

In our latest release, version 0.10.0.24, we now support multi-threaded, SoftMax based Policy Gradient Reinforcement Learning as described by Andrej Karpathy[1][2][3], and do so with the recently released CUDA 10.0.130/cuDNN 7.3.
Using the simple SoftMax based policy gradient reinforcement learning model shown below…
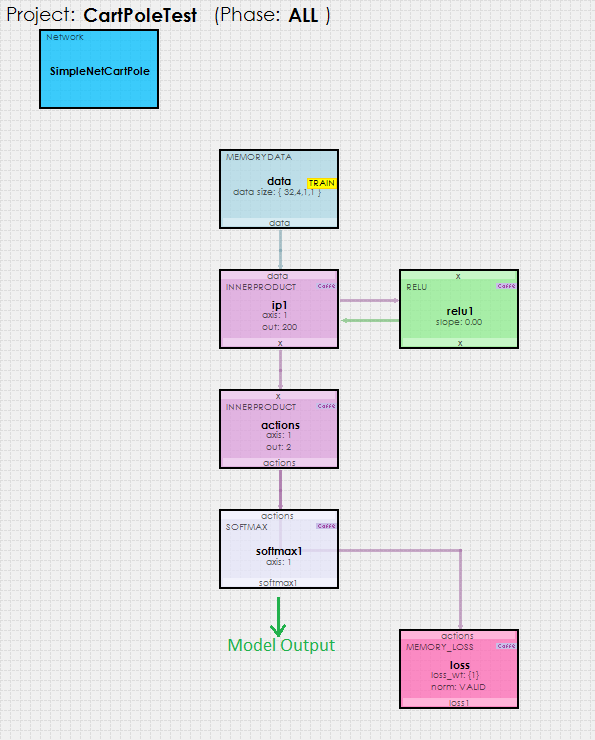
… the SignalPop AI Designer uses the MyCaffeTrainerRL to train the model to solve the Cart-Pole problem and balance the pole.
To use the MyCaffeTrainerRL, just set the custom_trainer Solver property to RL.Trainer and you are ready to go.
To try out this model and train it yourself, just check out our Tutorials for easy step-by-step instructions that will get you started quickly! For cool example videos, including a Cart-Pole balancing video, check out our Examples page.
New Features
The following new features have been added to this release.
- CUDA 10.0.130/cuDNN 7.3/driver 411.63 support added.
- Added SoftMax support to Policy Gradient Reinforcement Learning.
- Added multi-threading support to Policy Gradient Reinforcement Learning (across GPU’s).
Bug Fixes
The following bug fixes have been made in this release.
- Fixed bug Policy Gradient accumulation, speeding up learning by 3x!
- Fixed bug in snapshots related to Policy Gradient learning.
[1] Karpathy, A., Deep Reinforcement Learning: Pong from Pixels, Andrej Karpathy blog, May 31, 2016.
[2] Karpathy, A., GitHub:karpathy/pg-pong.py, GitHub, 2016.
[3] Karpathy, A., CS231n Convolutional Neural Networks for Visual Recognition, Stanford University.