

This tutorial will guide you through the steps to create a Noisy-Net based Deep Q-Learning Reinforcement Learning model as described by Fortunato et al. (Noisy-Net)[1], Schaul et. al. (Prioritized Experience Replay)[2], Castro et al. (Deep Q-Learning)[3], and The Dopamine Team (Deep Q-Learning)[4] and train it on the ATARI gym with the ATARI game ‘Breakout’ which uses the AleControl to access the Arcade-Learning-Environment [5] which is based on the ATARI 2600 Emulator created by The Stella Team [6].
Step 1 – Create the Project
In the first step we need to create a new project that contains the ATARI gym, the Noisy-Net model and the Adam solver.
To do this, first select the Add Project (![]() ) button at the bottom of the Solutions window, which will display the New Project dialog.
) button at the bottom of the Solutions window, which will display the New Project dialog.
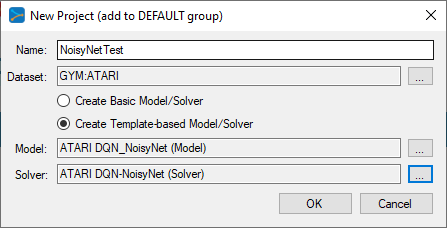
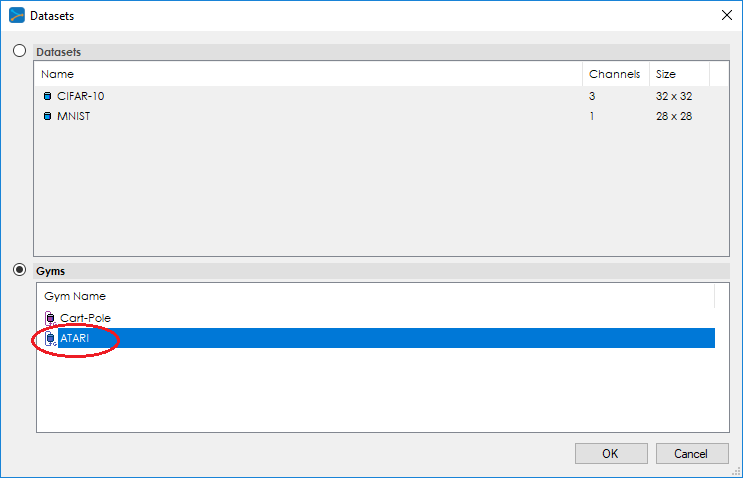
To add the ATARI gym, press the Browse (…) button to the right of the Dataset: field which will display the Datasets dialog.
Next, add the ATARI model and solver using the Browse (…) button next to the Model: and Solver: fields.
Upon selecting OK on the New Project dialog, the new PongTest project will be displayed in the Solutions window.
Step 2 – Review the Model
Now that you have created the project, lets open up the model to see how it is organized. To review the model, double click on the BasicNoisyNet model within the new NoisyNetTest project, which will open up the Model Editor window.
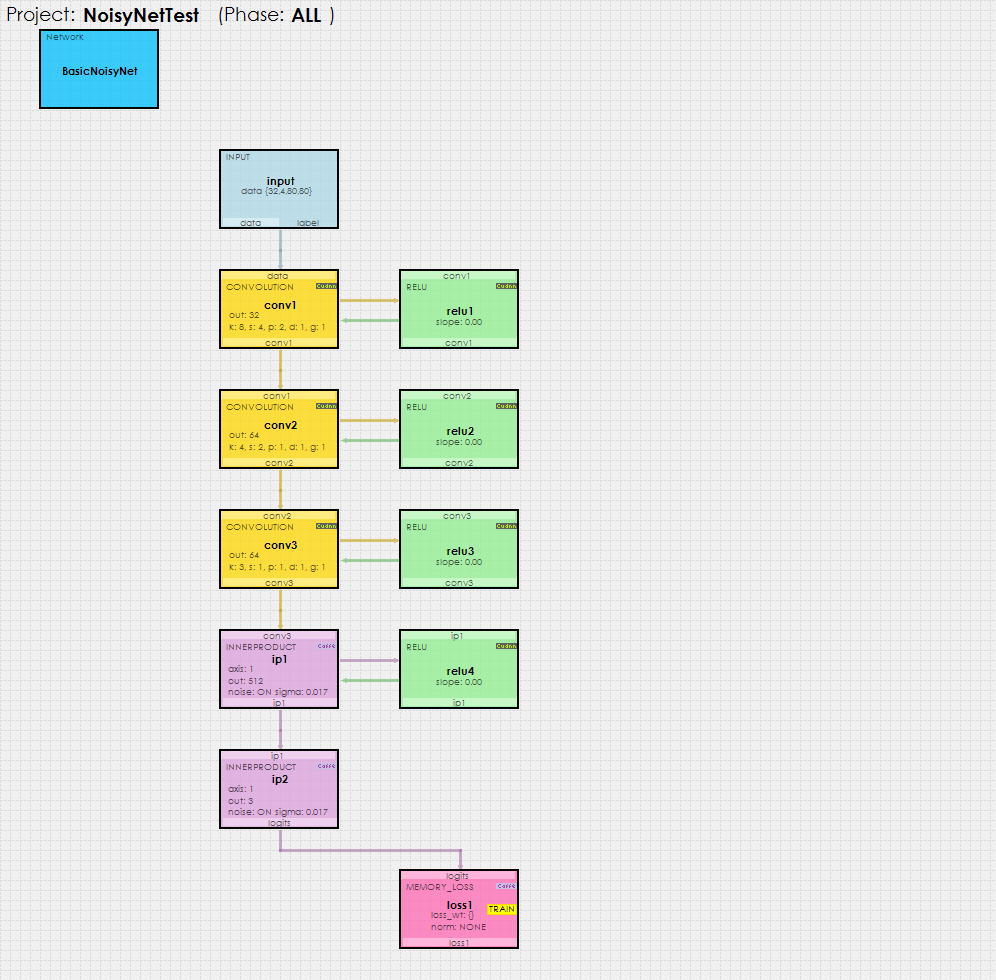
As you can see, the Noisy-Net model used with reinforcement learning is fairly simple, comprising of three CONVOLUTION layers followed by two INNERPRODUCT layers each of which have noise turned ON. NOTE: The data layer has a size of 32,4, 80, 80 which specifies to use a batch size of 32 data items each with four channels (one channel each for four frames of grayscale data) with a height x width of 80 x 80.
An Input layer feeds the batches of 32 items (each containing 4 frames), received on each step of the ATARI simulation, into the model. The data values used on each step are a series of black and white dots where white is used to color the locations of the paddles and ball as the game is played.

The actual data used contains a set of the four most recent frames of data, which are then fed into the Input layer’s data blob which is then fed down the model during the forward pass.
The last InnerProduct layer provides the network output as a set of logits which are run through an Argmax to determine which action to run.
The MemoryLoss layer calculates the loss and gradients which are then fed back up through the network during the backward pass.
Solver Settings
The Adam solver is used to solve the Deep Q-Learning Noisy-Net model with the following settings.
Learning Rate (base_lr) = 0.0001
Weight Decay (weight_decay) = 0
Momentum (momentum) = 0.9
Momentum2 (momentum2) = 0.999
Delta (delta) = 1E-08
The MyCaffeTrainerDual that trains the NoisyNetTest project uses the following specific settings.
Trainer Type = DQN.ST; use the single-threaded Deep Q-Learning trainer.
Reward Type = VAL; specifies to output the actual reward value. Other settings include MAX which only outputs the maximum reward observed.
Gamma = 0.99; specifies the discounting factor for discounted rewards.
ValueType = BLOB; specifies to use the BLOB data type as input.
InputSize = 80; specifies the input size which must match the height x width used with data layer.
GameROM = ‘path to breakout.bin’.
UseRawInput= True; specifies to use the raw input directly and not use the difference data.
Preprocess= False; specifies to not preprocess the data into black and white and instead use the data as it is (which is then normalized and centered by the trainer).
ActionForceGray=True; specifies to use gray-scale data with a single channel.
FrameSkip=1; specifies to use each frame of data (and do not skip).
AllowNegativeRewards=True; specifies to use negative rewards when the player misses the ball.
TerminateOnRallyEnd=True; specifies to set the termination state to true on the end of a rally instead of the end of a game.
EpsSteps=200000; specifies to use the random action selection over this number of iterations.
EpsStart=0.99; specifies the initial probability (99%) of selecting a random action.
EpsEnd=0.01; specifies the final probability (1%) of selecting a random action.
Note, the Eps value starts at the EpsStart value and reduces down to the EpsEnd value during each step up through EpsSteps steps.
Step 3 – Training
Now that you are all set up, you are ready to start training the model. Double click on the NoisyNetTest project to open its Project window. To start training, select the Run Training (![]() ) button in the bottom left corner of the Project window.
) button in the bottom left corner of the Project window.
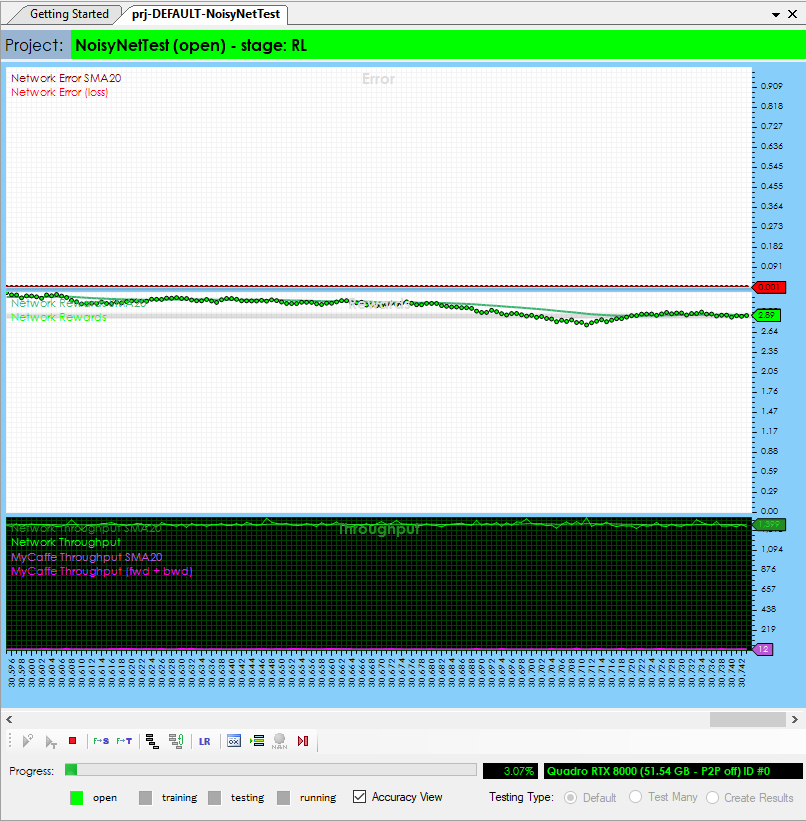
To view the ATARI Breakout gym simulation while the training is taking place, just double click on the ATARI (![]() ) gym within the NoisyNetTest project. This will open the Test Gym window that shows the running simulation.
) gym within the NoisyNetTest project. This will open the Test Gym window that shows the running simulation.
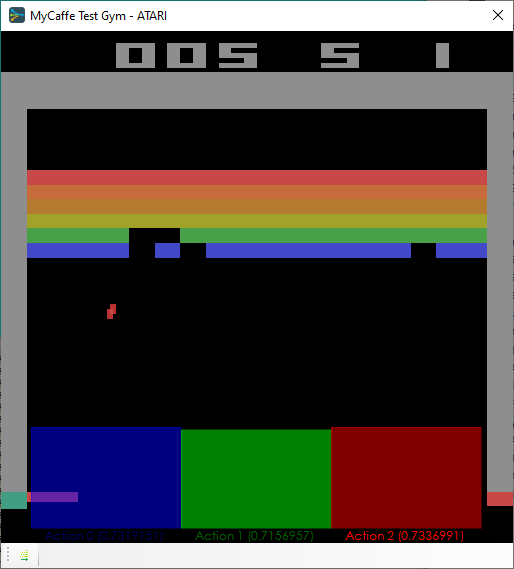
At the bottom of the Gym, the colorized actions are shown during each step of the game.
IMPORTANT: When open, the training will slow down for the rendering takes time to complete. To speed up training, merely close the window.
Congratulations! You have now built your first Deep Q-Learning reinforcement learning model with MyCaffe and trained it on the ATARI Breakout gym!
To see the SignalPop AI Designer in action with other models, see the Examples page.
[1] Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, Shane Legg, Noisy Networks for Exploration, arXiv:1706.10295, June 30, 2017.
[2] Tom Schaul, John Quan, Ioannis Antonoglou, David Silver, Prioritized Experience Replay, arXiv:1511.05952, November 18, 2015.
[3] Pablo Samuel Castro, Subhodeep Moitra, Carles Gelada, Saurabh Kumar, Marc G. Bellemare, Dopamine: A Research Framework for Deep Reinforcement Learning, arXiv:1812.06110, December 14, 2018.
[4] The Dopamine Team (Google), GitHub:Google/Dopamine, GitHub, Licensed under the Apache 2.0 License. Source code available on GitHub at google/dopamine.
[5] The Arcade Learning Environment: An Evaluation Platform for General Agents, by Marc G. Bellemare, Yavar Naddaf, Joel Veness and Michael Bowling, 2012-2013. Source code available on GitHub at mgbellemare/Arcade-Learning-Environment.
[6] Stella – A multi-platform Atari 2600 VCS emulator by Bradford W. Mott, Stephen Anthony and The Stella Team, 1995-2018. Source code available on GitHub at stella-emu/stella