

In our latest release, version 0.9.2.188, we now support Policy Gradient Reinforcement Learning as described by Andrej Karpathy[1][2][3], and do so with the recently released CUDA 9.2.148 (p1)/cuDNN 7.2.1.
For training, we have also added a new Gym infrastructure to the SignalPop AI Designer, where the dataset in each project can either be a standard dataset, or a dynamic gym dataset, such as the Cart-Pole gym inspired by OpenAI[4][5] (originally created by Richard Sutton et al. [6][7]).
Using a simple policy gradient reinforcement learning model shown below…
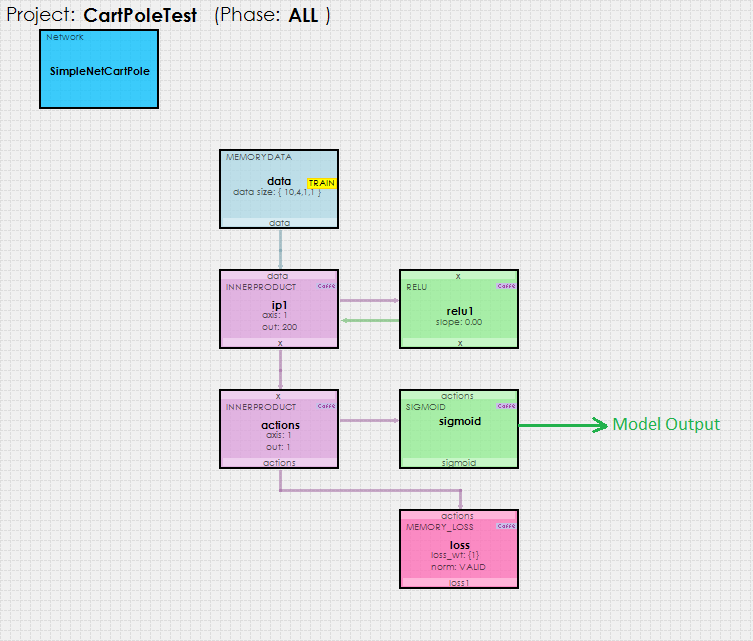
… the SignalPop AI Designer uses the new MyCaffeTrainerRL to train the model to solve the Cart-Pole problem and balance the pole.
To use the MyCaffeTrainerRL, just set the custom_trainer Solver property to RL.Trainer and you are ready to go.
To try out this model and train it yourself, just check out our Tutorials for easy step-by-step instructions that will get you started quickly! For other cool example videos, check out our Examples page.
New Features
The following new features have been added to this release.
- CUDA 9.2.148 (p1)/cuDNN 7.2.1/driver 399.07 support added.
- Added support for Policy Gradient Reinforcement Learning via the new MyCaffeTrainerRL.
- Added new Gym support via the new Gym dataset type along with the new Cart-Pole gym.
- Added a new MemoryLoss layer.
- Added a new SoftmaxCrossEntropyLoss layer.
- Added a new LSTMSimple layer.
- Added layer freezing to allow for each Transfer Learning.
Bug Fixes
The following bug fixes have been made in this release.
- Fixed bug in LOAD_FROM_SERVICE (was not working)
- Fixed bugs in Label Visualization.
- Fixed bugs in Weight Visualization.
- Fixed bugs related to Importing Weights.
[1] Karpathy, A., Deep Reinforcement Learning: Pong from Pixels, Andrej Karpathy blog, May 31, 2016.
[2] Karpathy, A., GitHub:karpathy/pg-pong.py, GitHub, 2016.
[3] Karpathy, A., CS231n Convolutional Neural Networks for Visual Recognition, Stanford University.
[4] OpenAI, CartPole-V0.
[5] OpenAI, GitHub:gym/gym/envs/classic_control/cartpole.py, GitHub, April 27, 2016.
[6] Barto, A. G., Sutton, R. S., Anderson, C. W., Neuronlike adaptive elements that can solve difficult learning control problems, IEEE, Vols. SMC-13, no. 5, pp. 834-846, September 1983.
[7] Sutton, R. S., et al., incompleteideas.net/sutton/book/code/pole.c, 1983.