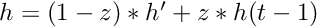|
MyCaffe
1.12.2.41
Deep learning software for Windows C# programmers.
|
|
MyCaffe
1.12.2.41
Deep learning software for Windows C# programmers.
|
The MyCaffe.common namespace contains common MyCaffe classes. More...
Classes | |
| class | ActionStateArgs |
| The ActionStateArgs are sent to the DoWork event when fired from the InternalThreadEntry. More... | |
| class | BackwardArgs |
| The BackwardArgs are passed to the OnBackward event of the EventLayer. More... | |
| class | BatchInput |
| The BatchInput class stores the mini-batch index and input data. More... | |
| class | BBoxUtility |
| The BBox class processes the NormalizedBBox data used with SSD. More... | |
| class | BeamSearch |
| The BeamSearch uses the softmax output from the network and continually runs the net on each output (using the output as input) until the end of token is reached. The beam-search tree is returned. More... | |
| class | Blob |
| The Blob is the main holder of data that moves through the Layers of the Net. More... | |
| class | BlobCollection |
| The BlobCollection contains a list of Blobs. More... | |
| class | BlobDebugInformation |
| The BlobDebugInformation describes debug information relating to a given Blob in a given Layer. More... | |
| class | BlobName |
| The BlobName class is used to build unique blob names. More... | |
| class | BlockingQueue |
| The BlockingQueue is used for synchronized Queue operations. More... | |
| class | Cache |
| The Cache class is used to cache blobs over time. More... | |
| class | ComputeGraph |
| The ComputeGraph class provides a simple computation graph of operations used in a forward pass that are stored in an array on each call and then unwound with calls that calculate the gradients on the backward pass. More... | |
| class | CudaDnn |
| The CudaDnn object is the main interface to the Low-Level Cuda C++ DLL. More... | |
| class | CudaDnnMemoryTracker |
| The CudaDnnMemoryTracker is used for diagnostics in that it helps estimate the amount of memory that a Net will use. More... | |
| class | CustomForwardBackArgs |
| The CustomForwardBackArgs provide the arguments to the OnCustomForwardBack event within the Solver Step function. More... | |
| class | DebugInformation |
| The DebugInformation contains information used to help debug the Layers of a Net while it is training. More... | |
| class | ForwardArgs |
| The ForwardArgs are passed to the OnForward event of the EventLayer. More... | |
| class | GetBytesArgs |
| The GetBytesArgs is passed along to the SnapshotArgs::OnGetWeights and SnapshotArgs::OnGetState events. More... | |
| class | GetConversionBlobArgs |
| The GetConversionBlobArgs are passed to the Layer::OnGetConversionBlobs event which fires each time a blob needs to be converted form half to base or back. More... | |
| class | GetIterationArgs |
| The GetIterationArgs is sent bubbled up to the solver when a layer needs to know the curret training iteration. More... | |
| class | GetWorkBlobArgs |
| The GetWorkBlobArgs are passed to the Layer::OnGetWorkBlob event which is supported for debugging only. More... | |
| class | GPUParams |
| The GPUParams contains the connection to the low-level Cuda, and the stream associated with this instance. More... | |
| class | GradientsReadyArgs |
| The GradientsReadyArgs is sent to the Solver::OnGradientsReady event which fires at the end of each Solver::Step. More... | |
| class | HostBuffer |
| The HostBuffer helps manage host memory, often used when implementing CPU versions of a function or layer. More... | |
| class | InternalThread |
| The InternalThread manages an internal thread used for Parallel and data collection operations. More... | |
| interface | IXDebugData |
| The IXDebugData interface is implemented by the DebugLayer to give access to the debug information managed by the layer. More... | |
| interface | IXMyCaffe |
| The IXMyCaffe interface contains functions used to perform MyCaffe operations that work with the MyCaffeImageDatabase. More... | |
| interface | IXMyCaffeExtension |
| The IXMyCaffeExtension interface allows for easy extension management of the low-level software that interacts directly with CUDA. More... | |
| interface | IXMyCaffeNoDb |
| The IXMyCaffeNoDb interface contains functions used to perform MyCaffe operations that run in a light-weight manner without the MyCaffeImageDatabase. More... | |
| interface | IXMyCaffeState |
| The IXMyCaffeState interface contains functions related to the MyCaffeComponent state. More... | |
| interface | IXPersist |
| The IXPersist interface is used by the CaffeControl to load and save weights. More... | |
| class | LayerDebugInformation |
| The LayerDebugInformation describes debug information relating to a given Layer in the Net. More... | |
| class | NCCL |
| The NCCL class manages the multi-GPU operations using the low-level NCCL functionality provided by the low-level Cuda Dnn DLL. More... | |
| class | Net |
| Connects Layer's together into a direct acrylic graph (DAG) specified by a NetParameter More... | |
| class | NumpyFile |
| The NumpyFile reads data from a numpy file in the base type specified. More... | |
| class | Params |
| The Params contains the base parameters used in multi-GPU training. More... | |
| class | PersistCaffe |
| The PersistCaffe class is used to load and save weight files in the .caffemodel format. More... | |
| class | Property |
| The Property class stores both a numeric and text value. More... | |
| class | PropertyTree |
| The PropertyTree class implements a simple property tree similar to the ptree in Boost. More... | |
| class | ResultCollection |
| The ResultCollection contains the result of a given CaffeControl::Run. More... | |
| class | SnapshotArgs |
| The SnapshotArgs is sent to the Solver::OnSnapshot event which fires each time the Solver::Snapshot method is called. More... | |
| class | SolverInfo |
| The SolverInfo defines the user supplied arguments passed to each Worker. More... | |
| class | SsdSampler |
| The SsdSampler is used by the SSD algorithm to sample BBoxes. More... | |
| class | SyncedMemory |
| The SyncedMemory manages the low-level connection between the GPU and host memory. More... | |
| class | TestArgs |
| The TestArgs are passed to the Solver::OnTest event. More... | |
| class | TestingIterationArgs |
| Specifies the TestingIterationArgs sent to the Solver::OnTestingIteration, which is called at the end of a testing cycle. More... | |
| class | TestResultArgs |
| The TestResultArgs are passed to the Solver::OnTestResults event. More... | |
| class | TrainingIterationArgs |
| The TrainingIterationArgs is sent to the Solver::OnTrainingIteration event that fires at the end of a training cycle. More... | |
| class | TransferInput |
| The TransferInput class is used to transfer get and set input data. More... | |
| class | WeightInfo |
| The WeightInfo class describes the weights of a given weight set including the blob names and sizes of the weights. More... | |
| class | Worker |
| The Worker manages each 'non' root sover running, where each Worker operates on a different GPU. More... | |
| class | WorkspaceArgs |
| The WorkspaceArgs are passed to both the Layer::OnSetWorkspace and Layer::OnGetWorkspace events. More... | |
Enumerations | |
| enum | DIR { FWD = 0 , BWD = 1 } |
| Defines the direction of data flow. More... | |
| enum | MEAN_ERROR { MSE = 1 , MAE = 2 } |
| Defines the type of Mean Error to use. More... | |
| enum | MATH_FUNCTION { NOP = 0 , ACOS = 1 , ACOSH = 2 , COS = 3 , COSH = 4 , ASIN = 10 , ASINH = 11 , SIN = 12 , SINH = 13 , ATAN = 20 , ATANH = 21 , TAN = 22 , TANH = 23 , CEIL = 30 , FLOOR = 31 , NEG = 32 , SIGN = 33 , SQRT = 34 } |
| Defines the mathematical function to run. More... | |
| enum | OP { MUL = 1 , DIV = 2 , ADD = 3 , SUB = 4 } |
| Defines the operations performed by the channel_op function. More... | |
| enum | DistanceMethod { HAMMING = 0 , EUCLIDEAN = 1 } |
| Specifies the distance method used when calculating batch distances. More... | |
| enum | PoolingMethod { MAX = 0 , AVE = 1 } |
| Specifies the pooling method used by the cuDnn function SetPoolingDesc. More... | |
| enum | DataType { DOUBLE , FLOAT } |
| Specifies the base datatype corresponding the the template type 'T'. Currently, only More... | |
| enum | DEVINIT { NONE = 0x0000 , CUBLAS = 0x0001 , CURAND = 0x0002 , SETSEED = 0x0004 } |
| Specifies the initialization flags used when initializing CUDA. More... | |
| enum | BATCHNORM_MODE { PER_ACTIVATION = 0 , SPATIAL = 1 , SPATIAL_PERSISTENT = 2 } |
| Specifies the cuDnn batch norm mode to use. More... | |
| enum | CONV_FWD_ALGO { NONE = -1 , IMPLICIT_GEMM = 0 , IMPLICIT_PRECOMP_GEMM = 1 , ALGO_GEMM = 2 , ALGO_DIRECT = 3 , ALGO_FFT = 4 , ALGO_FFT_TILING = 5 , ALGO_WINOGRAD = 6 , ALGO_WINOGRAD_NONFUSED = 7 } |
| Specifies the cuDnn convolution forward algorithm to use. More... | |
| enum | CONV_BWD_FILTER_ALGO { ALGO_0 = 0 , ALGO_1 = 1 , ALGO_FFT = 2 , ALGO_3 = 3 } |
| Specifies the cuDnn convolution backward filter algorithm to use. More... | |
| enum | CONV_BWD_DATA_ALGO { ALGO_0 = 0 , ALGO_1 = 1 , ALGO_FFT = 2 } |
| Specifies the cuDnn convolution backward data algorithm to use. More... | |
| enum | POOLING_METHOD { MAX = 0 , AVE = 1 , STO_TRAIN = 2 , STO_TEST = 3 } |
| Specifies the pooling method to use when using the Caffe pooling (instead of the pooling from NVIDIA's cuDnn). More... | |
| enum | RNN_MODE { RNN_RELU = 0 , RNN_TANH = 1 , LSTM = 2 , GRU = 3 } |
| Specifies the RNN mode to use with the Recurrent Layer when using the cuDNN engine. More... | |
| enum | RNN_BIAS_MODE { RNN_NO_BIAS = 0 , RNN_SINGLE_INP_BIAS = 1 , RNN_DOUBLE_BIAS = 2 , RNN_SINGLE_REC_BIAS = 3 } |
| Specifies the RNN bias mode to use with the Recurrent Layer when using the cuDNN engine. More... | |
| enum | RNN_DATALAYOUT { RNN_SEQ_MAJOR_UNPACKED = 0 , RNN_SEQ_MAJOR_PACKED = 1 , RNN_BATCH_MAJOR_UNPACKED = 2 } |
| Specifies the RNN data layout of the data input. More... | |
| enum | RNN_DIRECTION { RNN_UNIDIRECTIONAL , RNN_BIDIRECTIONAL } |
| Specifies the RNN directional used. More... | |
| enum | RNN_FILLER_TYPE { RNN_CONSTANT_FILLER , RNN_XAVIER_FILLER , RNN_GAUSSIAN_FILLER } |
| Defines the filler types used to fill the RNN8 weights. More... | |
| enum | DEVPROP { DEVICECOUNT = 1 , NAME = 2 , MULTIGPUBOARDGROUPID = 3 } |
| Specifies certain device properties to query from Cuda. More... | |
| enum | MEMTEST_TYPE { MOV_INV_8 = 1 } |
| Specifies the memory test to perform. More... | |
| enum | NCCL_REDUCTION_OP { SUM = 0 , PROD = 1 , MAX = 2 , MIN = 3 } |
| Specifies the reduction operation to use with 'Nickel' NCCL. More... | |
| enum | SSD_MINING_TYPE { NONE = 0 , MAX_NEGATIVE = 1 , HARD_EXAMPLE = 2 } |
| Defines the mining type used during SSD cuda training. More... | |
| enum | SSD_MATCH_TYPE { BIPARTITE , PER_PREDICTION } |
| Defines the matching method used during SSD cuda training. More... | |
| enum | SSD_CODE_TYPE { CORNER = 1 , CENTER_SIZE = 2 , CORNER_SIZE = 3 } |
| Defines the encode/decode type used during SSD cuda training. More... | |
| enum | SSD_CONF_LOSS_TYPE { SOFTMAX , LOGISTIC } |
| Defines the confidence loss types used during SSD cuda training. More... | |
| enum | SSD_LOC_LOSS_TYPE { L2 , SMOOTH_L1 } |
| Defines the location loss types used during SSD cuda training. More... | |
| enum | ORIENTATION { COL = 0 , ROW = 1 } |
| Specifies the orientation of a matrix. More... | |
| enum | TRANSPOSE_OPERATION { ADD = 0 , MUL = 1 , DIV = 2 } |
| Specifies the type of operation to perform along with a matrix transposition. More... | |
| enum | AGGREGATIONS { SUM = 0 , MAX = 1 , MIN = 2 } |
| Specifies different aggregation operations. More... | |
| enum | SOFTMAX_ALGORITHM { DEFAULT = 1 , FAST = 0 , ACCURATE = 1 , LOG = 2 } |
| Specifies the SOFTMAX algorithm to use. More... | |
| enum | SOFTMAX_MODE { INSTANCE , CHANNEL } |
| Specifies the SOFTMAX mode to use. More... | |
| enum | WEIGHT_TARGET { NONE , WEIGHTS , BIAS , BOTH } |
| Defines the type of weight to target in re-initializations. More... | |
| enum | BLOB_TYPE { UNKNOWN = 0x0000 , DATA = 0x0001 , IP_WEIGHT = 0x0002 , WEIGHT = 0x0004 , LOSS = 0x0008 , ACCURACY = 0x0010 , CLIP = 0x0020 , MULTIBBOX = 0x0040 , INTERNAL = 0x0080 , TARGET = 0x0100 , PREDICTION = 0x0200 , ATTENTION = 0x0400 } |
| Defines the tpe of data held by a given Blob. More... | |
| enum | TRAIN_STEP { NONE = 0x0000 , FORWARD = 0x0001 , BACKWARD = 0x0002 , BOTH = 0x0003 } |
| Defines the training stepping method (if any). More... | |
Functions | |
| delegate void | onSetWorkspace (object sender, WorkspaceArgs e) |
| Delegate used to set the OnSetworkspace event. More... | |
| delegate void | onGetWorkspace (object sender, WorkspaceArgs e) |
| Delegate used to set the OnGetworkspace event. More... | |
The MyCaffe.common namespace contains common MyCaffe classes.
Specifies different aggregation operations.
| Enumerator | |
|---|---|
| SUM | Sum the values. |
| MAX | Return the maximum value. |
| MIN | Return the minimum value. |
Definition at line 681 of file CudaDnn.cs.
Specifies the cuDnn batch norm mode to use.
Definition at line 236 of file CudaDnn.cs.
Defines the tpe of data held by a given Blob.
| Enumerator | |
|---|---|
| UNKNOWN | The blob is an unknown type. |
| DATA | The Blob holds Data. |
| IP_WEIGHT | The Blob holds an inner product weight. |
| WEIGHT | The Blob holds a general weight. |
| LOSS | The Blob holds Loss Data. |
| ACCURACY | The Blob holds Accuracy Data. |
| CLIP | The blob holds Clip data. |
| MULTIBBOX | The blob holds multi-boundingbox data. The multi-box data ordering is as follows: [0] index of num. [1] label [2] score [3] bbox xmin [4] bbox ymin [5] bbox xmax [6] bbox ymax continues for each of the top 'n' bboxes output. |
| INTERNAL | The blob is an internal blob used within the layer. |
| TARGET | The blob contains target data. |
| PREDICTION | The blob contains prediction data. |
| ATTENTION | The blob contains attention scores. |
Definition at line 61 of file Interfaces.cs.
Specifies the cuDnn convolution backward data algorithm to use.
| Enumerator | |
|---|---|
| ALGO_0 | Specifies to use algorithm 0 - which is non-deterministic. |
| ALGO_1 | Specifies to use algorithm 1. |
| ALGO_FFT | Specifies to use the fft algorithm. |
Definition at line 330 of file CudaDnn.cs.
Specifies the cuDnn convolution backward filter algorithm to use.
Definition at line 304 of file CudaDnn.cs.
Specifies the cuDnn convolution forward algorithm to use.
Definition at line 258 of file CudaDnn.cs.
Specifies the base datatype corresponding the the template type 'T'. Currently, only
double and float types are supported.
| Enumerator | |
|---|---|
| DOUBLE | Specifies the double type. |
| FLOAT | Specifies the single type. |
Definition at line 191 of file CudaDnn.cs.
Specifies the initialization flags used when initializing CUDA.
Definition at line 206 of file CudaDnn.cs.
Specifies certain device properties to query from Cuda.
| Enumerator | |
|---|---|
| DEVICECOUNT | Query the number of devices (gpu's) installed. |
| NAME | Query the name of a given GPU. |
| MULTIGPUBOARDGROUPID | Query a GPU board group ID. |
Definition at line 476 of file CudaDnn.cs.
| enum MyCaffe.common.DIR |
Defines the direction of data flow.
| Enumerator | |
|---|---|
| FWD | Specifies data is moving forward. |
| BWD | Specifies data is moving backward. |
Definition at line 21 of file CudaDnn.cs.
Specifies the distance method used when calculating batch distances.
| Enumerator | |
|---|---|
| HAMMING | Specifies to calculate the hamming distance. |
| EUCLIDEAN | Specifies to calculate the euclidean distance. |
Definition at line 158 of file CudaDnn.cs.
Defines the mathematical function to run.
Definition at line 51 of file CudaDnn.cs.
Defines the type of Mean Error to use.
| Enumerator | |
|---|---|
| MSE | Mean Squared Error (MSE) |
| MAE | Mean Absolute Error (MAE) |
Definition at line 36 of file CudaDnn.cs.
Specifies the memory test to perform.
| Enumerator | |
|---|---|
| MOV_INV_8 | Specifies the mov-inv-8 test. |
Definition at line 498 of file CudaDnn.cs.
Specifies the reduction operation to use with 'Nickel' NCCL.
| Enumerator | |
|---|---|
| SUM | Sum the values. |
| PROD | Multiply the values. |
| MAX | Return the maximum value. |
| MIN | Return the minimum value. |
Definition at line 512 of file CudaDnn.cs.
| enum MyCaffe.common.OP |
Defines the operations performed by the channel_op function.
Definition at line 134 of file CudaDnn.cs.
Specifies the orientation of a matrix.
| Enumerator | |
|---|---|
| COL | Specifies to add the vector to each column. |
| ROW | Specifies to add the vector to each row. |
Definition at line 644 of file CudaDnn.cs.
Specifies the pooling method to use when using the Caffe pooling (instead of the pooling from NVIDIA's cuDnn).
Definition at line 352 of file CudaDnn.cs.
Specifies the pooling method used by the cuDnn function SetPoolingDesc.
| Enumerator | |
|---|---|
| MAX | Specifies to use
|
| AVE | Specifies to use
|
Definition at line 176 of file CudaDnn.cs.
Specifies the RNN bias mode to use with the Recurrent Layer when using the cuDNN engine.
Definition at line 400 of file CudaDnn.cs.
Specifies the RNN data layout of the data input.
Definition at line 423 of file CudaDnn.cs.
Specifies the RNN directional used.
| Enumerator | |
|---|---|
| RNN_UNIDIRECTIONAL | Specifies a single direction RNN (default) |
| RNN_BIDIRECTIONAL | Specifies a bi-direction RNN where the output is concatinated at each layer. |
Definition at line 442 of file CudaDnn.cs.
Defines the filler types used to fill the RNN8 weights.
Definition at line 457 of file CudaDnn.cs.
Specifies the RNN mode to use with the Recurrent Layer when using the cuDNN engine.
Definition at line 375 of file CudaDnn.cs.
Specifies the SOFTMAX algorithm to use.
| Enumerator | |
|---|---|
| DEFAULT | Specifies to use the default algorithm. |
| FAST | Specifies to use the fast algorithm. |
| ACCURATE | Specifies to use the accurate algorithm. |
| LOG | Specifies to use the log algorithm. |
Definition at line 700 of file CudaDnn.cs.
Specifies the SOFTMAX mode to use.
| Enumerator | |
|---|---|
| INSTANCE | Specifies to run the softmax separately for each N, across CHW dimensions. |
| CHANNEL | Specifies to run the softmax separately for each N*C, across HW dimensions. |
Definition at line 723 of file CudaDnn.cs.
Defines the encode/decode type used during SSD cuda training.
This enum matches the values of the PriorBoxParameter.CodeType with the values supported in the low level CudaDnnDll.
| Enumerator | |
|---|---|
| CORNER | Encode the corner. |
| CENTER_SIZE | Encode the center size. |
| CORNER_SIZE | Encode the corner size. |
Definition at line 584 of file CudaDnn.cs.
Defines the confidence loss types used during SSD cuda training.
This enum matches the values of the MultiboxLossParameter.ConfLossType with the values supported in the low level CudaDnnDll.
| Enumerator | |
|---|---|
| SOFTMAX | Specifies to use softmax. |
| LOGISTIC | Specifies to use logistic. |
Definition at line 607 of file CudaDnn.cs.
Defines the location loss types used during SSD cuda training.
This enum matches the values of the MultiboxLossParameter.LocLossType with the values supported in the low level CudaDnnDll.
| Enumerator | |
|---|---|
| L2 | Specifies to use L2 loss. |
| SMOOTH_L1 | Specifies to use smooth L1 loss. |
Definition at line 626 of file CudaDnn.cs.
Defines the matching method used during SSD cuda training.
This enum matches the values of the MultiBoxLossParameter.MatchType with the values supported in the low level CudaDnnDll.
| Enumerator | |
|---|---|
| BIPARTITE | Specifies to use Bi-Partite. |
| PER_PREDICTION | Specifies to use per-prediction matching. |
Definition at line 565 of file CudaDnn.cs.
Defines the mining type used during SSD cuda training.
This enum matches the values of the MultiBoxLossParameter.MiningType with the values supported in the low level CudaDnnDll.
| Enumerator | |
|---|---|
| NONE | Use all negatives. |
| MAX_NEGATIVE | Select negatives based on the score. |
| HARD_EXAMPLE | Select hard examples based on Shrivastava et. al. method.
|
Definition at line 539 of file CudaDnn.cs.
Defines the training stepping method (if any).
| Enumerator | |
|---|---|
| NONE | No stepping. |
| FORWARD | Step only in the forward direction. |
| BACKWARD | Step only in the backward direction. |
| BOTH | Step in both directions (one forward and one backward). |
Definition at line 130 of file Interfaces.cs.
Specifies the type of operation to perform along with a matrix transposition.
| Enumerator | |
|---|---|
| ADD | Add the matrix values after transposing. |
| MUL | Multiply the matrix values after transposing. |
| DIV | Divide the matrix values after transposing. |
Definition at line 662 of file CudaDnn.cs.
Defines the type of weight to target in re-initializations.
| Enumerator | |
|---|---|
| NONE | No weights are targeted. |
| WEIGHTS | Generic weights are targeted. |
| BIAS | Bias weights are targeted. |
| BOTH | Both weights and bias are targeted. |
Definition at line 37 of file Interfaces.cs.
| delegate void MyCaffe.common.onGetWorkspace | ( | object | sender, |
| WorkspaceArgs | e | ||
| ) |
Delegate used to set the OnGetworkspace event.
| sender | Specifies the sender. |
| e | Specifies the arguments. |
| delegate void MyCaffe.common.onSetWorkspace | ( | object | sender, |
| WorkspaceArgs | e | ||
| ) |
Delegate used to set the OnSetworkspace event.
| sender | Specifies the sender. |
| e | Specifies the arguments. |
 Help generated by
Help generated by
 1.8.13
1.8.13
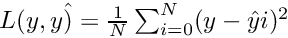 where
where 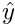 is the predicted value.
is the predicted value. 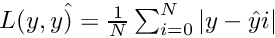 where
where 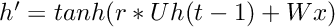 and
and