

This tutorial will guide you through the steps to detect objects within a directory of image files using Single-Shot Multi-Box Detection (SSD) as described by [1].
Step 1 – Create the Dataset
To create the dataset, we start with a directory full of image files, such as *.png files. For this example, we have exported image files previously created using the IMPORT.VID dataset creator.

To import these image files into our dataset, we will use the IMPORT.IMG dataset creator.
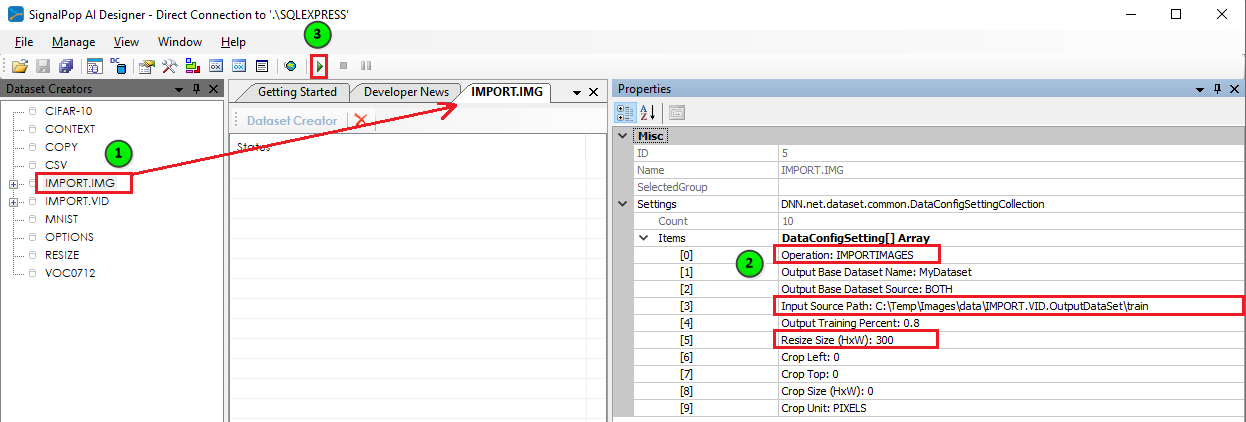
To import the image files, first (1) double click on the IMPORT.IMG dataset creator, then (2) set the following settings for this creator:
Operation: IMPORTIMAGES
Input Source Path: <locate directory containing your files>
Resize Size (HxW): 300
Although not required, we recommend that you set the resize size to 300 for your first set of tests for that size is relatively large enough to distinguish objects and does not require large amounts of GPU memory. However, if you choose to use a different size, take note later in the tutorial where you should also update the sizing used within the model.
Once you have updated the settings for the IMPORT.IMG dataset creator, you are ready to run the dataset creator to create the images – (3) press the Run button to run the dataset creator.
Step 2 – Set Initial Labels
Before you can train on the dataset you must add the labels for the object that you want to detect an initial set of annotations of those objects for the model to train.
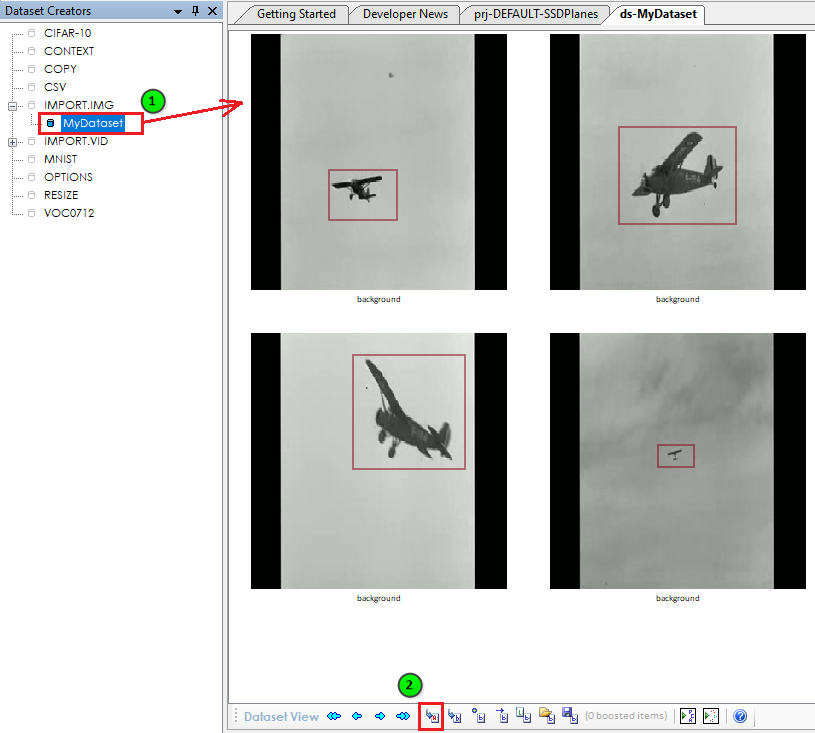
To set the labels for the entire dataset, right click on the dataset name ‘MyDataset‘ from within the Dataset Creators Pane and select the Set Labels menu item which displays the ‘Set Labels‘ dialog.
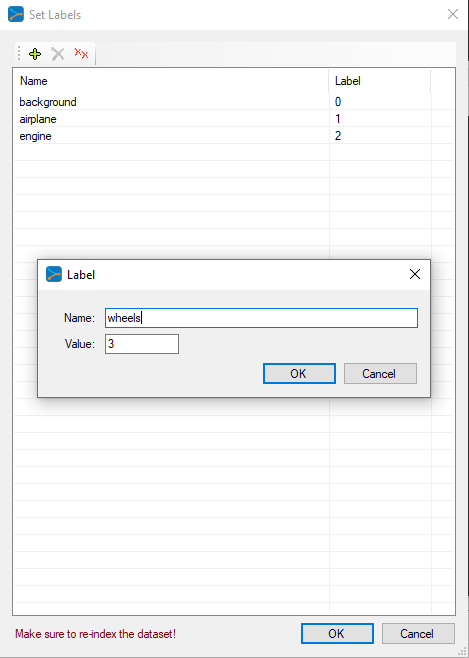
IMPORTANT: All models require that you set a background label = 0. After adding the background label, add a label for each object that you would like to detect. For our example, we have added the labels:
airplane = 1 engine = 2 wheels = 3
Along with the background label, we have a total of 4 labels.
NOTE: If you have the ‘MyDataset‘ window open, you will need to close and re-open it to refresh it with your new labels.
Step 3 – Add Initial Annotations
After adding your labels, (1) double click on the dataset to view the image frames, and then (2) double click on an image within your dataset to open the Image Viewer Dialog.
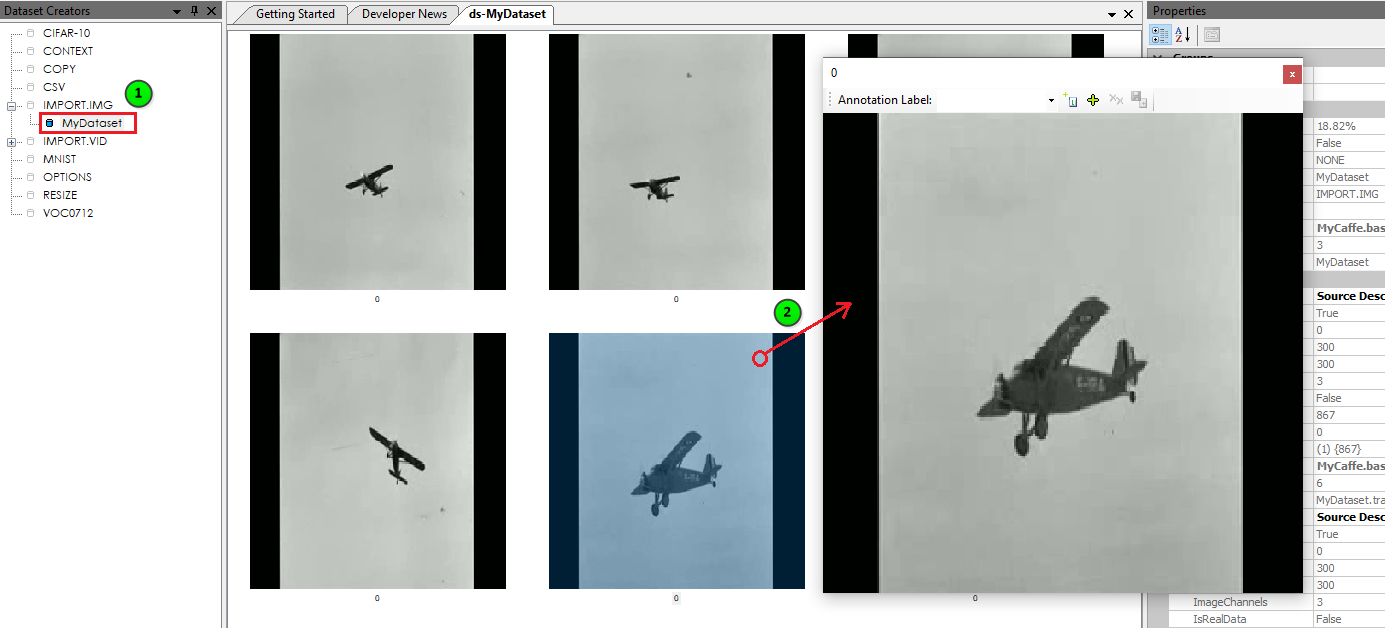
The Image Viewer Dialog is where you will draw examples of the objects that you would like to detect.
To build the training set of data, we will need to annotate a small set of images – preferably with each object that you want to detect in different background settings. To add each annotation, first select the label to annotate (e.g. airplane shown below) and the draw a box around each object of that type in the image to be annotated. Once completed, select the ‘Add’ ((![]() ) button and ‘Save’ ((
) button and ‘Save’ ((![]() ) the annotations.
) the annotations.

NOTE: When adding annotations, only add annotations of one label type per save. You can add multiple annotations of the same label per each save, but just make sure to not inter-mix labels between saves.
Step 4 – Select Initial Training Data
Once you have annotated 20-30 of your images, you will need to select the images for training and re-index the dataset.
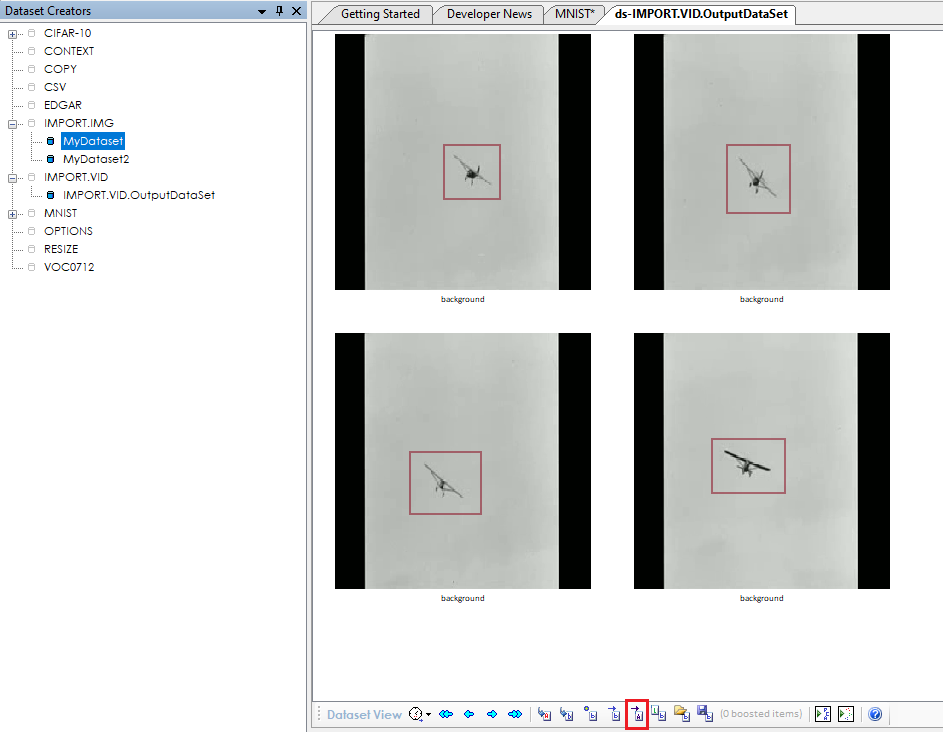
To select the training images, first click the ‘Activate annotated only‘ ((![]() ) button which will activate all annotated images in the dataset.
) button which will activate all annotated images in the dataset.
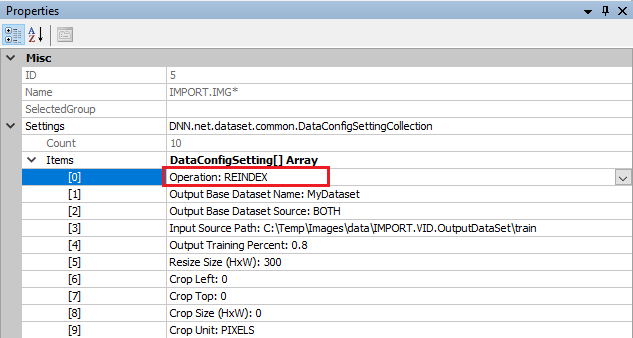
Next, the dataset must be re-indexed. To re-index the dataset, double-click on the IMPORT.IMG dataset creator and change the ‘Operation‘ to REINDEX and run the dataset by pressing the ‘Run‘ ((![]() ) button.
) button.
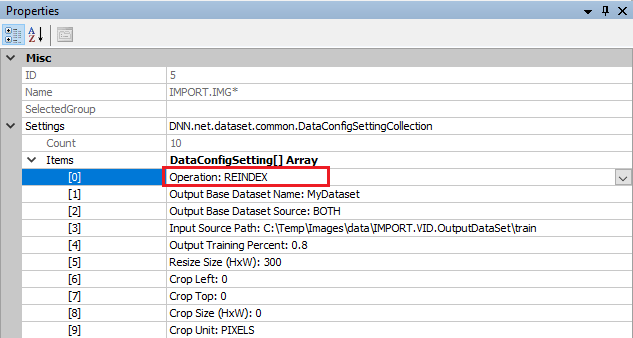
Your dataset is now ready to be used in your initial training session.
IMPORTANT: In the event you accidentally run with the IMPORTIMAGES operation instead of the REINDEX operation it may appear that you have lost your annotations. However, your annotations are not gone, it is just that you have added new duplicate images to your dataset, which will just add to the dataset. To get see your annotated images, just reselect the annotated images using the Set Labels and Boosts Dialog as shown above and then Re-Index the dataset.
Step 5 – Creating the SSD MODEL
The first step in creating a model is to select Solutions pane and then press the Add Project (![]() ) button at the bottom pane.
) button at the bottom pane.
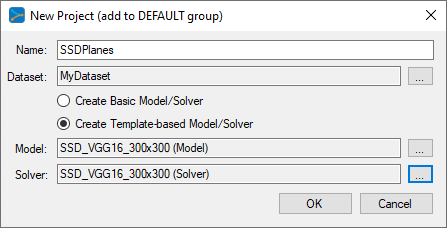
Next, fill out the New Project dialog with the project name SSDPlanes, the MyDataset dataset, and select Create Template-based Model/Solver and use the SSD_VGG16_300x300 model and SSD_VGG16_300x300 solver templates.
After pressing OK the new SSDPlanes project will be added to the solutions. Next, open the new SSDPlanes project and double click on the VGG_VOC0712_SSD_300x300 model which will open the model for editing. Clicking on the data layer for the TRAIN phase shows that the model is configured to use the MyDataset.training data source for the training set, and clicking on the data layer for the TEST phase shows that the model is configured to use the MyDataset.testing data source for the testing set.
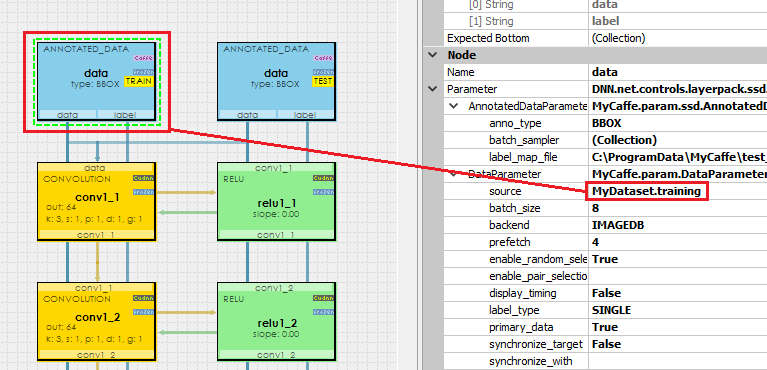
For the following steps we will only be using the MyDataset.training set of images.
NOTE: By default the model is configured to resize all images to a size of 300×300, which is also the size of image created in Step 1 above. If you do want to use larger image sizes, make sure to change the resize settings within the model to match those used when importing your images in Step 1 above.
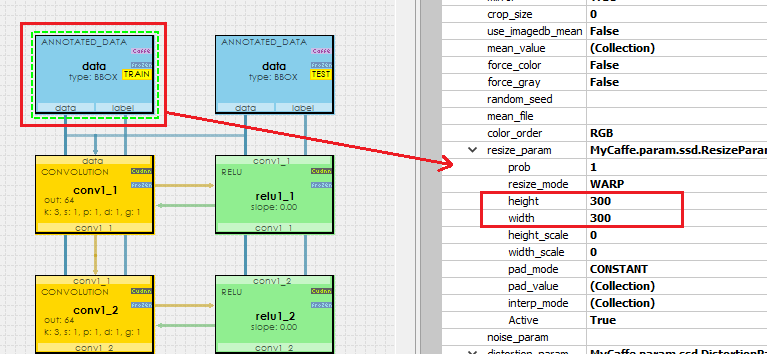
To change the model image size, click on the data layer for the TRAIN phase and scroll down in the properties to the resize_param. Set both the height and width to the desired resize – square sizes are recommended (e.g. 300 x 300).
IMPORTANT: When changing the resize_param, make sure to make this change for both the TRAIN and TEST data layers.
After making any changes save the project.
Step 6 – Initial Training
Before opening the SSDPlanes model, select it and change the following properties:
Skip Mean Check = True (no mean used) Image Load Method = LOAD_ALL (load all images into memory) Use Training Source for Testing = True (use the same training set for testing)
Next, open the project by right clicking on the project and selecting the Open menu item.
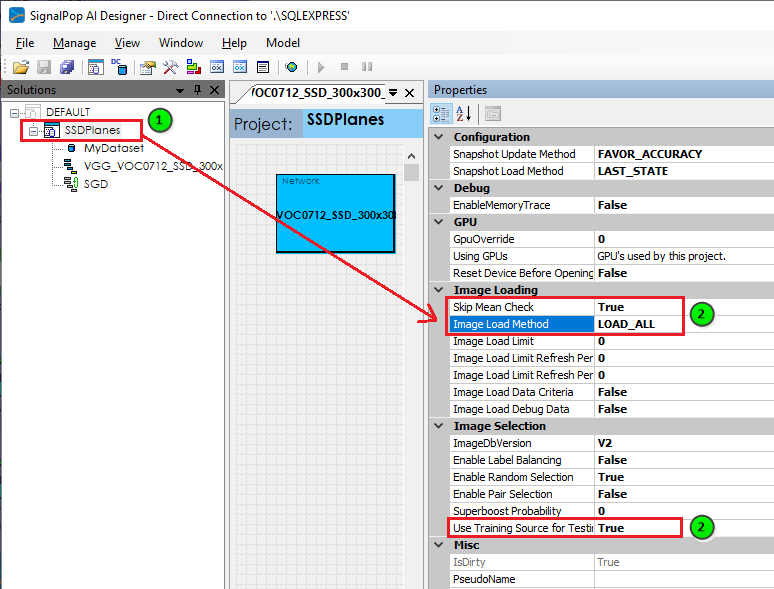
To speed up our training, we next need to import a portion of the pre-trained SSD model. Once the project completes opening, from within the Solutions window, expand the SSDPlanes project, right click on the Accuracy ((![]() ) node and select the Import menu item to import new weights.
) node and select the Import menu item to import new weights.
IMPORTANT: You can only import weights into an open project.
Select the pre-trained ‘ssd_vgg16_model.caffemodel‘ weight file installed with the SignalPop AI Designer shown below.
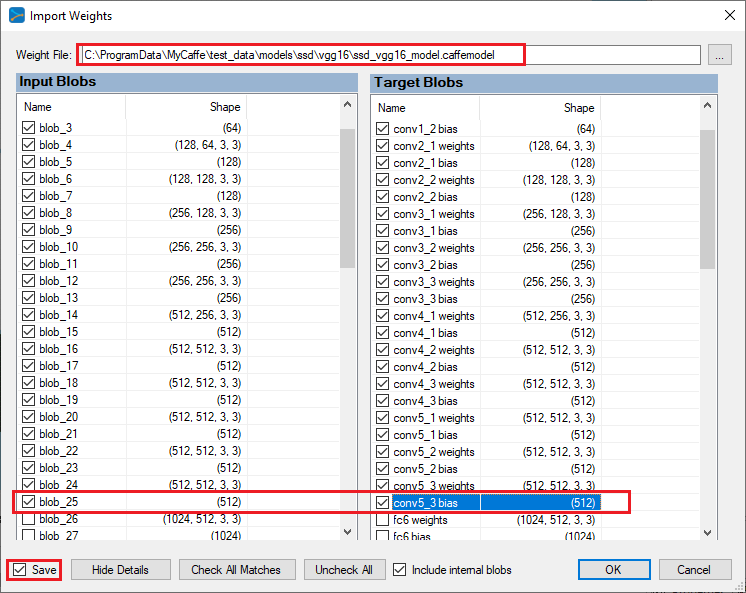 Import Pre-Trained Weights
Import Pre-Trained Weights
When importing weights, you should only import the weights for the VGG16 portion of the model (e.g. up through the conv5_3 blob) for we want the model to learn the locations of our dataset which are different from those used in the pre-trained model. Make sure to check the ‘Save‘ check-box and press OK to import the weights into your model.
While the project is open, double clicking on the Accuracy ((![]() ) node opens the project visualization viewer window. From this window, select the ‘Run weight visualization‘ ((
) node opens the project visualization viewer window. From this window, select the ‘Run weight visualization‘ ((![]() ) button to view the imported weights which should look something like the following.
) button to view the imported weights which should look something like the following.
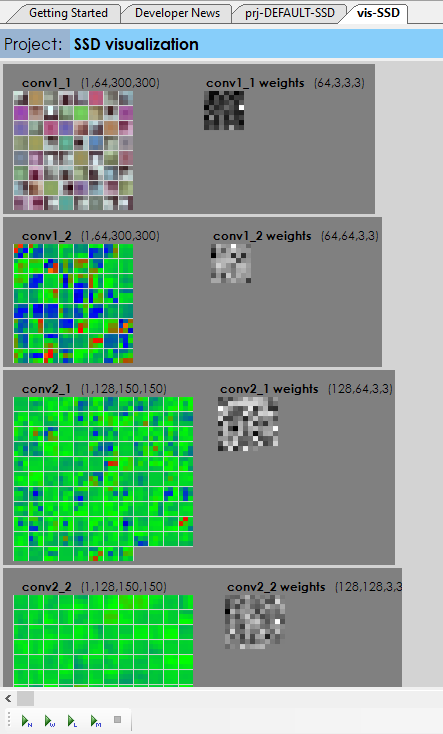
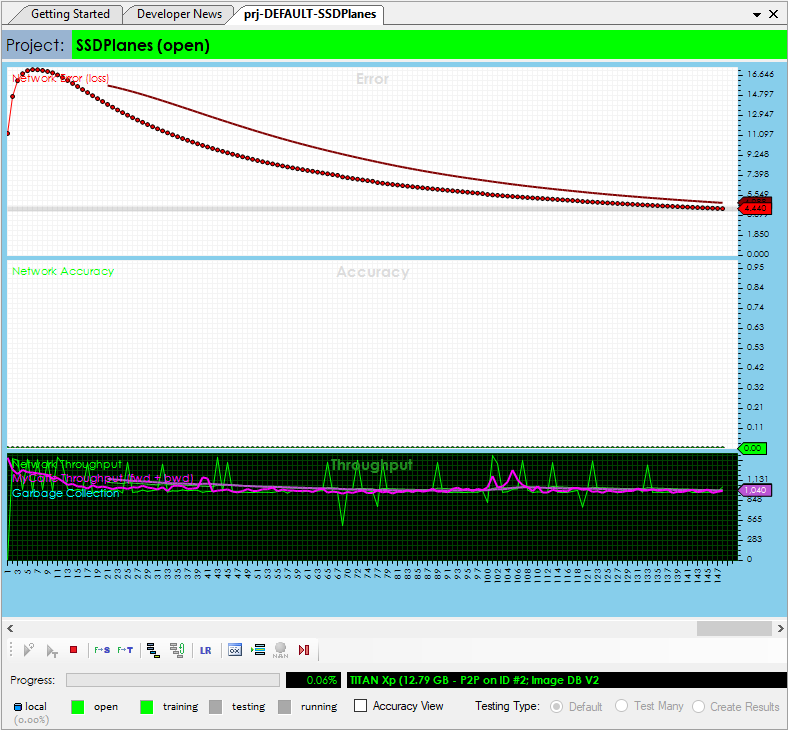
If they do, you are now ready to start the initial training session. To start training, double click on the SSDPlanes project to open its project window and then select the Run Training ((![]() ) button. Run the training for around 200-300 iterations on your initial training for we want to learn the model just enough to help you expand your annotation selections.
) button. Run the training for around 200-300 iterations on your initial training for we want to learn the model just enough to help you expand your annotation selections.
Step 7 – Expand your Annotations
Now that you have a trained model, it is time to expand your annotations from the initial 20-30 images annotated to a larger set to be used on the next training session.
To expand the annotations, first stop the training and close the project. Next, go back to the ‘Dataset Creators’ pane for you will need to re-activate all images within your dataset.
Double-click on your MyDataset dataset with in the Dataset Creators pane to open the dataset, and select the ‘Activate all images‘ ((![]() ) button.
) button.
After activating all images, you need to re-index the dataset. To do that, double click on the IMPORT.IMG dataset creator and change the Operation to REINDEX.
The active images within the dataset now contain a mix of some annotated and a lot of non-annotated images, which is what we want for next the model will be used to help us annotate the images in a much faster way.
Now, go back to the Solutions tab and re-open your project to reload the full image set. Once opened, double-click on the SSDPlanes project to open its project window.
This time, instead of training the project, we are going to run its ‘Test All‘ function on 100-200 images from the dataset (many of which do not have any annotation data).
IMPORTANT: Make sure to check the ‘Use Training Dataset’ when running the test for we want to expand the annotations in the training dataset.
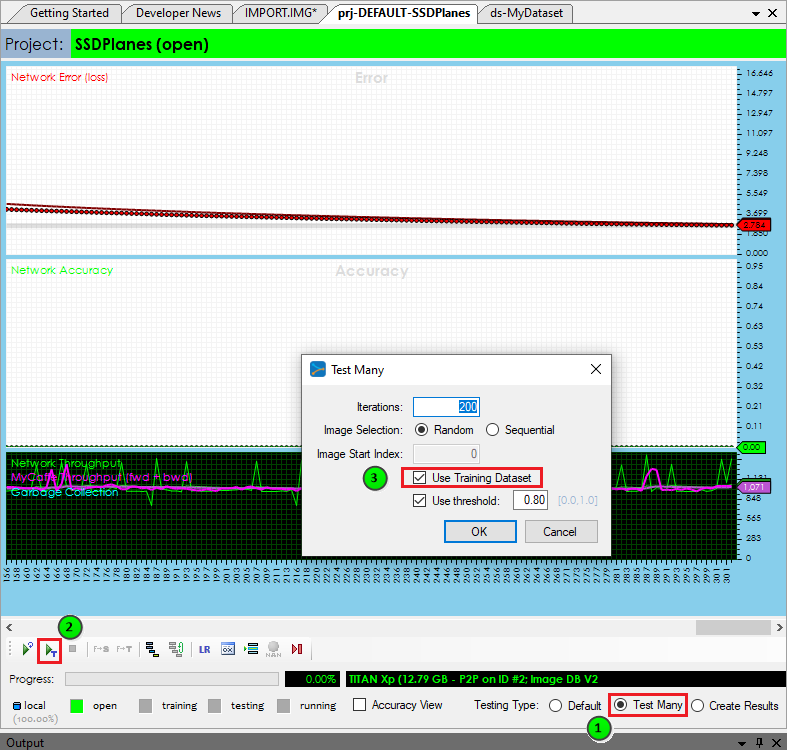
From the project window, check the ‘Test Many‘ radio button and then select the ‘Run Testing‘ (![]() ) button and select 100 images to test.
) button and select 100 images to test.
Upon completing (testing more than 300 images can take some time) the ‘Test Many Results‘ window is displayed.
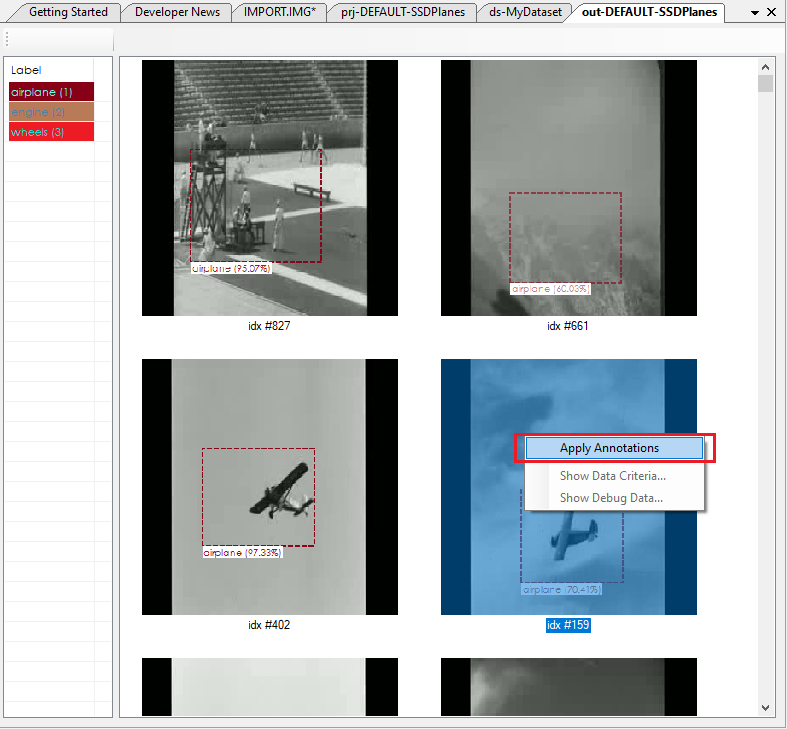
Right click on each detection that looks good to you and select the ‘Apply Annotations‘ menu-item to add the new annotations to your dataset. This process allows you to quickly build up your dataset from a very small sub-set used during training.
Once you have added a sufficient number of new annotations, repeat the steps starting at step 3 above and soon your model will be ready to run and detect the objects that you have trained your model to detect.
Congratulations, you have now created a model ready to be used with the MyCaffeControl to detect objects in C#!
For a cool example showing the object detection in action, see how it works, check out the Object Detection blog post.
[1] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg, SSD: Single Shot MultiBox Detector, arXiv:1512.02325, 2016.