

How Can We Help?
Introduction
MyCaffe
Originally, MyCaffe[1] started as a complete C# re-write of CAFFE[2] and to this day, follows the same architecture and functionality provided by the original open-source C++ CAFFE. Over time, MyCaffe has evolved and expanded its support for many more AI technologies not included in the original CAFFE, but provided by other open-source custom CAFFE branches or converted from other open-source AI solutions written in other languages for other open-source AI systems. The overall goal of MyCaffe is to provide a very easy-to-use AI platform that not only covers all aspects of the original CAFFE, but also extends out to cover all main sub-fields within the field of deep learning AI – and do so in a way that is easy to setup and start using.
The MyCaffe Programming Guide is designed to help the programmer start using MyCaffe right out of the box, so to speak. From loading data into a simple system to training a complex model, this guide will help you get started.
Deep Learning Process
When working with any deep learning AI system that uses a form of supervised learning, the typical process is to train on a set of data, and then later use that trained model for some specific purpose.
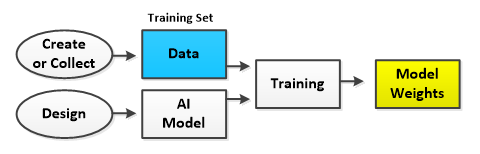
Training involves, collecting (or creating) the data which is separated into a training set and a testing set, designing the AI model and running the training process on the training set to create the model weights. The training process essentially runs each item of data through the model in a forward pass, calculates the error (or cost) which is the difference between the desired result and the actual result, and then backpropagates the portion of the error attributed to each layer back up through the model. The backpropagated error portions are called the gradients which are applied to adjust the learnable weights of layers in a direction that support learning, thus moving the overall weights closer to the desired solution.
During training, the accuracy of the AI model and weights are periodically tested by running both against the testing data set (which is separate from the training data set). When testing, weights are not adjusted and instead are just used to produce many results which are each compared against the desired results to produce the overall AI model and weight accuracy.
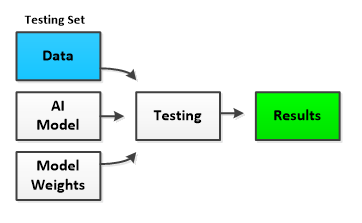
Note, the training/testing process can take a long time to complete – sometimes days, weeks or even months depending on the size of the data, complexity of the model, and available hardware. Using one or more graphics processing units (GPU’s) can greatly speed up the training process for GPU’s (such as those provided by NVIDIA) perform low-level operations in a massively parallel manner which greatly speeds up common low-level AI operations such as matrix multiplication and other BLAS functions.
Once trained to a satisfactory accuracy, the AI model and weights are ready to be used to solve the solution.
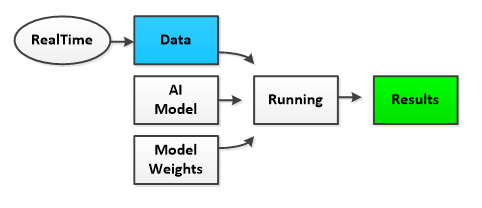
When running the AI system, often the data fed into the system is acquired in real-time from the environment. For example frames from a video, still pictures, or real-time price data from an equity market may be fed into the system to produce the desired results which respectively may be the location of objects within the video, the classification of objects within the still picture, or the direction of the next real-time equity price data that are just about to occur.
The Data Pipeline
Almost all AI systems involve a pipeline of data whereby data is acquired into memory, transformed in some manner, loaded onto one or more GPU’s and then fed through the AI model to produce the desired result.

The high speeds offered by today’s massively parallel GPU’s have shifted the overall latency somewhat to the left of the GPU memory, where now the main bottleneck resides in getting the Data into the GPU memory itself. Once data is on the GPU, we typically try to keep it there as long as possible and only take the minimal data off the GPU in order to optimize overall performance.
MyCaffe uses several techniques to improve the overall performance of the data pipeline, namely the use of the MyCaffe In-Memory Image Database, which loads data sets into memory. Acquiring data from memory is much faster than doing so from the hard drive yet loading the data into memory takes time. The MyCaffe In-Memory Image Database continually loads data into memory in on a background thread. By using the MyCaffe In-Memory Image Database, users can take advantage of low cost, high speed computer memory (RAM) which greatly improves the overall training speed of the AI system.
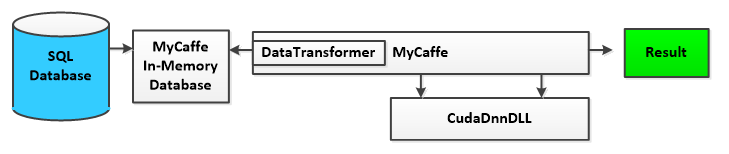
As MyCaffe loads data from the in-memory database, the DataTransformer is applied to the data which converts the data into the form that is sent to the GPU. Common data transformations may include subtracting the data mean value, adding noise, or masking out portions of the data.
For all low-level NVIDIA CUDA/GPU interactions, MyCaffe uses the CudaDnnDLL which is written in C++ and contains all CUDA specific code. Several versions of this DLL are built to support different versions of CUDA and in some cases different CUDA compute levels. The CUDA DLL file name specifies which CUDA version and compute level the DLL supports.
The MyCaffe In-Memory Database is an option provided to help MyCaffe users, but it not required. Alternatively, MyCaffe supports running in a ‘bare-bones’ manner where the in-memory database is not used at all. In this case the user is responsible for loading the data directly into MyCaffe which we will discuss in more detail later in this guide.
The AI Model
When solving an AI solution, the AI system typically uses an AI Model that describes the architecture of the deep neural net used to process the data first in a forward pass, and then in a backward pass which trains the model by adjusting the model weights.
MyCaffe uses the same text-based model script as the original CAFFE[2] to define the AI Model architecture. Once the data is loaded into memory, transformed and loaded onto the GPU, it is fed through the deep neural net that implements the AI model.
The following image displays the visual representation of a simple AI Model where data flows from the DATA layers at the top, down through the INNERPRODUCT layers and eventually to the SOFTMAXWITH_LOSS layer which calculates the cost function that we want to minimize when training the network during the backward pass.
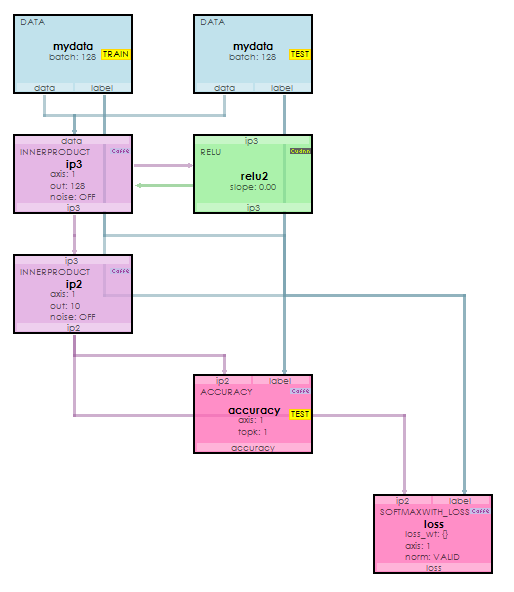
The model shown above is described using the simple proto-text descriptions that describe each layer in the model. Layers are linked by their top and bottom items where data flows out the top of one layer and into the bottom of the next. Each top and bottom item are actually BlobCollections of data that each reside on the GPU. Models allow for different phases that define which layers are used within the model. The TRAIN, TEST and RUN phases define which layers are used during training, testing and running of the model.
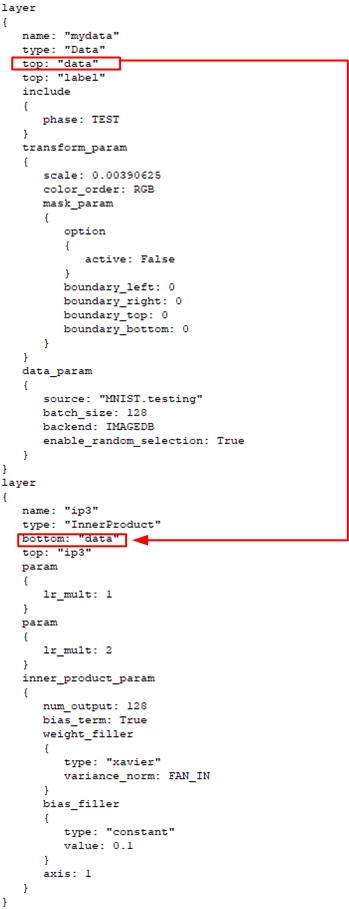
The model script snippet above shows how the DataLayer (TEST Phase) produces a top named ‘data’ that flows into the bottom of the InnerProductLayer below it.
Under the hood the model script is used by the MyCaffeControl to dynamically create the training, testing and run Net used.
The AI Solver
During the training process, the AI Model weights are used on the forward pass and adjusted after the backward pass in such a way that reduces the error produced by the cost function of the LossLayer. The MyCaffeControl uses a Solver to manage and run the overall training process making sure to update the weights while taking into account the SolverParameter settings (such as learning rate and decay) and other settings of the particular SolverType used.
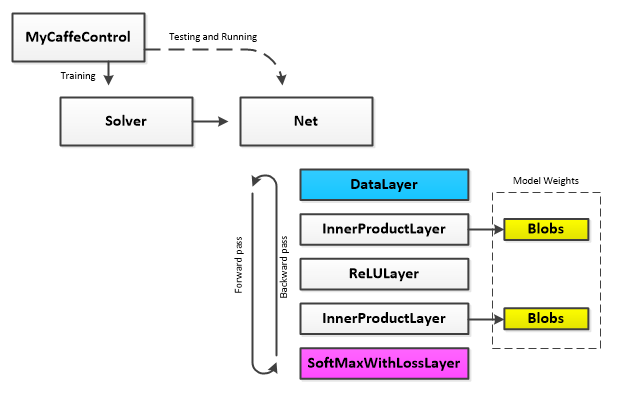
Learnable layers contain a set of ‘learnable’ parameters (e.g. the weights) which are stored in BlobCollections. During the forward pass these weights are used to calculate the output of the layer. After the backward pass completes (which calculates the gradients for each layer), the Solver applies a portion of the gradients to the weights thus moving the weights of each learnable layer closer to a solution that produces desired results.
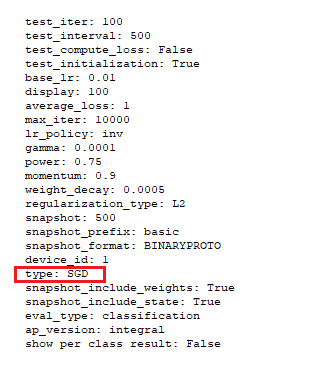
Like the AI Model, a text-based script file describes the settings of the SolverParameter used by the MyCaffeControl to create the actual Solver that trains the model.
For example, the following solver descriptor is used to create the SGDSolver for training, where the line ‘type: SGD‘ specifies the solver type to use.
To download code that demonstrates how to load data into MyCaffe with the MyCaffe Image Database see the Image Classification samples on GitHub.
To download code that demonstrates how to load data into MyCaffe without the MyCaffe Image Database, see the Bare Bones Image Classification samples on GitHub.
[1] David W. Brown MyCaffe: A Complete C# Re-Write of Caffe with Reinforcement Learning. arXiv, 2018.
[2] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, Trevor Darrell, Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv, 2014.