) |
Performs a Mish backward pass in Cuda.
Computes the mish gradient  Note, see Wolfram Alpha with 'derivative of x * tanh(ln(1 + e^x))'
Note, see Wolfram Alpha with 'derivative of x * tanh(ln(1 + e^x))'
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
| dfThreshold | Specifies the threshold value. |
| nMethod | Optionally, specifies to run the new implementation when > 0. |
Definition at line 9035 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mish_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| double | dfThreshold | ||
| ) |
Performs a Mish forward pass in Cuda.
Computes the mish non-linearity  .
.
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| dfThreshold | Specifies the threshold value. |
Definition at line 9011 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mul | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| int | nAOff = 0, |
||
| int | nBOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Multiplies each element of A with each element of B and places the result in Y.
Y = A * B (element by element)
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A. |
| nBOff | Optionally, specifies an offset (in items, not bytes) into the memory of B. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 7334 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mul_scalar | ( | int | n, |
| double | fAlpha, | ||
| long | hY | ||
| ) |
Mutlipy each element of Y by a scalar.
Y = Y * alpha
| n | Specifies the number of items (not bytes) in the vectors Y. |
| fAlpha | Specifies the scalar in type double
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7374 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mul_scalar | ( | int | n, |
| float | fAlpha, | ||
| long | hY | ||
| ) |
Mutlipy each element of Y by a scalar.
Y = Y * alpha
| n | Specifies the number of items (not bytes) in the vectors Y. |
| fAlpha | Specifies the scalar in type float
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7388 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mul_scalar | ( | int | n, |
| T | fAlpha, | ||
| long | hY | ||
| ) |
Mutlipy each element of Y by a scalar.
Y = Y * alpha
| n | Specifies the number of items (not bytes) in the vectors Y. |
| fAlpha | Specifies the scalar in type 'T'. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7402 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.mulbsx | ( | int | n, |
| long | hA, | ||
| int | nAOff, | ||
| long | hX, | ||
| int | nXOff, | ||
| int | nC, | ||
| int | nSpatialDim, | ||
| bool | bTranspose, | ||
| long | hB, | ||
| int | nBOff | ||
| ) |
Multiply a matrix with a vector.
| n | Specifies the number of items. |
| hA | Specifies the matrix to multiply. |
| nAOff | Specifies the offset to apply to the GPU memory of hA. |
| hX | Specifies the vector to multiply. |
| nXOff | Specifies the offset to apply to the GPU memory of hX. |
| nC | Specifies the number of channels. |
| nSpatialDim | Specifies the spatial dimension. |
| bTranspose | Specifies whether or not to transpose the matrix. |
| hB | Specifies the output matrix. |
| nBOff | Specifies the offset to apply to the GPU memory of hB. |
Definition at line 6650 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.NcclAllReduce | ( | long | hNccl, |
| long | hStream, | ||
| long | hX, | ||
| int | nCount, | ||
| NCCL_REDUCTION_OP | op, | ||
| double | dfScale = 1.0 |
||
| ) |
Performs a reduction on all NCCL instances as specified by the reduction operation.
See Fast Multi-GPU collectives with NCCL.
| hNccl | Specifies a handle to an NCCL instance. |
| hStream | Specifies a handle to the stream to use for synchronization. |
| hX | Specifies a handle to the GPU data to reduce with the other instances of NCCL. |
| nCount | Specifies the number of items (not bytes) in the data. |
| op | Specifies the reduction operation to perform. |
| dfScale | Optionally, specifies a scaling to be applied to the final reduction. |
Definition at line 3442 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.NcclBroadcast | ( | long | hNccl, |
| long | hStream, | ||
| long | hX, | ||
| int | nCount | ||
| ) |
Broadcasts a block of GPU data to all NCCL instances.
See Fast Multi-GPU collectives with NCCL.
| hNccl | Specifies a handle to an NCCL instance. |
| hStream | Specifies a handle to the stream to use for synchronization. |
| hX | Specifies a handle to the GPU data to be broadcasted (or recieved). |
| nCount | Specifies the number of items (not bytes) in the data. |
Definition at line 3421 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.NcclInitializeMultiProcess | ( | long | hNccl | ) |
Initializes a set of NCCL instances for use in different processes.
See Fast Multi-GPU collectives with NCCL.
| hNccl | Specifies the handle of NCCL to initialize. |
Definition at line 3403 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.NcclInitializeSingleProcess | ( | params long[] | rghNccl | ) |
Initializes a set of NCCL instances for use in a single process.
See Fast Multi-GPU collectives with NCCL.
| rghNccl | Specifies the array of NCCL handles that will be working together. |
Definition at line 3370 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.nesterov_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hHistoryData, | ||
| T | fMomentum, | ||
| T | fLocalRate | ||
| ) |
Perform the Nesterov update
See Lecture 6c The momentum method by Hinton, et al., 2012, and Nesterov's Accelerated Gradient and Momentum as approximations to Regularised Update Descent by Botev, et al., 2016
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hHistoryData | Specifies a handle to the history data in GPU memory. |
| fMomentum | Specifies the momentum value. |
| fLocalRate | Specifies the local learning rate. |
Definition at line 10223 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.nllloss_bwd | ( | int | nCount, |
| long | hTopData, | ||
| long | hLabel, | ||
| long | hBottomDiff, | ||
| int | nOuterNum, | ||
| int | nDim, | ||
| int | nInnerNum, | ||
| long | hCounts, | ||
| int? | nIgnoreLabel | ||
| ) |
Performs NLL Loss backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hLabel | Specifies a handle to the label data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| nOuterNum | NEEDS REVIEW |
| nDim | NEEDS REVIEW |
| nInnerNum | NEEDS REVIEW |
| hCounts | Specifies a handle to the counts in GPU memory. |
| nIgnoreLabel | Optionally, specifies a label to ignore. |
Definition at line 9707 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.nllloss_fwd | ( | int | nCount, |
| long | hProbData, | ||
| long | hLabel, | ||
| long | hLossData, | ||
| int | nOuterNum, | ||
| int | nDim, | ||
| int | nInnerNum, | ||
| long | hCounts, | ||
| int? | nIgnoreLabel | ||
| ) |
Performs NLL Loss forward pass in Cuda.
| nCount | Specifies the number of items. |
| hProbData | Specifies a handle to the probability data in GPU memory. |
| hLabel | Specifies a handle to the label data in GPU memory. |
| hLossData | Specifies a handle to the loss data in GPU memory. |
| nOuterNum | NEEDS REVIEW |
| nDim | NEEDS REVIEW |
| nInnerNum | NEEDS REVIEW |
| hCounts | Specifies a handle to the counts in GPU memory. |
| nIgnoreLabel | Optionally, specifies a label to ignore. |
Definition at line 9673 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.permute | ( | int | nCount, |
| long | hBottom, | ||
| bool | bFwd, | ||
| long | hPermuteOrder, | ||
| long | hOldSteps, | ||
| long | hNewSteps, | ||
| int | nNumAxes, | ||
| long | hTop | ||
| ) |
Performs data permutation on the input and reorders the data which is placed in the output.
| nCount | Specifies the number of items. |
| hBottom | Specifies the input data. |
| bFwd | Specifies whether or not this is a forward (true) or backwards (true) operation. |
| hPermuteOrder | Specifies the permuation order values in GPU memory. |
| hOldSteps | Specifies the old step values in GPU memory. |
| hNewSteps | Specifies the new step values in GPU memory. |
| nNumAxes | Specifies the number of axes. |
| hTop | Specifies the output data. |
Definition at line 10082 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.pooling_bwd | ( | POOLING_METHOD | method, |
| int | nCount, | ||
| long | hTopDiff, | ||
| int | num, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nPooledHeight, | ||
| int | nPooledWidth, | ||
| int | nKernelH, | ||
| int | nKernelW, | ||
| int | nStrideH, | ||
| int | nStrideW, | ||
| int | nPadH, | ||
| int | nPadW, | ||
| long | hBottomDiff, | ||
| long | hMask, | ||
| long | hTopMask | ||
| ) |
Performs the backward pass for pooling using Cuda
| method | Specifies the pooling method. |
| nCount | Specifies the number of items in the bottom data. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| num | Specifies the number of inputs. |
| nChannels | Specifies the number of channels per input. |
| nHeight | Specifies the height of each input. |
| nWidth | Specifies the width of each input. |
| nPooledHeight | Specifies the height of the pooled data. |
| nPooledWidth | Specifies the width of the pooled data. |
| nKernelH | Specifies the height of the pooling kernel. |
| nKernelW | Specifies the width of the pooling kernel. |
| nStrideH | Specifies the stride along the height. |
| nStrideW | Specifies the stride along the width. |
| nPadH | Specifies the pad applied to the height. |
| nPadW | Specifies the pad applied to the width. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU memory. |
| hTopMask | Specifies a handle to the top mask data in GPU memory. |
Definition at line 8839 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.pooling_fwd | ( | POOLING_METHOD | method, |
| int | nCount, | ||
| long | hBottomData, | ||
| int | num, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nPooledHeight, | ||
| int | nPooledWidth, | ||
| int | nKernelH, | ||
| int | nKernelW, | ||
| int | nStrideH, | ||
| int | nStrideW, | ||
| int | nPadH, | ||
| int | nPadW, | ||
| long | hTopData, | ||
| long | hMask, | ||
| long | hTopMask | ||
| ) |
Performs the forward pass for pooling using Cuda
| method | Specifies the pooling method. |
| nCount | Specifies the number of items in the bottom data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| num | Specifies the number of inputs. |
| nChannels | Specifies the number of channels per input. |
| nHeight | Specifies the height of each input. |
| nWidth | Specifies the width of each input. |
| nPooledHeight | Specifies the height of the pooled data. |
| nPooledWidth | Specifies the width of the pooled data. |
| nKernelH | Specifies the height of the pooling kernel. |
| nKernelW | Specifies the width of the pooling kernel. |
| nStrideH | Specifies the stride along the height. |
| nStrideW | Specifies the stride along the width. |
| nPadH | Specifies the pad applied to the height. |
| nPadW | Specifies the pad applied to the width. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU memory. |
| hTopMask | Specifies a handle to the top mask data in GPU memory. |
Definition at line 8810 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.PoolingBackward | ( | long | hCuDnn, |
| long | hPoolingDesc, | ||
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform a pooling backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hPoolingDesc | Specifies a handle to the pooling descriptor. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4116 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.PoolingForward | ( | long | hCuDnn, |
| long | hPoolingDesc, | ||
| T | fAlpha, | ||
| long | hBottomDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDesc, | ||
| long | hTopData | ||
| ) |
Perform a pooling forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hPoolingDesc | Specifies a handle to the pooling descriptor. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDesc | Specifies a handle to the bottom tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDesc | Specifies a handle to the top tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4093 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.powx | ( | int | n, |
| long | hA, | ||
| double | fAlpha, | ||
| long | hY, | ||
| int | nAOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Calculates the A raised to the power alpha and places the result in Y.
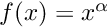
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| fAlpha | Specifies the scalar in type double
|
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Optionally, specifies the offset for hA memory (default = 0). |
| nYOff | Optionally, specifies the offset for hY memory (default = 0). |
Definition at line 7524 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.powx | ( | int | n, |
| long | hA, | ||
| float | fAlpha, | ||
| long | hY, | ||
| int | nAOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Calculates the A raised to the power alpha and places the result in Y.
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| fAlpha | Specifies the scalar in type float
|
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Optionally, specifies the offset for hA memory (default = 0). |
| nYOff | Optionally, specifies the offset for hY memory (default = 0). |
Definition at line 7541 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.powx | ( | int | n, |
| long | hA, | ||
| T | fAlpha, | ||
| long | hY, | ||
| int | nAOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Calculates the A raised to the power alpha and places the result in Y.
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| fAlpha | Specifies the scalar in type 'T'. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Optionally, specifies the offset for hA memory (default = 0). |
| nYOff | Optionally, specifies the offset for hY memory (default = 0). |
Definition at line 7558 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.prelu_bwd | ( | int | nCount, |
| int | nChannels, | ||
| int | nDim, | ||
| long | hTopDiff, | ||
| long | hBottomData, | ||
| long | hBottomDiff, | ||
| long | hSlopeData, | ||
| int | nDivFactor | ||
| ) |
Performs Parameterized Rectifier Linear Unit (ReLU) backward pass in Cuda.
| nCount | Specifies the number of items. |
| nChannels | Specifies the channels per input. |
| nDim | Specifies the dimension of each input. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hSlopeData | Specifies a handle to the slope data in GPU memory. |
| nDivFactor | Specifies the div factor applied to the channels. |
Definition at line 9585 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.prelu_bwd_param | ( | int | nCDim, |
| int | nNum, | ||
| int | nTopOffset, | ||
| long | hTopDiff, | ||
| long | hBottomData, | ||
| long | hBackBuffDiff | ||
| ) |
Performs Parameterized Rectifier Linear Unit (ReLU) backward param pass in Cuda.
| nCDim | NEEDS REVIEW |
| nNum | NEEDS REVIEW |
| nTopOffset | NEEDS REVIEW |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hBackBuffDiff | Specifies a handle to the back buffer diff in GPU memory. |
Definition at line 9562 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.prelu_fwd | ( | int | nCount, |
| int | nChannels, | ||
| int | nDim, | ||
| long | hBottomData, | ||
| long | hTopData, | ||
| long | hSlopeData, | ||
| int | nDivFactor | ||
| ) |
Performs Parameterized Rectifier Linear Unit (ReLU) forward pass in Cuda.
Calculation 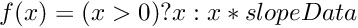
| nCount | Specifies the number of items. |
| nChannels | Specifies the channels per input. |
| nDim | Specifies the dimension of each input. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hSlopeData | Specifies a handle to the slope data in GPU memory. |
| nDivFactor | Specifies the div factor applied to the channels. |
Definition at line 9540 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.relu_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| T | fNegativeSlope | ||
| ) |
Performs a Rectifier Linear Unit (ReLU) backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| fNegativeSlope | Specifies the negative slope. |
Definition at line 9404 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.relu_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| T | fNegativeSlope | ||
| ) |
Performs a Rectifier Linear Unit (ReLU) forward pass in Cuda.
Calculation 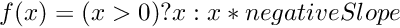
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| fNegativeSlope | Specifies the negative slope. |
Definition at line 9383 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ReLUBackward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform a ReLU backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4598 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ReLUForward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDataDesc, | ||
| long | hTopData | ||
| ) |
Perform a ReLU forward pass.
See Rectifier Nonlinearities Improve Neural Network Acoustic Models by Maas, A. L., Hannun, A. Y., and Ng, A. Y. (2013), In ICML Workshop on Deep Learning for Audio, Speech, and Language Processing.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4576 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ReportMemory | ( | Log | log, |
| string | strLocation | ||
| ) |
Report the memory use on the current GPU managed by the CudaDnn object.
| log | Specifies the output log. |
| strLocation | Specifies the location of the memory test. |
Definition at line 11236 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ResetDevice | ( | ) |
Reset the current device.
IMPORTANT: This function will delete all memory and state information on the current device, which may cause other CudaDnn instances using the same device, to fail. For that reason, it is recommended to only call this function when testing.
Definition at line 2079 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.ResetGhostMemory | ( | ) |
Resets the ghost memory by enabling it if this instance was configured to use ghost memory.
Definition at line 1783 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rmsprop_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hHistoryData, | ||
| T | fRmsDecay, | ||
| T | fDelta, | ||
| T | fLocalRate | ||
| ) |
Perform the RMSProp update
See Lecture 6e rmsprop: Divide the gradient by a running average of its recent magnitude by Tieleman and Hinton, 2012, and RMSProp and equilibrated adaptive learning rates for non-convex optimization by Dauphin, et al., 2015
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hHistoryData | Specifies a handle to the history data in GPU memory. |
| fRmsDecay | Specifies the decay value used by the Solver. MeanSquare(t) = 'rms_decay' * MeanSquare(t-1) + (1 - 'rms_decay') * SquareGradient(t). |
| fDelta | Specifies the numerical stability factor. |
| fLocalRate | Specifies the local learning rate. |
Definition at line 10334 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_bernoulli | ( | int | n, |
| double | fNonZeroProb, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a bernoulli random distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fNonZeroProb | Specifies the probability that a given value is set to non zero. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8631 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_bernoulli | ( | int | n, |
| float | fNonZeroProb, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a bernoulli random distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fNonZeroProb | Specifies the probability that a given value is set to non zero. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8645 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_bernoulli | ( | int | n, |
| T | fNonZeroProb, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a bernoulli random distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fNonZeroProb | Specifies the probability that a given value is set to non zero. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8659 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_gaussian | ( | int | n, |
| double | fMu, | ||
| double | fSigma, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a gaussian random distribution.
This function uses NVIDIA's cuRand. See also Guassian Distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fMu | Specifies the mean of the distribution with a type of double
|
| fSigma | Specifies the standard deviation of the distribution with a type of double
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8578 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_gaussian | ( | int | n, |
| float | fMu, | ||
| float | fSigma, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a gaussian random distribution.
This function uses NVIDIA's cuRand. See also Guassian Distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fMu | Specifies the mean of the distribution with a type of float
|
| fSigma | Specifies the standard deviation of the distribution with a type of float
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8593 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_gaussian | ( | int | n, |
| T | fMu, | ||
| T | fSigma, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a gaussian random distribution.
This function uses NVIDIA's cuRand. See also Guassian Distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fMu | Specifies the mean of the distribution with a type of 'T'. |
| fSigma | Specifies the standard deviation of the distribution with a type of 'T'. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8608 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_setseed | ( | long | lSeed | ) |
Sets the random number generator seed used by random number operations.
This function uses NVIDIA's cuRand
| lSeed | Specifies the random number generator seed. |
Definition at line 8506 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_uniform | ( | int | n, |
| double | fMin, | ||
| double | fMax, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a uniform random distribution.
This function uses NVIDIA's cuRand. See also Uniform Distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fMin | Specifies the minimum value of the distribution with a type of double
|
| fMax | Specifies the maximum value of the distribution with a type of double
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8524 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_uniform | ( | int | n, |
| float | fMin, | ||
| float | fMax, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a uniform random distribution.
This function uses NVIDIA's cuRand. See also Uniform Distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fMin | Specifies the minimum value of the distribution with a type of float
|
| fMax | Specifies the maximum value of the distribution with a type of float
|
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8539 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.rng_uniform | ( | int | n, |
| T | fMin, | ||
| T | fMax, | ||
| long | hY | ||
| ) |
Fill Y with random numbers using a uniform random distribution.
This function uses NVIDIA's cuRand. See also Uniform Distribution.
| n | Specifies the number of items (not bytes) in the vector X. |
| fMin | Specifies the minimum value of the distribution with a type of 'T'. |
| fMax | Specifies the maximum value of the distribution with a type of 'T'. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8554 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.Rnn8Backward | ( | long | hCuDnn, |
| long | hRnn, | ||
| long | hY, | ||
| long | hdY, | ||
| long | hX, | ||
| long | hdX, | ||
| long | hhX, | ||
| long | hdhY, | ||
| long | hdhX, | ||
| long | hcX, | ||
| long | hdcY, | ||
| long | hdcX, | ||
| long | hWt, | ||
| long | hdWt, | ||
| long | hWork, | ||
| long | hReserved | ||
| ) |
Calculate the backward pass through the RNN8 for both data and weights.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnn | Specifies the handle to the RNN8 created with CreateRnn8. |
| hY | Specifies a handle to the GPU memory of shape (SeqLen, BatchSize, Outputs) containing the outputs from the forward. |
| hdY | Specifies a handle to the GPU memory of shape (SeqLen, BatchSize, Outputs) containing the inbound gradients for Y. |
| hX | Specifies a handle to the GPU memory of shape (SeqLen, BatchSize, Inputs) containing the inputs. |
| hdX | Specifies a handle to the GPU memory of shape (SeqLen, BatchSize, Outputs) where the outbound, calculated gradients for X are placed. |
| hhX | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) containing the hidden inputs. |
| hdhY | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) containing the inbound gradients for hidden. |
| hdhX | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) where the outbound, calculated gradients for hidden are placed. |
| hcX | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) containing the hidden cell inputs. |
| hdcY | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) containing the inbound sgradients for the cell hidden. |
| hdcX | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) where the outbound, calculated gradients for cell hidden are placed. |
| hWt | Specifies a handle to the GPU memory of size szWt calculated with GetRnn8MemorySizes, containing the weights. |
| hdWt | Specifies a handle to the GPU memory of size szWt calculated with GetRnn8MemorySizes, where the weight gradients are placed. |
| hWork | Specifies a handle to the GPU memory of size szWork calculated with GetRnn8MemorySizes, used as temporary work data. |
| hReserved | Specifies a handle to the GPU memory of size szReserved calculated with GetRnn8MemorySizes, used as temporary reserve data. |
Definition at line 5300 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.Rnn8Forward | ( | long | hCuDnn, |
| long | hRnn, | ||
| long | hX, | ||
| long | hY, | ||
| long | hhX, | ||
| long | hhY, | ||
| long | hcX, | ||
| long | hcY, | ||
| long | hWts, | ||
| long | hWork, | ||
| long | hReserved | ||
| ) |
Calculate the forward pass through the RNN8.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnn | Specifies the handle to the RNN8 created with CreateRnn8. |
| hX | Specifies a handle to the GPU memory of shape (SeqLen, BatchSize, Inputs) containing the inputs. |
| hY | Specifies a handle to the GPU memory of shape (SeqLen, BatchSize, Outputs) where the outputs are placed. |
| hhX | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) containing the hidden inputs. |
| hhY | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) where the hidden outputs are placed. |
| hcX | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) containing the hidden cell inputs. |
| hcY | Specifies a handle to the GPU memory of shape (BatchSize, Hidden) where the hidden cell outputs are placed. |
| hWts | Specifies a handle to the GPU memory of size szWt calculated with GetRnn8MemorySizes, containing the weights. |
| hWork | Specifies a handle to the GPU memory of size szWork calculated with GetRnn8MemorySizes, used as temporary work data. |
| hReserved | Specifies a handle to the GPU memory of size szReserved calculated with GetRnn8MemorySizes, used as temporary reserve data. |
Definition at line 5273 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.RnnBackwardData | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| long | hYDesc, | ||
| long | hYData, | ||
| long | hYDiff, | ||
| long | hHyDesc, | ||
| long | hHyDiff, | ||
| long | hCyDesc, | ||
| long | hCyDiff, | ||
| long | hWtDesc, | ||
| long | hWtData, | ||
| long | hHxDesc, | ||
| long | hHxData, | ||
| long | hCxDesc, | ||
| long | hCxData, | ||
| long | hXDesc, | ||
| long | hXDiff, | ||
| long | hdHxDesc, | ||
| long | hHxDiff, | ||
| long | hdCxDesc, | ||
| long | hCxDiff, | ||
| long | hWorkspace, | ||
| ulong | nWsCount, | ||
| long | hReserved, | ||
| ulong | nResCount | ||
| ) |
Run the RNN backward pass through the data.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| hYDesc | Specifies a handle to the output data descriptor. |
| hYData | Specifies a handle to the output GPU data. |
| hYDiff | Specifies a handle to the output GPU gradients. |
| hHyDesc | Specifies a handle to the output hidden descriptor. |
| hHyDiff | Specifies a handle to the output hidden gradients. |
| hCyDesc | Specifies a handle to the output cont descriptor. |
| hCyDiff | Specifies a handle to the output cont gradients. |
| hWtDesc | Specifies a handle to the weight descriptor. |
| hWtData | Specifies a handle to the weight data. |
| hHxDesc | Specifies a handle to the hidden data descriptor. |
| hHxData | Specifies a handle to the hidden GPU data. |
| hCxDesc | Specifies a handle to the cont data descriptor. |
| hCxData | Specifies a handle to the cont GPU data. |
| hXDesc | Specifies a handle to the input data descriptor. |
| hXDiff | Specifies a handle to the input GPU gradients. |
| hdHxDesc | Specifies a handle to the input hidden descriptor for the gradients. |
| hHxDiff | Specifis a handle to the input hidden GPU gradients. |
| hdCxDesc | Specifies a handle to the input cont descriptor of the gradients. |
| hCxDiff | Specifies a handle to the input cont GPU gradients. |
| hWorkspace | Specifies a handle to the workspace GPU memory. |
| nWsCount | Specifies the number of items within the workspace. |
| hReserved | Specifies a handle to the reserved GPU memory. |
| nResCount | Specifies the number of items within the reserved memory. |
Definition at line 4981 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.RnnBackwardWeights | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| long | hXDesc, | ||
| long | hXData, | ||
| long | hHxDesc, | ||
| long | hHxData, | ||
| long | hYDesc, | ||
| long | hYData, | ||
| long | hWorkspace, | ||
| ulong | nWsCount, | ||
| long | hWtDesc, | ||
| long | hWtDiff, | ||
| long | hReserved, | ||
| ulong | nResCount | ||
| ) |
Run the RNN backward pass on the weights.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| hXDesc | Specifies a handle to the input data descriptor. |
| hXData | Specifies a handle to the input GPU data. |
| hHxDesc | Specifies a handle to the hidden data descriptor. |
| hHxData | Specifies a handle to the hidden GPU data. |
| hYDesc | Specifies a handle to the output data descriptor. |
| hYData | Specifies a handle to the output GPU data. |
| hWorkspace | Specifies a handle to the workspace GPU memory. |
| nWsCount | Specifies the number of items within the workspace. |
| hWtDesc | Specifies a handle to the weight descriptor. |
| hWtDiff | Specifies a handle to the weight gradients. |
| hReserved | Specifies a handle to the reserved GPU memory. |
| nResCount | Specifies the number of items within the reserved memory. |
Definition at line 5080 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.RnnForward | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| long | hXDesc, | ||
| long | hXData, | ||
| long | hHxDesc, | ||
| long | hHxData, | ||
| long | hCxDesc, | ||
| long | hCxData, | ||
| long | hWtDesc, | ||
| long | hWtData, | ||
| long | hYDesc, | ||
| long | hYData, | ||
| long | hHyDesc, | ||
| long | hHyData, | ||
| long | hCyDesc, | ||
| long | hCyData, | ||
| long | hWorkspace, | ||
| ulong | nWsCount, | ||
| long | hReserved, | ||
| ulong | nResCount, | ||
| bool | bTraining | ||
| ) |
Run the RNN through a forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| hXDesc | Specifies a handle to the input data descriptor. |
| hXData | Specifies a handle to the input GPU data. |
| hHxDesc | Specifies a handle to the hidden data descriptor. |
| hHxData | Specifies a handle to the hidden GPU data. |
| hCxDesc | Specifies a handle to the cont data descriptor. |
| hCxData | Specifies a handle to the cont GPU data. |
| hWtDesc | Specifies a handle to the weight descriptor. |
| hWtData | Specifies a handle to the weight data. |
| hYDesc | Specifies a handle to the output data descriptor. |
| hYData | Specifies a handle to the output GPU data. |
| hHyDesc | Specifies a handle to the output hidden descriptor. |
| hHyData | Specifies a handle to the output hidden data. |
| hCyDesc | Specifies a handle to the output cont descriptor. |
| hCyData | Specifies a handle to the output cont data. |
| hWorkspace | Specifies a handle to the workspace GPU memory. |
| nWsCount | Specifies the number of items within the workspace. |
| hReserved | Specifies a handle to the reserved GPU memory. |
| nResCount | Specifies the number of items within the reserved memory. |
| bTraining | Specifies the whether the forward pass is during taining or not. |
Definition at line 4881 of file CudaDnn.cs.
| T[] MyCaffe.common.CudaDnn< T >.RunExtension | ( | long | hExtension, |
| long | lfnIdx, | ||
| T[] | rgParam | ||
| ) |
Run a function on the extension specified.
| hExtension | Specifies the handle to the extension created with CreateExtension. |
| lfnIdx | Specifies the extension function to run. |
| rgParam | Specifies the parameters to pass to the extension. |
Definition at line 3489 of file CudaDnn.cs.
| T[] MyCaffe.common.CudaDnn< T >.RunMemoryTest | ( | long | h, |
| MEMTEST_TYPE | type, | ||
| ulong | ulBlockStartOffset, | ||
| ulong | ulBlockCount, | ||
| bool | bVerbose, | ||
| bool | bWrite, | ||
| bool | bReadWrite, | ||
| bool | bRead | ||
| ) |
The RunMemoryTest method runs the memory test from the block start offset through the block count on the memory previously allocated using CreateMemoryTest.
| h | Specifies the handle to the memory test data. |
| type | Specifies the type of memory test to run. |
| ulBlockStartOffset | Specifies the block start offset (offset into the total blocks returned by CreateMemoryTest). |
| ulBlockCount | Specifies the number of blocks to test. |
| bVerbose | When disabled, the memory test is just run once and the number of errors is returned. When eanbled, the memory test is run twice and the erroring adresses are returned along with the error count. |
| bWrite | Specifies to perform a write test. |
| bReadWrite | Specifies to perform a read/write test. |
| bRead | Specifies to peroform a read test. |
Definition at line 3123 of file CudaDnn.cs.
| bool MyCaffe.common.CudaDnn< T >.RunPCA | ( | long | hPCA, |
| int | nSteps, | ||
| out int | nCurrentK, | ||
| out int | nCurrentIteration | ||
| ) |
Runs a number of steps of the iterative PCA algorithm.
See Parallel GPU Implementation of Iterative PCA Algorithms by Mircea Andrecut
| hPCA | Specifies a handle to the PCA instance to use. |
| nSteps | Specifies the number of steps to run. |
| nCurrentK | Returns the current component value. |
| nCurrentIteration | Returns the current iteration. |
Definition at line 5417 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scal | ( | int | n, |
| double | fAlpha, | ||
| long | hX, | ||
| int | nXOff = 0 |
||
| ) |
Scales the data in X by a scaling factor.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scaling factor to apply to vector X, where the scaling factor is of type double
|
| hX | Specifies a handle to the vector X in GPU memory. |
| nXOff | Specifies an offset (in items, not bytes) into the memory of X. |
Definition at line 6767 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scal | ( | int | n, |
| float | fAlpha, | ||
| long | hX, | ||
| int | nXOff = 0 |
||
| ) |
Scales the data in X by a scaling factor.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scaling factor to apply to vector X, where the scaling factor is of type float
|
| hX | Specifies a handle to the vector X in GPU memory. |
| nXOff | Specifies an offset (in items, not bytes) into the memory of X. |
Definition at line 6782 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scal | ( | int | n, |
| T | fAlpha, | ||
| long | hX, | ||
| int | nXOff = 0 |
||
| ) |
Scales the data in X by a scaling factor.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scaling factor to apply to vector X, where the scaling factor is of type 'T'. |
| hX | Specifies a handle to the vector X in GPU memory. |
| nXOff | Specifies an offset (in items, not bytes) into the memory of X. |
Definition at line 6797 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scale | ( | int | n, |
| double | fAlpha, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Scales the values in X and places them in Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scale value in type double
|
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6925 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scale | ( | int | n, |
| float | fAlpha, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Scales the values in X and places them in Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scale value in type float
|
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 6940 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scale | ( | int | n, |
| T | fAlpha, | ||
| long | hX, | ||
| long | hY, | ||
| int | nXOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Scales the values in X and places them in Y.
This function uses NVIDIA's cuBlas.
| n | Specifies the number of items (not bytes) in the vector X and Y. |
| fAlpha | Specifies the scale value in type 'T'. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nXOff | Optionally, specifies an offset (in items, not bytes) into the memory of X. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 6957 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scale_fwd | ( | int | nCount, |
| long | hX, | ||
| long | hScaleData, | ||
| int | nScaleDim, | ||
| int | nInnerDim, | ||
| long | hY, | ||
| long | hBiasData = 0 |
||
| ) |
Performs a scale forward pass in Cuda.
Calculation: ![$ f(x) = \begin{cases} x * scaleData[(i / nInnerDim) \mod nScaleDim], & \text{if } hBias == 0\\ x * scaleData[(i / nInnerDim) \mod nScaleDim] + biasData[(i / nInnerDim) \mod nScaleDim] & \text{otherwise} \end{cases} $](form_76.png)
| nCount | Specifies the number of items. |
| hX | Specifies the input data X in GPU memory. |
| hScaleData | |
| nScaleDim | |
| nInnerDim | |
| hY | Specifies the output data Y in GPU memory. |
| hBiasData | Optionally, specifies the bias data in GPU memory. |
Definition at line 9983 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.scale_to_range | ( | int | n, |
| long | hX, | ||
| long | hY, | ||
| double | fMin, | ||
| double | fMax | ||
| ) |
Scales the values in X and places the result in Y (can also run inline where X = Y).
| n | Specifies the number of items (not bytes) in the vector X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| fMin | Specifies the minimum of the new range. |
| fMax | Specifies the maximum of the new range. |
Definition at line 6973 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.serf_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData, | ||
| double | dfThreshold | ||
| ) |
Performs a Serf backward pass in Cuda.
Computes the serf gradient 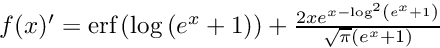
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
| dfThreshold | Specifies the threshold value. |
Definition at line 9267 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.serf_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData, | ||
| double | dfThreshold | ||
| ) |
Performs a Serf forward pass in Cuda.
Computes the serf non-linearity 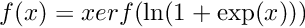 .
.
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| dfThreshold | Specifies the threshold value. |
Definition at line 9245 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.set | ( | int | nCount, |
| long | hHandle, | ||
| double | fVal, | ||
| int | nIdx = -1 |
||
| ) |
Set the values of GPU memory to a specified value of type
double.
| nCount | Specifies the number of items to set. |
| hHandle | Specifies a handle to the memory on the GPU. |
| fVal | Specifies the value to set. |
| nIdx | When -1, all values in the GPU memory are set to the fVal value, otherwise, only the value at the index nIdx is set to the value. |
Definition at line 5897 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.set | ( | int | nCount, |
| long | hHandle, | ||
| float | fVal, | ||
| int | nIdx = -1 |
||
| ) |
Set the values of GPU memory to a specified value of type
float.
| nCount | Specifies the number of items to set. |
| hHandle | Specifies a handle to the memory on the GPU. |
| fVal | Specifies the value to set. |
| nIdx | When -1, all values in the GPU memory are set to the fVal value, otherwise, only the value at the index nIdx is set to the value. |
Definition at line 5909 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.set | ( | int | nCount, |
| long | hHandle, | ||
| T | fVal, | ||
| int | nIdx = -1, |
||
| int | nXOff = 0 |
||
| ) |
Set the values of GPU memory to a specified value of type 'T'.
| nCount | Specifies the number of items to set. |
| hHandle | Specifies a handle to the memory on the GPU. |
| fVal | Specifies the value to set. |
| nIdx | When -1, all values in the GPU memory are set to the fVal value, otherwise, only the value at the index nIdx is set to the value. |
| nXOff | Optionally specifies an offset into the GPU memory where the set starts. |
Definition at line 5922 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.set_bounds | ( | int | n, |
| double | dfMin, | ||
| double | dfMax, | ||
| long | hX | ||
| ) |
Set the bounds of all items within the data to a set range of values.
| n | Specifies the number of items. |
| dfMin | Specifies the minimum value. |
| dfMax | Specifies the maximum value. |
| hX | Specifies a handle to the GPU data to be bound. |
Definition at line 6732 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetConvolutionDesc | ( | long | hHandle, |
| int | hPad, | ||
| int | wPad, | ||
| int | hStride, | ||
| int | wStride, | ||
| int | hDilation, | ||
| int | wDilation, | ||
| bool | bUseTensorCores, | ||
| bool | bHalf = false |
||
| ) |
Set the values of a convolution descriptor.
| hHandle | Specifies the handle to the convolution descriptor. |
| hPad | Specifies the pad applied to the height. |
| wPad | Specifies the pad applied to the width. |
| hStride | Specifies the stride of the height. |
| wStride | Specifies the stride of the width. |
| hDilation | Specifies the dilation of the height (default = 1). |
| wDilation | Specifies the dilation of the width (default = 1). |
| bUseTensorCores | Optionally, specifies whether or not to use the Tensor Cores (if available). |
| bHalf | Optionally, specifies whether or not to use the FP16 half data type. |
Definition at line 3785 of file CudaDnn.cs.
|
static |
Used to optionally set the default path to the Low-Level Cuda Dnn DLL file.
| strPath | Specifies the file path to the Low-Level Cuda Dnn DLL file to use. |
Definition at line 1890 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetDeviceID | ( | int | nDeviceID = -1, |
| DEVINIT | flags = DEVINIT.NONE, |
||
| long? | lSeed = null |
||
| ) |
Set the device ID used by the current instance of CudaDnn.
| nDeviceID | Specifies the zero-based device (GPU) id. When -1, the device ID is set to the device ID used to create the instance of CudaDnn. |
| flags | Optionally, specifies the initialization flags. |
| lSeed | Optionally, specifies the random number generator seed. |
Definition at line 1960 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetDropoutDesc | ( | long | hCuDnn, |
| long | hDropoutDesc, | ||
| double | dfDropout, | ||
| long | hStates, | ||
| long | lSeed | ||
| ) |
Set the dropout descriptor values.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hDropoutDesc | Specifies a handle to the dropout descriptor. |
| dfDropout | Specifies the droput probability (0.5 = 50%). |
| hStates | Specifies a handle to the state data in GPU memory. |
| lSeed | Specifies the random number-generator seed. |
Definition at line 4237 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetFilterDesc | ( | long | hHandle, |
| int | n, | ||
| int | c, | ||
| int | h, | ||
| int | w, | ||
| bool | bHalf = false |
||
| ) |
Sets the values of a filter descriptor.
| hHandle | Specifies the handle to the filter descriptor. |
| n | Specifies the number of items. |
| c | Specifies the number of channels in each item. |
| h | Specifies the height of each item. |
| w | Specifies the width of each item. |
| bHalf | Optionally, specifies whether or not to use the FP16 half data type. |
Definition at line 3735 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetFilterNdDesc | ( | long | hHandle, |
| int[] | rgDim, | ||
| bool | bHalf = false |
||
| ) |
Sets the values of a filter descriptor.
| hHandle | Specifies the handle to the filter descriptor. |
| rgDim | Specifies the dimensions of the data. |
| bHalf | Optionally, specifies whether or not to use the FP16 half data type. |
Definition at line 3700 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetHostMemory | ( | long | hMem, |
| T[] | rgSrc | ||
| ) |
Copies an array of type 'T' into a block of already allocated host memory.
| hMem | Specifies the handle to the host memory. |
| rgSrc | Specifies the array of type 'T' to copy. |
Definition at line 2995 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetLRNDesc | ( | long | hHandle, |
| uint | nSize, | ||
| double | fAlpha, | ||
| double | fBeta, | ||
| double | fK | ||
| ) |
Set the LRN descriptor values.
| hHandle | Specifies a handle to an LRN descriptor. |
| nSize | Specifies the normalization window width. Default = 5. |
| fAlpha | Specifies the alpha variance. Caffe default = 1.0; cuDnn default = 1e-4. |
| fBeta | Specifies the beta power parameter. Caffe and cuDnn default = 0.75. |
| fK | Specifies the normalization 'k' parameter. Caffe default = 1.0; cuDnn default = 2.0. |
Definition at line 4342 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemory | ( | long | hMem, |
| double[] | rgSrc, | ||
| long | hStream = 0 |
||
| ) |
Copies an array of double into a block of already allocated GPU memory.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| rgSrc | Specifies the array of double to copy. |
| hStream | Optionally specifies the stream to use for the copy operation. |
Definition at line 2757 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemory | ( | long | hMem, |
| float[] | rgSrc, | ||
| long | hStream = 0 |
||
| ) |
Copies an array of float into a block of already allocated GPU memory.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| rgSrc | Specifies the array of float to copy. |
| hStream | Optionally specifies the stream to use for the copy operation. |
Definition at line 2769 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemory | ( | long | hMem, |
| List< double > | rg | ||
| ) |
Copies a list of doubles into a block of already allocated GPU memory.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| rg | Specifies the list of doubles to copy. |
Definition at line 2734 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemory | ( | long | hMem, |
| List< float > | rg | ||
| ) |
Copies a list of float into a block of already allocated GPU memory.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| rg | Specifies the list of float to copy. |
Definition at line 2745 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemory | ( | long | hMem, |
| T[] | rgSrc, | ||
| long | hStream = 0, |
||
| int | nCount = -1 |
||
| ) |
Copies an array of type 'T' into a block of already allocated GPU memory.
| hMem | Specifies the handle to the GPU memory. |
| rgSrc | Specifies the array of type 'T' to copy. |
| hStream | Optionally specifies the stream to use for the copy operation. |
| nCount | Optionally, specifies a count of items to retrieve. |
Definition at line 2781 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemoryAt | ( | long | hMem, |
| double[] | rgSrc, | ||
| int | nOffset | ||
| ) |
Copies an array of double into a block of already allocated GPU memory starting at a specific offset.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| rgSrc | Specifies the array of double to copy. |
| nOffset | Specifies offset within the GPU memory from where the copy is to start. |
Definition at line 2860 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemoryAt | ( | long | hMem, |
| float[] | rgSrc, | ||
| int | nOffset | ||
| ) |
Copies an array of float into a block of already allocated GPU memory starting at a specific offset.
This function converts the input array into the base type 'T' for which the instance of CudaDnn was defined.
| hMem | Specifies the handle to the GPU memory. |
| rgSrc | Specifies the array of float to copy. |
| nOffset | Specifies offset within the GPU memory from where the copy is to start. |
Definition at line 2872 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetMemoryAt | ( | long | hMem, |
| T[] | rgSrc, | ||
| int | nOffset | ||
| ) |
Copies an array of type 'T' into a block of already allocated GPU memory starting at a specific offset.
| hMem | Specifies the handle to the GPU memory. |
| rgSrc | Specifies the array of type 'T' to copy. |
| nOffset | Specifies offset within the GPU memory from where the copy is to start. |
Definition at line 2883 of file CudaDnn.cs.
| T[] MyCaffe.common.CudaDnn< T >.SetPixel | ( | long | hMem, |
| int | nCount, | ||
| bool | bReturnOriginal, | ||
| int | nOffset, | ||
| params Tuple< int, T >[] | rgPixel | ||
| ) |
Set a pixel value where each pixel is defined a set index, value tuple.
| hMem | Specifies the memory where the values are set. |
| nCount | Specifies the number of allocated items in the memory. |
| bReturnOriginal | Specifies whether or not to return the original values (before setting). |
| nOffset | Specifies the offset of where the first pixel data starts. |
| rgPixel | Specifies the pixel values. |
Definition at line 2933 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetPoolingDesc | ( | long | hHandle, |
| PoolingMethod | method, | ||
| int | h, | ||
| int | w, | ||
| int | hPad, | ||
| int | wPad, | ||
| int | hStride, | ||
| int | wStride | ||
| ) |
Set the values of a pooling descriptor.
| hHandle | Specifies the handle to the convolution descriptor. |
| method | Specifies the pooling method to use. |
| h | Specifies the pooling area height. |
| w | Specifies the pooling area width. |
| hPad | Specifies the height padding. |
| wPad | Specifies the width padding. |
| hStride | Specifies the height stride. |
| wStride | Specifies the width stride. |
Definition at line 4074 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetRandomSeed | ( | long | lSeed | ) |
Set the random number generator seed.
| lSeed | Specifies the seed to set. |
Definition at line 1990 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetRnn8 | ( | long | hCuDnn, |
| long | hRnn, | ||
| bool | bTraining, | ||
| RNN_DATALAYOUT | layout, | ||
| RNN_MODE | cellMode, | ||
| RNN_BIAS_MODE | biasMode, | ||
| int | nSequenceLen, | ||
| int | nBatchSize, | ||
| int | nInputs, | ||
| int | nHidden, | ||
| int | nOutputs, | ||
| int | nProjection, | ||
| int | nNumLayers, | ||
| float | fDropout, | ||
| ulong | lSeed, | ||
| bool | bBidirectional = false |
||
| ) |
Set the RNN8 parameters.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnn | Specifies the handle to the RNN8 created with CreateRnn8. |
| bTraining | Specifies true for training and false for inference. |
| layout | Specifies the data layout ordering. |
| cellMode | Specifies the cell mode (RELU, TANH, LSTM or GRU), |
| biasMode | Specifies the bias mode (default = RNN_DOUBLE_BIAS) |
| nSequenceLen | Specifies the sequence length. |
| nBatchSize | Specifies the batch size. |
| nInputs | Specifies the number of inputs. X input is of size (SeqLen, BatchSize, Inputs) |
| nHidden | Specifies the number of hidden. H and C are of size (BatchSize, Hidden) |
| nOutputs | Specifies the number of outputs. Y output is of size (SeqLen, BatchSize, Outputs) |
| nProjection | Specifies the projection size. |
| nNumLayers | Specifies the number of layers. |
| fDropout | Specifies the dropout ratio. |
| lSeed | Specifies the dropout seed. |
| bBidirectional | Specifies unidirectional (false) or bidirectional (true), (default = false) |
Definition at line 5205 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetRnnDataDesc | ( | long | hRnnDataDesc, |
| RNN_DATALAYOUT | layout, | ||
| int | nMaxSeqLen, | ||
| int | nBatchSize, | ||
| int | nVectorSize, | ||
| bool | bBidirectional = false, |
||
| int[] | rgSeqLen = null |
||
| ) |
Sets the RNN Data Descriptor values.
| hRnnDataDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| layout | Specifies the input data layout (either SEQUENCE major or BATCH major). |
| nMaxSeqLen | Specifies the maximum sequence length. |
| nBatchSize | Specifies the batch count. |
| nVectorSize | Specifies the input vector count. |
| bBidirectional | Specifies whether the Rnn is bidirectional or not (default = false). |
| rgSeqLen | Specifies the sequence lengths - currently this should be null which sets all sequence lengths to nMaxSeqLen. |
Definition at line 4692 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetRnnDesc | ( | long | hCuDnn, |
| long | hRnnDesc, | ||
| int | nHiddenCount, | ||
| int | nNumLayers, | ||
| long | hDropoutDesc, | ||
| RNN_MODE | mode, | ||
| bool | bUseTensorCores, | ||
| RNN_DIRECTION | direction = RNN_DIRECTION.RNN_UNIDIRECTIONAL |
||
| ) |
Sets the RNN Descriptor values.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| hRnnDesc | Specifies the handle to the RNN descriptor created with CreateRnnDesc |
| nHiddenCount | Specifies the hidden input (typically the input) count. |
| nNumLayers | Specifies the number of layers. |
| hDropoutDesc | Specifies the handle to the Droput descriptor (or 0 to ignore). The droput descriptor is only used with two or more layers. |
| mode | Specifies the RNN_MODE (LSTM, RNN_RELU, RNN_TANH) to use. |
| bUseTensorCores | Optionally, specifies whether or not to use the Tensor Cores (if available). |
| direction | Optionally, specifies the direction of the RNN; Unidirectional or BiDirectional. |
Definition at line 4770 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetTensorDesc | ( | long | hHandle, |
| int | n, | ||
| int | c, | ||
| int | h, | ||
| int | w, | ||
| bool | bHalf = false |
||
| ) |
Sets the values of a tensor descriptor.
| hHandle | Specifies the handle to the tensor descriptor. |
| n | Specifies the number of items. |
| c | Specifies the number of channels in each item. |
| h | Specifies the height of each item. |
| w | Specifies the width of each item. |
| bHalf | Optionally, specifies whether or not to use the FP16 half data type. |
Definition at line 3599 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetTensorDesc | ( | long | hHandle, |
| int | n, | ||
| int | c, | ||
| int | h, | ||
| int | w, | ||
| int | nStride, | ||
| int | cStride, | ||
| int | hStride, | ||
| int | wStride, | ||
| bool | bHalf = false |
||
| ) |
Sets the values of a tensor descriptor.
| hHandle | Specifies the handle to the tensor descriptor. |
| n | Specifies the number of items. |
| c | Specifies the number of channels in each item. |
| h | Specifies the height of each item. |
| w | Specifies the width of each item. |
| nStride | Specifies the stride between two images. |
| cStride | Specifies the stride between two channels. |
| hStride | Specifies the stride between two rows. |
| wStride | Specifies the stride between two columns. |
| bHalf | Optionally, specifies whether or not to use the FP16 half data type. |
Definition at line 3620 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetTensorNdDesc | ( | long | hHandle, |
| int[] | rgDim, | ||
| int[] | rgStride, | ||
| bool | bHalf = false |
||
| ) |
Sets the values of a tensor descriptor.
| hHandle | Specifies the handle to the tensor descriptor. |
| rgDim | Specifies the dimensions of the data. |
| rgStride | Specifies the stride of the data. |
| bHalf | Optionally, specifies whether or not to use the FP16 half data type. |
Definition at line 3551 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SetupSSD | ( | long | hSSD, |
| int | nNum, | ||
| int | nNumPriors, | ||
| int | nNumGt | ||
| ) |
Setup the SSD GPU support.
| hSSD | Specifies the handle to the SSD instance. |
| nNum | Specifies the number of items. |
| nNumPriors | Specifies the number of priors. |
| nNumGt | Specifies the number of ground truths. |
Definition at line 5625 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sgd_update | ( | int | nCount, |
| long | hNetParamsDiff, | ||
| long | hHistoryData, | ||
| T | fMomentum, | ||
| T | fLocalRate | ||
| ) |
Perform the Stochastic Gradient Descent (SGD) update
See Stochastic Gradient Descent.
| nCount | Specifies the number of items. |
| hNetParamsDiff | Specifies a handle to the net params diff in GPU memory. |
| hHistoryData | Specifies a handle to the history data in GPU memory. |
| fMomentum | Specifies the momentum value. |
| fLocalRate | Specifies the local learning rate. |
Definition at line 10203 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sigmoid_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff | ||
| ) |
Performs a Sigmoid backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 9341 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sigmoid_cross_entropy_bwd | ( | int | nCount, |
| int | nIgnoreLabel, | ||
| long | hTarget, | ||
| long | hBottomDiff | ||
| ) |
Performs a sigmoid cross entropy backward pass in Cuda when an ignore label is specified.
| nCount | Specifies the number of items. |
| nIgnoreLabel | Specifies the label to ignore. |
| hTarget | Specifies a handle to the target data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 10571 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sigmoid_cross_entropy_fwd | ( | int | nCount, |
| long | hInput, | ||
| long | hTarget, | ||
| long | hLoss, | ||
| bool | bHasIgnoreLabel, | ||
| int | nIgnoreLabel, | ||
| long | hCountData | ||
| ) |
Performs a sigmoid cross entropy forward pass in Cuda.
| nCount | Specifies the number of items. |
| hInput | Specifies a handle to the input data in GPU memory. |
| hTarget | Specifies a handle to the target data in GPU memory. |
| hLoss | Specifies a handle to the loss data in GPU memory. |
| bHasIgnoreLabel | Specifies whether or not an ignore label is used. |
| nIgnoreLabel | Specifies the ignore label which is used when bHasIgnoreLabel is true
|
| hCountData | Specifies a handle to the count data in GPU memory. |
Definition at line 10556 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sigmoid_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs a Sigmoid forward pass in Cuda.
Calcuation 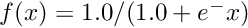
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9323 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SigmoidBackward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform a Sigmoid backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4553 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SigmoidForward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDataDesc, | ||
| long | hTopData | ||
| ) |
Perform a Sigmoid forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4531 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sign | ( | int | n, |
| long | hX, | ||
| long | hY, | ||
| int | nXOff = 0, |
||
| int | nYOff = 0 |
||
| ) |
Computes the sign of each element of X and places the result in Y.
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nXOff | Specifies an offset (in items, not bytes) into the memory of X. |
| nYOff | Specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 7574 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.silu_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData | ||
| ) |
Performs the Sigmoid-weighted Linear Unit (SiLU) activation backward pass in Cuda.
Computes the SiLU non-linearity 

| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
Definition at line 9140 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.silu_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs the Sigmoid-weighted Linear Unit (SiLU) activation forward pass in Cuda.
Computes the SiLU non-linearity
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9118 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.slice_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| int | nNumSlices, | ||
| int | nSliceSize, | ||
| int | nBottomSliceAxis, | ||
| int | nTopSliceAxis, | ||
| int | nOffsetSliceAxis, | ||
| long | hBottomDiff | ||
| ) |
Performs a slice backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nNumSlices | Specifies the number of slices. |
| nSliceSize | Specifies the slice size. |
| nBottomSliceAxis | Specifies the bottom axis to concatenate. |
| nTopSliceAxis | NEEDS REVIEW |
| nOffsetSliceAxis | NEEDS REVIEW |
| hBottomDiff | Specifies a handle to the Bottom diff in GPU memory. |
Definition at line 9907 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.slice_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| int | nNumSlices, | ||
| int | nSliceSize, | ||
| int | nBottomSliceAxis, | ||
| int | nTopSliceAxis, | ||
| int | nOffsetSliceAxis, | ||
| long | hTopData | ||
| ) |
Performs a slice forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| nNumSlices | Specifies the number of slices. |
| nSliceSize | Specifies the slice size. |
| nBottomSliceAxis | NEEDS REVIEW |
| nTopSliceAxis | NEEDS REVIEW |
| nOffsetSliceAxis | NEEDS REVIEW |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9888 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.smoothl1_bwd | ( | int | nCount, |
| long | hX, | ||
| long | hY | ||
| ) |
Performs the backward operation for the SmoothL1 loss.
Calculation: f'(x) = x, if |x| lt 1 = sign(x), otherwise
| nCount | Specifies the number of items. |
| hX | Specifies the input data X in GPU memory. |
| hY | Specifies the output data Y in GPU memory. |
Definition at line 10063 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.smoothl1_fwd | ( | int | nCount, |
| long | hX, | ||
| long | hY | ||
| ) |
Performs the forward operation for the SmoothL1 loss.
Calculation: f(x) = 0.5 * x^2, if |x| lt 1 = |x| - 0.5, otherwise
| nCount | Specifies the number of items. |
| hX | Specifies the input data X in GPU memory. |
| hY | Specifies the output data Y in GPU memory. |
Definition at line 10044 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.softmax_cross_entropy_bwd | ( | int | nCount, |
| int | nIgnoreLabel, | ||
| long | hTarget, | ||
| long | hBottomDiff | ||
| ) |
Performs a softmax cross entropy backward pass in Cuda when an ignore label is specified.
| nCount | Specifies the number of items. |
| nIgnoreLabel | Specifies the label to ignore. |
| hTarget | Specifies a handle to the target data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 10624 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.softmax_cross_entropy_fwd | ( | int | nCount, |
| long | hProbData, | ||
| long | hLabel, | ||
| long | hLossDiff, | ||
| long | hLossData, | ||
| int | nOuterNum, | ||
| int | nDim, | ||
| int | nInnerNum, | ||
| long | hCounts, | ||
| int? | nIgnoreLabel | ||
| ) |
Performs a softmax cross entropy forward pass in Cuda.
| nCount | Specifies the number of items. |
| hProbData | Specifies a handle to the probability data in GPU memory. |
| hLabel | Specifies a handle to the label data in GPU memory. |
| hLossDiff | Specifies a handle to the loss diff in GPU memory that is filled with 1's at each 'active' location where loss data is placed. |
| hLossData | Specifies a handle to the loss data in GPU memory. |
| nOuterNum | NEEDS REVIEW |
| nDim | NEEDS REVIEW |
| nInnerNum | NEEDS REVIEW |
| hCounts | Specifies a handle to the counts in GPU memory. |
| nIgnoreLabel | Optionally, specifies a label to ignore. |
This forward pass is a helper to perform a part of the NLLLoss portion of the SoftmaxCrossEntropyLoss.
Definition at line 10595 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SoftmaxBackward | ( | long | hCuDnn, |
| SOFTMAX_ALGORITHM | alg, | ||
| SOFTMAX_MODE | mode, | ||
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform a Softmax backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| alg | Specifies the SoftmaxAlgorithm to use (FAST, ACCURATE or LOG). |
| mode | Specifies the SoftmaxMode to use (INSTANCE across NxCHW, or CHANNEL across NCxHW) |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4640 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SoftmaxForward | ( | long | hCuDnn, |
| SOFTMAX_ALGORITHM | alg, | ||
| SOFTMAX_MODE | mode, | ||
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDataDesc, | ||
| long | hTopData | ||
| ) |
Perform a Softmax forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| alg | Specifies the SoftmaxAlgorithm to use (FAST, ACCURATE or LOG). |
| mode | Specifies the SoftmaxMode to use (INSTANCE across NxCHW, or CHANNEL across NCxHW) |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4618 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.softmaxloss_bwd | ( | int | nCount, |
| long | hTopData, | ||
| long | hLabel, | ||
| long | hBottomDiff, | ||
| int | nOuterNum, | ||
| int | nDim, | ||
| int | nInnerNum, | ||
| long | hCounts, | ||
| int? | nIgnoreLabel | ||
| ) |
Performs Softmax Loss backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hLabel | Specifies a handle to the label data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| nOuterNum | NEEDS REVIEW |
| nDim | NEEDS REVIEW |
| nInnerNum | NEEDS REVIEW |
| hCounts | Specifies a handle to the counts in GPU memory. |
| nIgnoreLabel | Optionally, specifies a label to ignore. |
Definition at line 9639 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.softmaxloss_fwd | ( | int | nCount, |
| long | hProbData, | ||
| long | hLabel, | ||
| long | hLossData, | ||
| int | nOuterNum, | ||
| int | nDim, | ||
| int | nInnerNum, | ||
| long | hCounts, | ||
| int? | nIgnoreLabel | ||
| ) |
Performs Softmax Loss forward pass in Cuda.
| nCount | Specifies the number of items. |
| hProbData | Specifies a handle to the probability data in GPU memory. |
| hLabel | Specifies a handle to the label data in GPU memory. |
| hLossData | Specifies a handle to the loss data in GPU memory. |
| nOuterNum | NEEDS REVIEW |
| nDim | NEEDS REVIEW |
| nInnerNum | NEEDS REVIEW |
| hCounts | Specifies a handle to the counts in GPU memory. |
| nIgnoreLabel | Optionally, specifies a label to ignore. |
Definition at line 9605 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.softplus_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff, | ||
| long | hBottomData | ||
| ) |
Performs the Softplus function backward, a smooth approximation of the ReLU function
Computes the SoftPlus non-linearity 

| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hBottomData | Specifies a handle tot he bottom data in GPU memory. |
Definition at line 9183 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.softplus_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs the Softplus function forward, a smooth approximation of the ReLU function
Computes the SoftPlus non-linearity
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9161 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sort | ( | int | nCount, |
| long | hY | ||
| ) |
Sort the data in the GPU memory specified.
| nCount | Specifies the total number of items in the memory. |
| hY | Specifies the handle to the GPU memory of data to sort. |
Definition at line 6212 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sqrt | ( | int | n, |
| long | hX, | ||
| long | hY | ||
| ) |
Computes the square root of each element of X and places the result in Y.
| n | Specifies the number of items (not bytes) in the vectors A and Y. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7624 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sqrt_scale | ( | int | nCount, |
| long | hX, | ||
| long | hY | ||
| ) |
Scale the data by the sqrt of the data. y = sqrt(abs(x)) * sign(x)
| nCount | Specifies the number of elements. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 7638 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SsdEncodeConfPrediction | ( | long | hSSD, |
| int | nConfPredCount, | ||
| long | hConfPred, | ||
| int | nConfGtCount, | ||
| long | hConfGt | ||
| ) |
Encodes the SSD data into the confidence prediction and confidence ground truths.
| hSSD | Specifies the handle to the SSD instance. |
| nConfPredCount | Specifies the number of confidence prediction items. |
| hConfPred | Specifies the confidence prediction data in GPU memory. |
| nConfGtCount | Specifies the confidence ground truth items. |
| hConfGt | Specifies the confidence ground truth data in GPU memory. |
Definition at line 5810 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SsdEncodeLocPrediction | ( | long | hSSD, |
| int | nLocPredCount, | ||
| long | hLocPred, | ||
| int | nLocGtCount, | ||
| long | hLocGt | ||
| ) |
Encodes the SSD data into the location prediction and location ground truths.
| hSSD | Specifies the handle to the SSD instance. |
| nLocPredCount | Specifies the number of location prediction items. |
| hLocPred | Specifies the location prediction data in GPU memory. |
| nLocGtCount | Specifies the location ground truth items. |
| hLocGt | Specifies the location ground truth data in GPU memory. |
Definition at line 5794 of file CudaDnn.cs.
| int MyCaffe.common.CudaDnn< T >.SsdMultiBoxLossForward | ( | long | hSSD, |
| int | nLocDataCount, | ||
| long | hLocGpuData, | ||
| int | nConfDataCount, | ||
| long | hConfGpuData, | ||
| int | nPriorDataCount, | ||
| long | hPriorGpuData, | ||
| int | nGtDataCount, | ||
| long | hGtGpuData, | ||
| out List< DictionaryMap< List< int > > > | rgAllMatchIndices, | ||
| out List< List< int > > | rgrgAllNegIndices, | ||
| out int | nNumNegs | ||
| ) |
Performs the SSD MultiBoxLoss forward operation.
| hSSD | Specifies the handle to the SSD instance. |
| nLocDataCount | Specifies the number of location data items. |
| hLocGpuData | Specifies the handle to the location data in GPU memory. |
| nConfDataCount | Specifies the number of confidence data items. |
| hConfGpuData | Specifies the handle to the confidence data in GPU memory. |
| nPriorDataCount | Specifies the number of prior box data. |
| hPriorGpuData | Specifies the prior box data in GPU memory. |
| nGtDataCount | Specifies the number of ground truth items. |
| hGtGpuData | Specifies the ground truth data in GPU memory. |
| rgAllMatchIndices | Returns all match indices found. |
| rgrgAllNegIndices | Returns all neg indices found. |
| nNumNegs | Returns the number of negatives. |
Definition at line 5661 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sub | ( | int | n, |
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| int | nAOff = 0, |
||
| int | nBOff = 0, |
||
| int | nYOff = 0, |
||
| int | nB = 0 |
||
| ) |
Subtracts B from A and places the result in Y.
Y = A - B
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A. |
| nBOff | Optionally, specifies an offset (in items, not bytes) into the memory of B. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
| nB | Optionally, specifies a number of 'B' items to subtract (default = 0 which causes ALL items in B to be subtracted). When 'nB' > 0, it must be a factor of 'n' and causes that number of B items to be subtracted as a block from A. |
Definition at line 7312 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sub_and_dot | ( | int | n, |
| int | nN, | ||
| int | nInnerNum, | ||
| long | hA, | ||
| long | hB, | ||
| long | hY, | ||
| int | nAOff, | ||
| int | nBOff, | ||
| int | nYOff | ||
| ) |
Subtracts every nInnterNum element of B from A and performs a dot product on the result.
Y[i] = (A[i] - B[inInnerNum]) * (A[i] - B[inInnerNum])
| n | Specifies the number of items (not bytes) in the vectors A, B and Y. |
| nN | Specifies the inner count. |
| nInnerNum | Specifies the dimension. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
| nAOff | Optionally, specifies an offset (in items, not bytes) into the memory of A. |
| nBOff | Optionally, specifies an offset (in items, not bytes) into the memory of B. |
| nYOff | Optionally, specifies an offset (in items, not bytes) into the memory of Y. |
Definition at line 7357 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.sum | ( | int | nCount, |
| int | nOuterNum, | ||
| int | nInnerNum, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Calculates the sum of inner values of X and places the result in Y.
| nCount | Specifies the number of elements in X. |
| nOuterNum | Specifies the number of outer items within X. |
| nInnerNum | Specifies the dimension of items to sum in X. |
| hX | Specifies a handle to the vector X in GPU memory. |
| hY | Specifies a handle to the vector Y in GPU memory. |
Definition at line 8491 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.sumsq | ( | int | n, |
| long | hW, | ||
| long | hA, | ||
| int | nAOff = 0 |
||
| ) |
Calculates the sum of squares of A.
| n | Specifies the number of items (not bytes) in the vectors A and W. |
| hW | Specifies a handle to workspace data in GPU memory. |
| hA | Specifies a handle to the vector A in GPU memory. |
| nAOff | Specifies an offset (in items, not bytes) into the memory of A. |
Definition at line 7878 of file CudaDnn.cs.
| double MyCaffe.common.CudaDnn< T >.sumsqdiff | ( | int | n, |
| long | hW, | ||
| long | hA, | ||
| long | hB, | ||
| int | nAOff = 0, |
||
| int | nBOff = 0 |
||
| ) |
Calculates the sum of squares of differences between A and B
| n | Specifies the number of items (not bytes) in the vectors A, B and W. |
| hW | Specifies a handle to workspace data in GPU memory. |
| hA | Specifies a handle to the vector A in GPU memory. |
| hB | Specifies a handle to the vector B in GPU memory. |
| nAOff | Specifies an offset (in items, not bytes) into the memory of A. |
| nBOff | Specifies an offset (in items, not bytes) into the memory of B. |
Definition at line 7902 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.swish_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hSigmoidOutputData, | ||
| long | hBottomDiff, | ||
| double | dfBeta | ||
| ) |
Performs a Swish backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hSigmoidOutputData | Specifies a handle to the sigmoid output data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| dfBeta | Specifies the 'beta' value applied to the output. |
Definition at line 9361 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SynchronizeDevice | ( | ) |
Synchronize the operations on the current device.
Definition at line 2093 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SynchronizeStream | ( | long | h = 0 | ) |
Synchronize a stream on the current GPU, waiting for its operations to complete.
| h | Specifies the handle to the stream. |
Definition at line 3239 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.SynchronizeThread | ( | ) |
Synchronize all kernel threads on the current GPU.
Definition at line 3250 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.tanh_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| long | hTopData, | ||
| long | hBottomDiff | ||
| ) |
Performs a TanH backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 9304 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.tanh_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| long | hTopData | ||
| ) |
Performs a TanH forward pass in Cuda.
Calculation 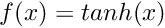
| nCount | Specifies the number of items in the bottom and top data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9286 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.TanhBackward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hTopDataDesc, | ||
| long | hTopData, | ||
| long | hTopDiffDesc, | ||
| long | hTopDiff, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hBottomDiffDesc, | ||
| long | hBottomDiff | ||
| ) |
Perform a Tanh backward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hTopDiffDesc | Specifies a handle to the top diff tensor descriptor |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hBottomDiffDesc | Specifies a handle to the bottom diff tensor descriptor. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
Definition at line 4473 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.TanhForward | ( | long | hCuDnn, |
| T | fAlpha, | ||
| long | hBottomDataDesc, | ||
| long | hBottomData, | ||
| T | fBeta, | ||
| long | hTopDataDesc, | ||
| long | hTopData | ||
| ) |
Perform a Tanh forward pass.
| hCuDnn | Specifies a handle to the instance of cuDnn. |
| fAlpha | Specifies a scaling factor applied to the result. |
| hBottomDataDesc | Specifies a handle to the bottom data tensor descriptor. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| fBeta | Specifies a scaling factor applied to the prior destination value. |
| hTopDataDesc | Specifies a handle to the top data tensor descriptor. |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 4451 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.threshold_fwd | ( | int | nCount, |
| double | dfThreshold, | ||
| long | hX, | ||
| long | hY | ||
| ) |
Performs a threshold pass in Cuda.
Calculation: ![$ Y[i] = (X[i] > threshold) ? 1 : 0 $](form_77.png)
| nCount | Specifies the number of items. |
| dfThreshold | Specifies the threshold value. |
| hX | Specifies the input data X in GPU memory. |
| hY | Specifies the output data Y in GPU memory. |
Definition at line 10001 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.tile_bwd | ( | int | nCount, |
| long | hTopDiff, | ||
| int | nTileSize, | ||
| int | nTiles, | ||
| int | nBottomTileAxis, | ||
| long | hBottomDiff | ||
| ) |
Performs a tile backward pass in Cuda.
| nCount | Specifies the number of items. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| nTileSize | Specifies the size of each tile. |
| nTiles | Specifies the number of tiles. |
| nBottomTileAxis | NEEDS REVIEW |
| hBottomDiff | Specifies a handle to the Bottom diff in GPU memory. |
Definition at line 9941 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.tile_fwd | ( | int | nCount, |
| long | hBottomData, | ||
| int | nInnerDim, | ||
| int | nTiles, | ||
| int | nBottomTileAxis, | ||
| long | hTopData | ||
| ) |
Performs a tile forward pass in Cuda.
| nCount | Specifies the number of items. |
| hBottomData | Specifies a handle to the Bottom data in GPU memory. |
| nInnerDim | NEEDS REVIEW |
| nTiles | Specifies the number of tiles. |
| nBottomTileAxis | NEEDS REVIEW |
| hTopData | Specifies a handle to the top data in GPU memory. |
Definition at line 9924 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.transpose | ( | int | n, |
| long | hX, | ||
| long | hY, | ||
| long | hXCounts, | ||
| long | hYCounts, | ||
| long | hMapping, | ||
| int | nNumAxes, | ||
| long | hBuffer | ||
| ) |
Perform a transpose on X producing Y, similar to the numpy.transpose operation.
| n | Specifies the number of items in both hX and hY (must be the same). |
| hX | Specifies a handle to the input data in gpu memory. |
| hY | Specifies a handle to the output data in gpu memory. |
| hXCounts | Specifies a handle to the input counts in gpu memory. |
| hYCounts | Specifies a handle to the output counts in gpu memory. |
| hMapping | Specifies a handle to the mappings of each axis. |
| nNumAxes | Specifies the number of axes. |
| hBuffer | Specifies a handle to the buffer that should have 'n' * nNumAxes number of items. |
Definition at line 7862 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.transposeHW | ( | int | n, |
| int | c, | ||
| int | h, | ||
| int | w, | ||
| long | hSrc, | ||
| long | hDst | ||
| ) |
Transpose a n*c number of matrices along the height and width dimensions. All matrices are in row-major format.
| n | Specifies the number of items (e.g. batches) |
| c | Specifies the number of channels. |
| h | Specifies the height. |
| w | Specifies the width. |
| hSrc | Specifies a handle to GPU memory of shape (n,c,h,w) |
| hDst | Specifies a handle to GPU memory of shape (n,c,w,h) |
Definition at line 6716 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.unpooling_bwd | ( | POOLING_METHOD | method, |
| int | nCount, | ||
| long | hTopDiff, | ||
| int | num, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nPooledHeight, | ||
| int | nPooledWidth, | ||
| int | nKernelH, | ||
| int | nKernelW, | ||
| int | nStrideH, | ||
| int | nStrideW, | ||
| int | nPadH, | ||
| int | nPadW, | ||
| long | hBottomDiff, | ||
| long | hMask | ||
| ) |
Performs the backward pass for unpooling using Cuda
| method | Specifies the pooling method. |
| nCount | Specifies the number of items in the bottom data. |
| hTopDiff | Specifies a handle to the top diff in GPU memory. |
| num | Specifies the number of inputs. |
| nChannels | Specifies the number of channels per input. |
| nHeight | Specifies the height of each input. |
| nWidth | Specifies the width of each input. |
| nPooledHeight | Specifies the height of the pooled data. |
| nPooledWidth | Specifies the width of the pooled data. |
| nKernelH | Specifies the height of the pooling kernel. |
| nKernelW | Specifies the width of the pooling kernel. |
| nStrideH | Specifies the stride along the height. |
| nStrideW | Specifies the stride along the width. |
| nPadH | Specifies the pad applied to the height. |
| nPadW | Specifies the pad applied to the width. |
| hBottomDiff | Specifies a handle to the bottom diff in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU memory. |
Definition at line 8895 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.unpooling_fwd | ( | POOLING_METHOD | method, |
| int | nCount, | ||
| long | hBottomData, | ||
| int | num, | ||
| int | nChannels, | ||
| int | nHeight, | ||
| int | nWidth, | ||
| int | nPooledHeight, | ||
| int | nPooledWidth, | ||
| int | nKernelH, | ||
| int | nKernelW, | ||
| int | nStrideH, | ||
| int | nStrideW, | ||
| int | nPadH, | ||
| int | nPadW, | ||
| long | hTopData, | ||
| long | hMask | ||
| ) |
Performs the forward pass for unpooling using Cuda
| method | Specifies the pooling method. |
| nCount | Specifies the number of items in the bottom data. |
| hBottomData | Specifies a handle to the bottom data in GPU memory. |
| num | Specifies the number of inputs. |
| nChannels | Specifies the number of channels per input. |
| nHeight | Specifies the height of each input. |
| nWidth | Specifies the width of each input. |
| nPooledHeight | Specifies the height of the pooled data. |
| nPooledWidth | Specifies the width of the pooled data. |
| nKernelH | Specifies the height of the pooling kernel. |
| nKernelW | Specifies the width of the pooling kernel. |
| nStrideH | Specifies the stride along the height. |
| nStrideW | Specifies the stride along the width. |
| nPadH | Specifies the pad applied to the height. |
| nPadW | Specifies the pad applied to the width. |
| hTopData | Specifies a handle to the top data in GPU memory. |
| hMask | Specifies a handle to the mask data in GPU memory. |
Definition at line 8867 of file CudaDnn.cs.
| void MyCaffe.common.CudaDnn< T >.width | ( | int | n, |
| long | hMean, | ||
| long | hMin, | ||
| long | hMax, | ||
| double | dfAlpha, | ||
| long | hWidth | ||
| ) |
Calculates the width values.
| n | Specifies the number of items. |
| hMean | Specifies a handle to the mean values in GPU memory. |
| hMin | Specifies a handle to the min values in GPU memory. |
| hMax | Specifies a handle to the max values in GPU memory. |
| dfAlpha | Specifies the alpha value. |
| hWidth | Specifies the GPU memory where the width values are placed. |
Definition at line 7925 of file CudaDnn.cs.
|
staticget |
Returns the base data type size (e.g. float= 4, double = 8).
Definition at line 2428 of file CudaDnn.cs.
|
staticget |
Specifies the default path used t load the Low-Level Cuda DNN Dll file.
Definition at line 1931 of file CudaDnn.cs.
|
get |
Returns the Low-Level kernel handle used for this instance. Each Low-Level kernel maintains its own set of look-up tables for memory, streams, cuDnn constructs, etc.
Definition at line 1811 of file CudaDnn.cs.
|
get |
Returns the original device ID used to create the instance of CudaDnn.
Definition at line 2004 of file CudaDnn.cs.
|
get |
Specifies the file path used to load the Low-Level Cuda DNN Dll file.
Definition at line 1923 of file CudaDnn.cs.
|
get |
Returns the total amount of GPU memory used by this instance.
Definition at line 1794 of file CudaDnn.cs.
|
get |
Returns the total amount of memory used.
Definition at line 1802 of file CudaDnn.cs.
 Help generated by
Help generated by
 1.8.13
1.8.13