

This tutorial will guide you through the steps to create and train a small encoder/decoder transformer model as described by [1] to learn how to translate English to French.
Step 1 – Create the Project
In the first step we need to create the encoder/decoder project that uses a MODEL based dataset. MODEL based datasets rely on the model itself to collect data used for training.
First select the Add Project (![]() ) button at the bottom of the Solutions window, which will display the New Project dialog.
) button at the bottom of the Solutions window, which will display the New Project dialog.
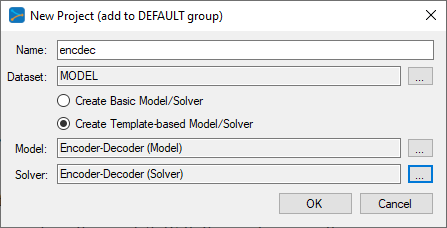
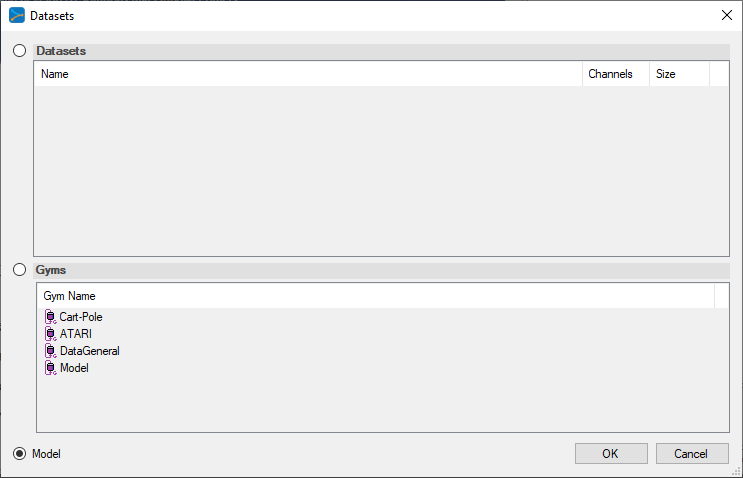
To select the MODEL dataset, click on the ‘…’ button to the right of the Dataset field and select the MODEL radio button at the bottom of the dialog.
Upon selecting OK on the New Project dialog, the new encdec project will be displayed in the Solutions window.
Step 2 – Review the Model
Now that you have created the project, lets open up the model to see how it is organized. To review the model, double click on the TranslatorNet model within the new encdec project, which will open up the Model Editor window.
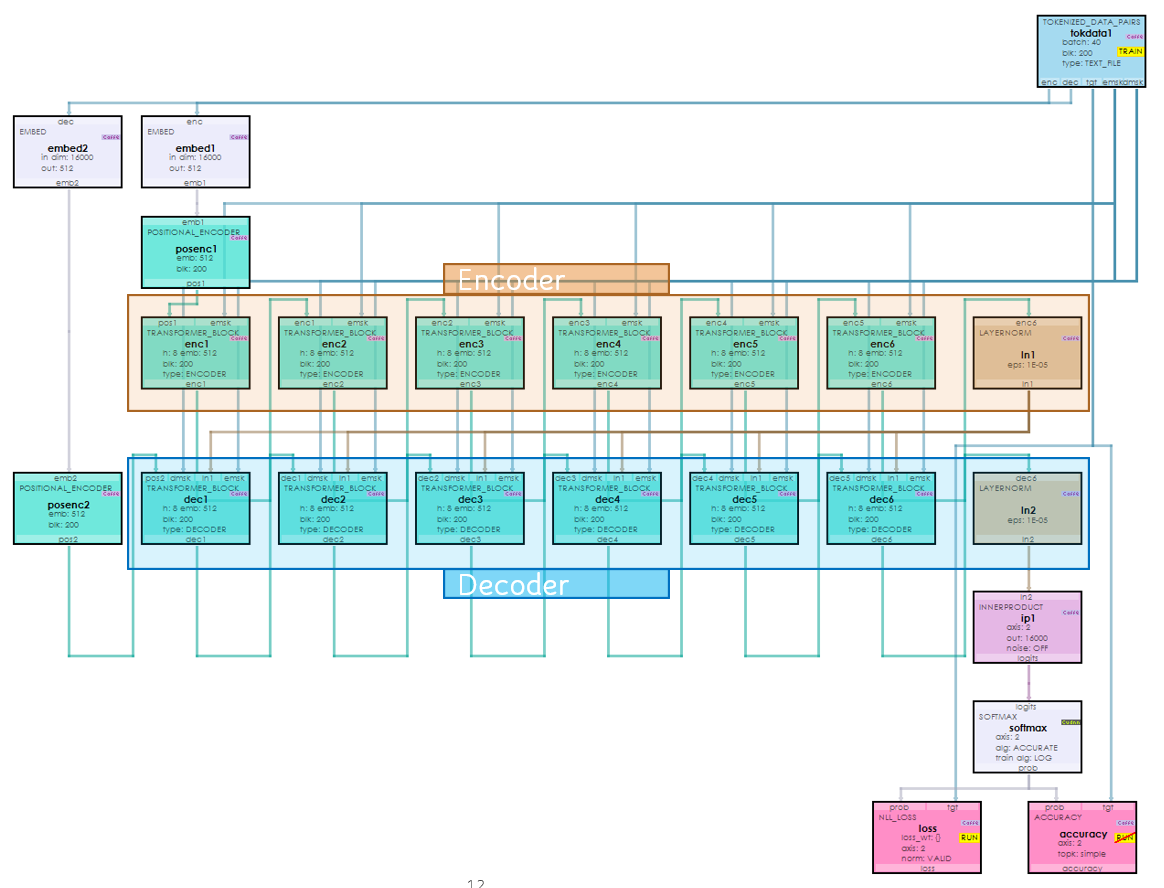
The encoder/decoder transformer model feeds tokenized data (created by the TokenizedDataPairsLayer) into two EmbedLayers that learn the embeddings of the token data and a corresponding positional data. The embeddings are then added together and fed into a stack of six Encoder TransformerBlockLayers which internally each use a MultiHeadAttentionencdec Project for Language Translation with self-attention to learn the context of the English input to be translated. The last Encoder TransformerBlockLayer feeds the data into a LayerNormLayer for normalization, which is then sent to each Decoder TransformerBlockLayer which learn the context of the French target translation and then learns the mapping between the English context and corresponding French translation’s context. The Decoder TransformerBlockLayer output is fed into a LayerNormLayer for normalization, and on to an InnerProductLayer that then produces the logits. The Logits are converted into probabilities using a SoftmaxLayer.
Each Encoder TransformerBlockLayer uses several additional layers internally.
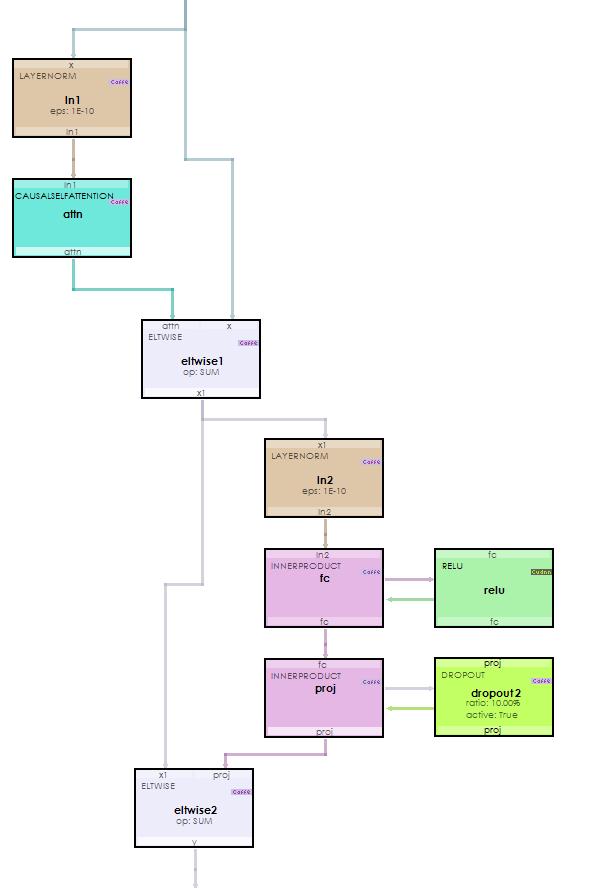
The most important of these layers is the CausalSelfAttentionLayer used to learn context via self-attention.
The Decoder TransformerBlockLayer behave similar to the Encoder TransformerBlockLayers with the additional steps 5a, 5b and 5c.
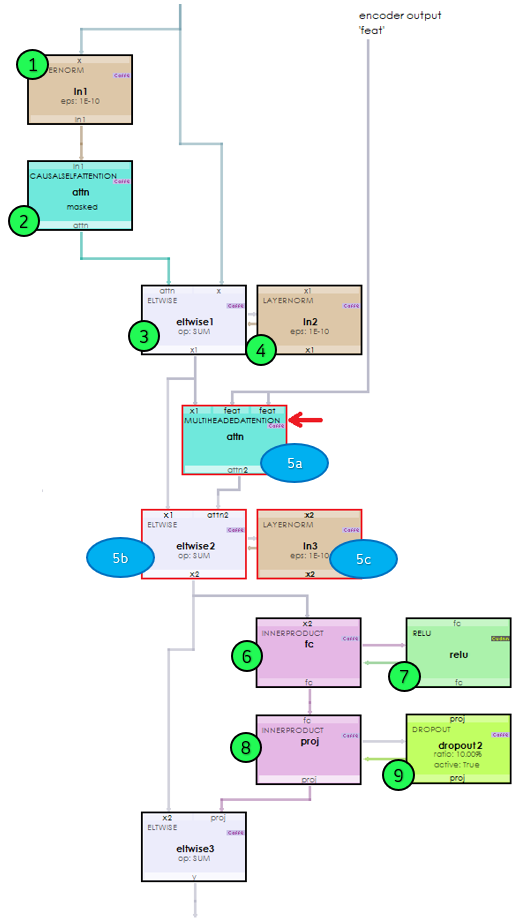
These additional steps 5a-5c are used to learn the mapping between the English context and target French translation’s context.
Step 3 – Training
The training step uses an AdamWSolver for optimization where weight decays are applied via the adamw_decay rate of 0 and the solver is run with no regularization. The base learning rate is set to 0.0001, and the optimization uses a fixed learning rate policy. The Adam momentums are set to B1 = 0.9 and B2 = 0.999 with a delta (eps) = 1e-8. Gradient clipping is turned off and therefore set clip_gradients = -1.
Initially we trained a model on an NVIDIA RTX A6000 with a batch size = 56, however we have also trained the model on an NVIDIA TitanX with a batch size = 8. When using a batch size = 8, the model used around 8GB of the TitanX’s 12GB of GPU memory.
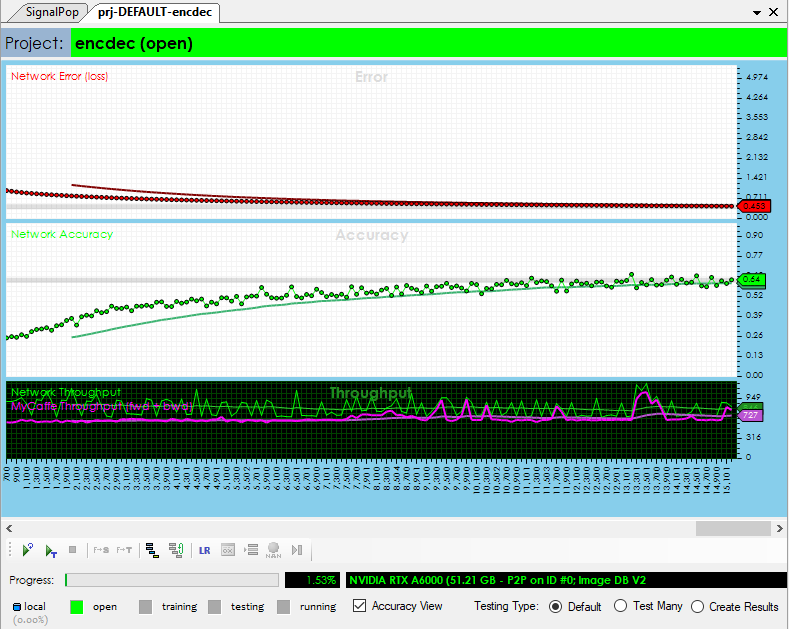
Step 4 – Running the Model
Once trained, you are ready to run the model to create a new Shakespeare like sonnet. To do this, select the Test Many testing type (radio button in the bottom right of the Project window) and press the Test (![]() ) button.
) button.
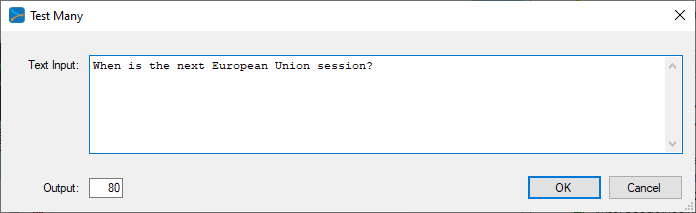
From the Test Many inputs dialog, enter the phrase “When is the next European Union session”, and select OK.
Once completed, the results are displayed in the output window.
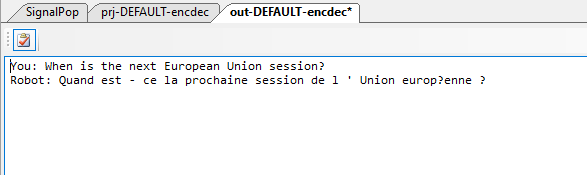
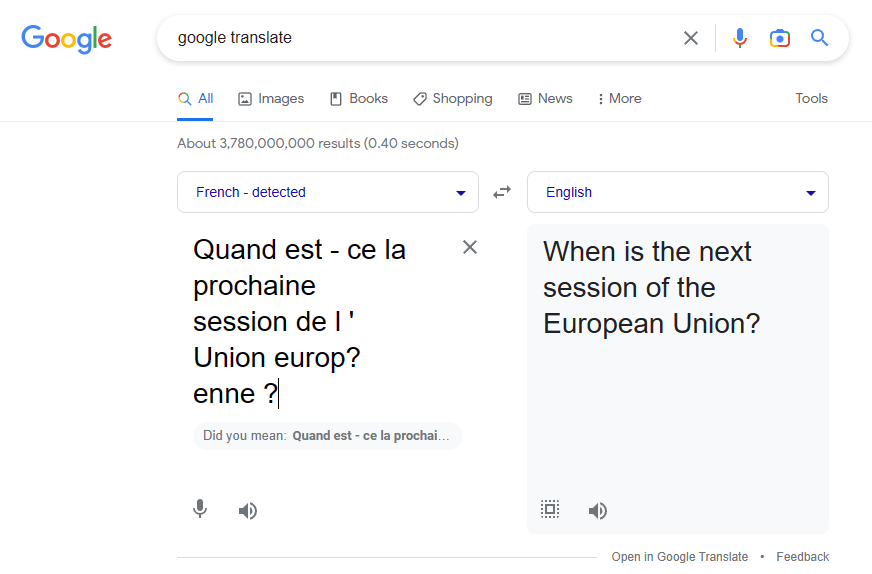
And when double checking the result with Google Translate, we see that the correct translation was produced.
Congratulations! You have now created your first Translation Net using the similar Encoder/Decoder Transformer model used by ChatGPT, but running in the SignalPop AI Designer!
To see the SignalPop AI Designer in action with other models, see the Examples page.
[1] Jaewoo (Kyle) Song GitHub: devjwsong/transformer-translator-pytorch, 2021, GitHub