

In our latest release, version 0.11.1.56, we have added support for object detection using Single-Shot Multi-Box Detection (SSD) as described in [1] and do so with the newly released CUDA 11.1 and cuDNN 8.0.4!

With SSD, one can easily and quickly detect multiple objects within images as shown above, and/or video frames as shown below.
In the video above, the airplane, engine and wheels are detected using the MyCaffe AI Platform.
In the video above gas leaks are shown in the field. This video, provided by Sierra-Olympia Technologies, was filmed using the Ventus OGI 640×512 resolution MWIR camera. Gas leaks were detected using the MyCaffe AI Platform.
How Does This Work?
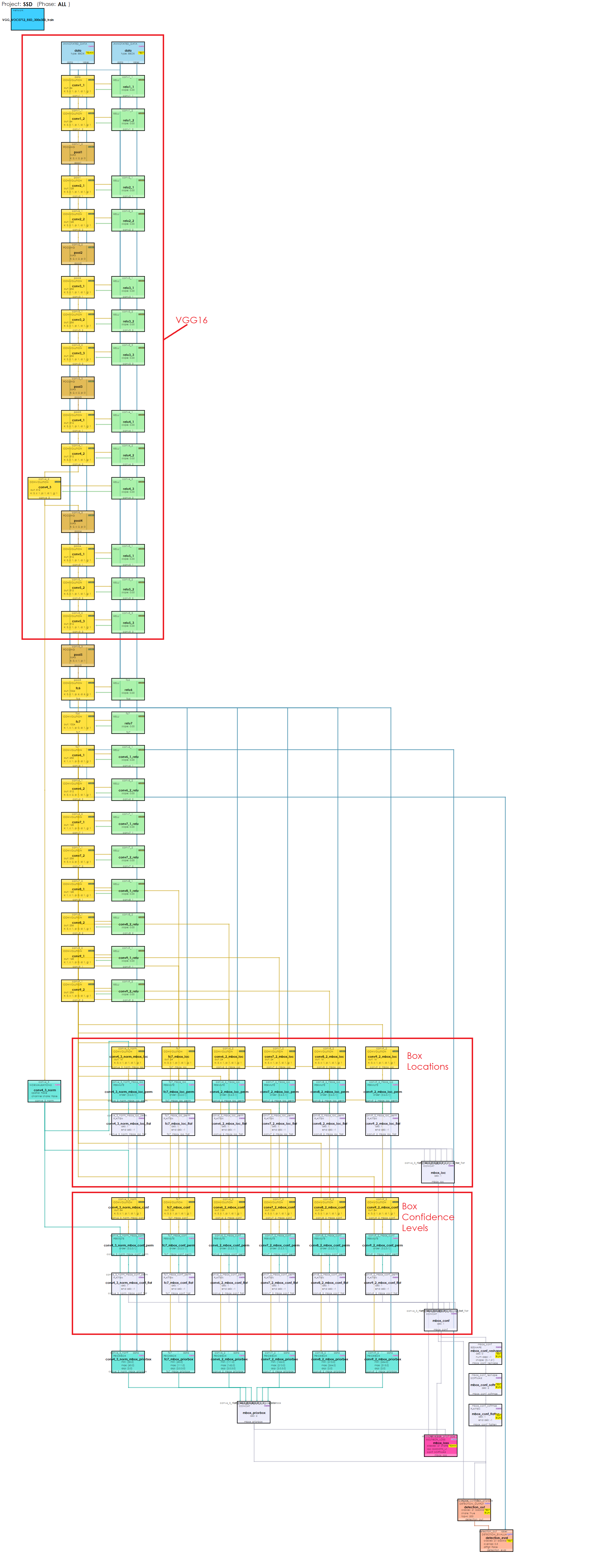
The MyCaffe AI Platform now implements the data annotations used to locate and label each object and the new layers needed to detect them, such as the new Permute, PriorBox, MultiBoxLoss, DetectionOutput and DetectionEvaluation layers to create the fairly complex SSD model – 105 layers in all.
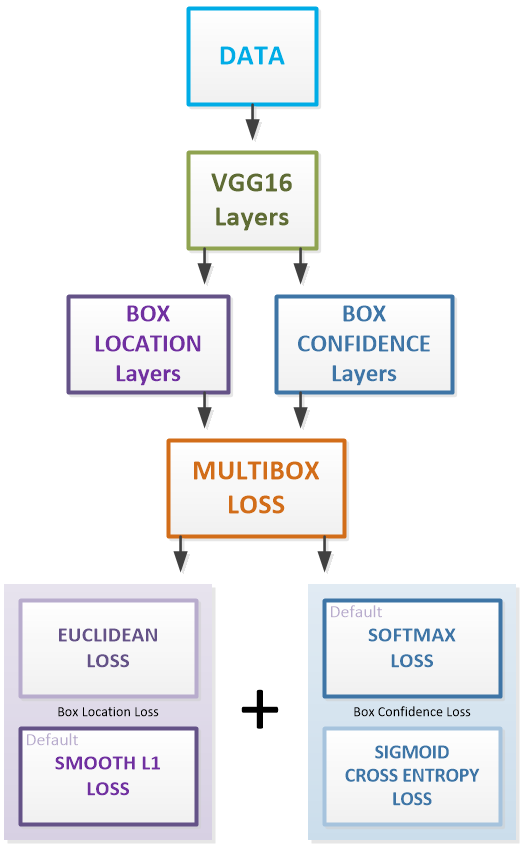
Essentially, the SSD model is a merge between the VGG16 model (used to extract image features) and the single-shot multi-box model (used to detect objects and their locations). The VGG16 layers feed into a set of layers used to detect the box locations and also into a separate set of layers used to detect the confidence levels for the object within each box. Together, the box location layers and confidence layers are fed into the MultiBoxLoss layer which then merges the confidence loss calculation with the box confidence loss calculation. When calculating the box location loss, either a Euclidean loss or smooth L1 loss is used, with the latter being the default. And, when calculating the box confidence loss, either a sigmoid cross entropy loss or softmax loss is used, with the latter being the default.
All together, this creates a pretty complex model as shown below.
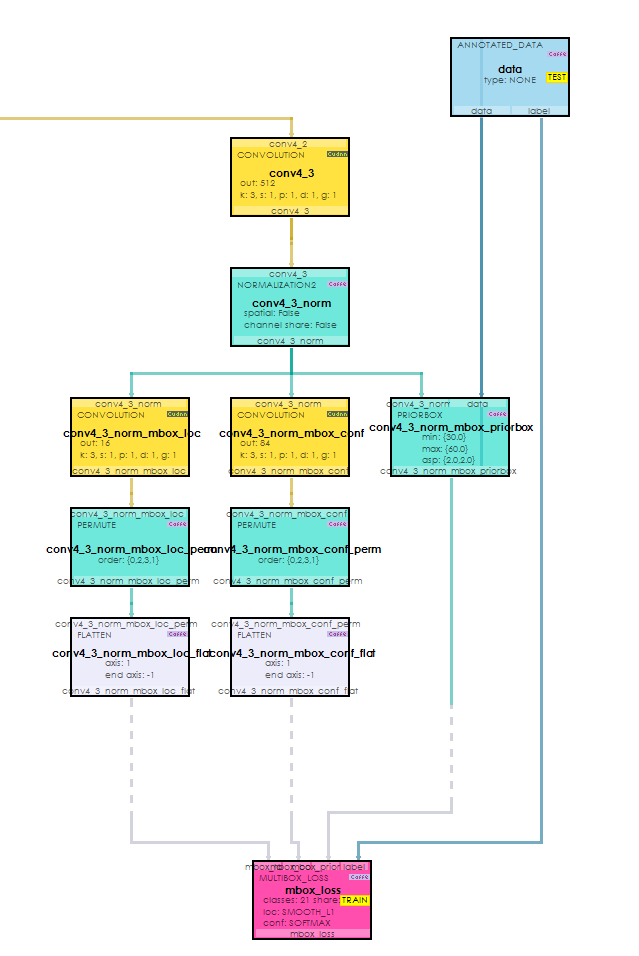
After digesting this model for a bit, you will see that the following simplification shows how the various layers flow into the MultiBoxLoss layer.
Using the new SignalPop AI Designer’s annotation editor, you can now easily create new datasets to train and run the SSD model on!
To try out the SSD model for yourself, see the new SSD video tutorial which walks you through creating your own annotated dataset from an MVW video and training a new SSD model on it. Also, see the new SSD image tutorial which walks you through creating your own annotated dataset from a directory of images and training a new SSD model on them.
New Features
The following new features have been added to this release.
- CUDA 11.1.0/cuDNN 8.0.4 support added.
- Upgraded all builds to Visual Studio 2019.
- Added SSD TestAll support showing predicted boxes and classes.
- Added SSD data annotation editor for building datasets.
- Added SSD results annotation selector for expanding datasets.
- Added new IMPORT.VID dataset creator used to import videos.
- Added ability to set default CudaDnnDll location.
Bug Fixes
The following bugs have been fixed in this release.
- Fixed database transient errors with new database connection strategy used with the SignalPop Universal Miner distributed AI support.
- Fixed bugs related to running on International versions of Windows 10.
- Fixed bug related to double clicking on target datasets.
For other great examples, including, Neural Style Transfer, beating ATARI Pong and creating new Shakespeare sonnets, check out our Examples page.
[1] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg, SSD: Single Shot MultiBox Detector, arXiv:1512.02325, 2016.