

In our latest release, version 0.10.0.76, we now support multi-threaded, Policy Gradient Reinforcement Learning on the Arcade-Learning-Environment [4] (based on the ATARI 2600 emulator [5]) as described by Andrej Karpathy[1][2][3], and do so with the recently released CUDA 10.0.130/cuDNN 7.3.1.
Using the simple Sigmoid based policy gradient reinforcement learning model shown below…
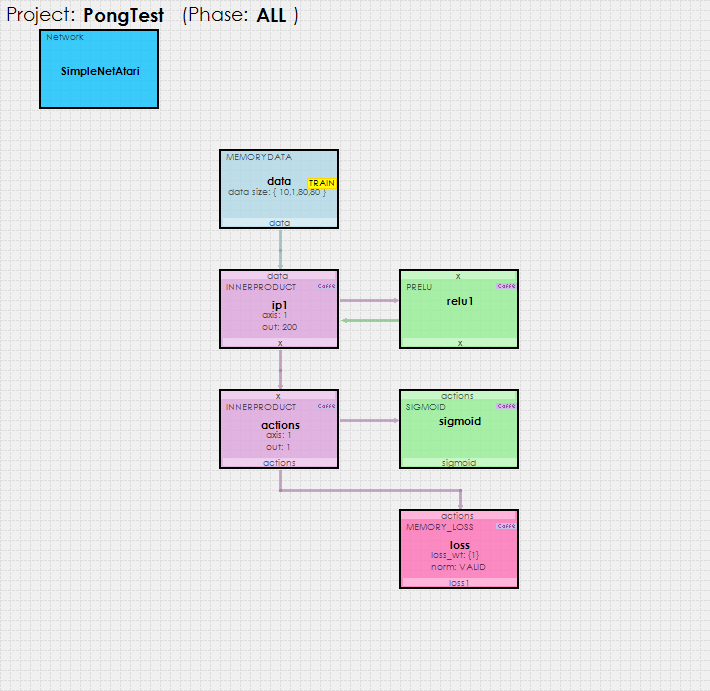
… the SignalPop AI Designer uses the MyCaffeTrainerRL to train the model to play ATARI Pong better than ATARI!
To try out this model and train it yourself, just check out our Tutorials for easy step-by-step instructions that will get you started quickly! For cool example videos, including a Cart-Pole balancing video, check out our Examples page.
New Features
The following new features have been added to this release.
- CUDA 10.0.130/cuDNN 7.3.1/driver 411.70 and 416.16 support added.
- Added new ATARI Gym support.
- Added random exploration support.
- Added ability to turn on/off policy gradient accelerated learning.
Bug Fixes
The following bug fixes have been made in this release.
- Fixed bugs related to accumulating gradients and models with null diffs.
- Fixed bugs in discounted return calculation.
- Fixed bugs in Blob.NormalizeData.
- Fixed bugs in ATARI results not showing in Project Window (0.10.0.76)
- Fixed bugs in running Test on gyms (0.10.0.76)
New Publications
[1] Karpathy, A., Deep Reinforcement Learning: Pong from Pixels, Andrej Karpathy blog, May 31, 2016.
[2] Karpathy, A., GitHub:karpathy/pg-pong.py, GitHub, 2016.
[3] Karpathy, A., CS231n Convolutional Neural Networks for Visual Recognition, Stanford University.
[4] The Arcade Learning Environment: An Evaluation Platform for General Agents, by Marc G. Bellemare, Yavar Naddaf, Joel Veness and Michael Bowling, 2012-2013. Source code available on GitHub at mgbellemare/Arcade-Learning-Environment.
[5] Stella – A multi-platform Atari 2600 VCS emulator by Bradford W. Mott, Stephen Anthony and The Stella Team, 1995-2018. Source code available on GitHub at stella-emu/stella