

In our latest release, version 0.10.0.140, we have added CUDNN engine support to the LSTM layer to solve the Char-RNN 5x faster than when using the CAFFE engine. As described in our last post, the CAFFE version (originally created by Donahue et al. [1]) uses an internal Unrolled Net to implement the recurrent nature of the learning. The cuDNN LSTM implementation [2] further accelerates the LSTM algorithm [3][4] by combining multiple LSTM/Dropout layered operations into a single layer, dramatically speeding up the model load time (67% faster), the model training (5x faster!) and reducing the memory use (33% less) from the CAFFE engine version.
When using the Char-RNN with the CUDNN engine based LSTM Layer, the model looks as follows.
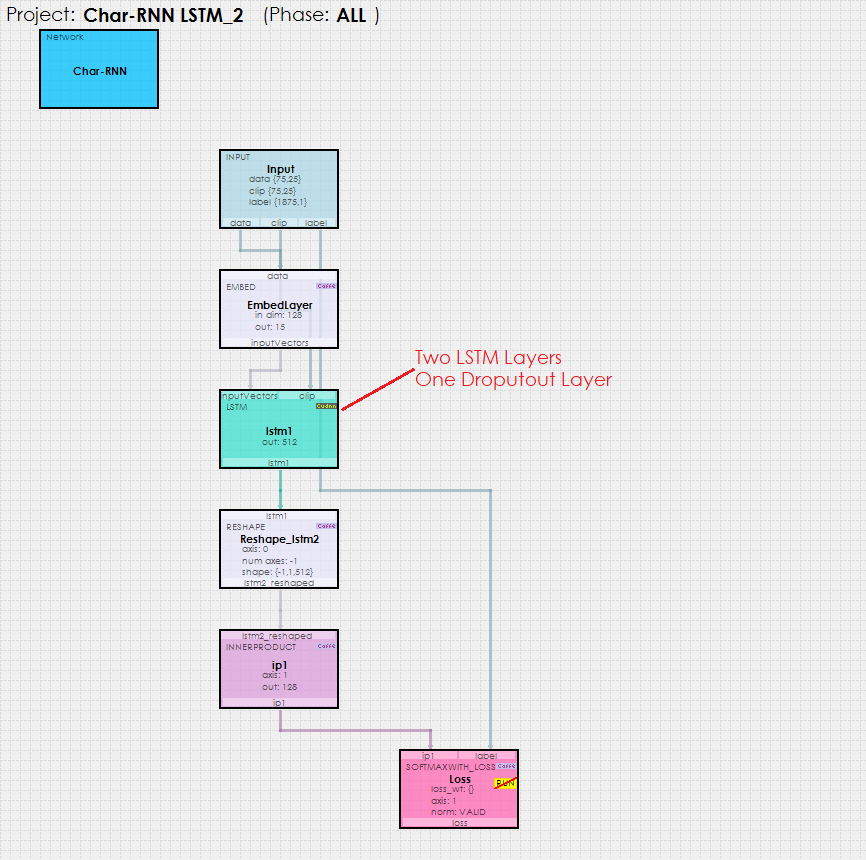
Using the CUDNN version of the LSTM layer dramatically simplifies the model, but does not reduce the functionality nor internal complexity. In fact, by moving the unrolled operations down to the cuDNN level, the model runs much more efficiently for cuDNN more effectively uses the GPU.
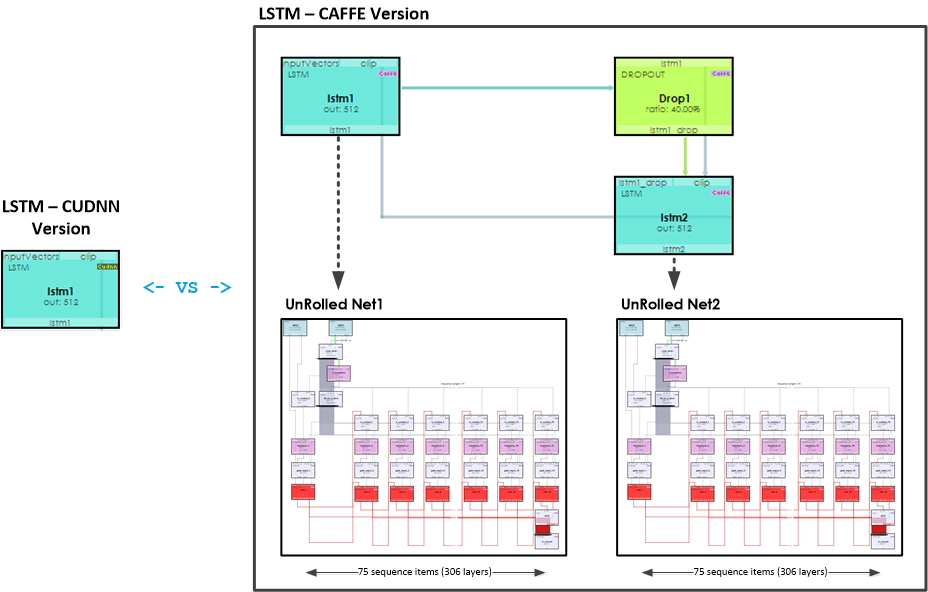
Visually comparing the two implementations gives a better idea of the amount of work actually being performed by cuDNN when running the LSTM for training and testing. The ‘lstm1’ layer on the left (that uses the CUDNN engine), replaces all of the operations taking place in the ‘lstm1’, ‘lstm2’ LSTM and ‘Drop1’ DROPOUT nodes on the right (that use the CAFFE engine) — and this includes replacing the two Unrolled Net’s used by each of the LSTM (CAFFE engine) layers!
The amount of work performed by the cuDNN version of LSTM is also seen when comparing the amount of work performed by the GPU when training each model. Using the free SignalPop Universal Miner, we can visually see how hard each GPU is working while training both models simultaneously on two separate NVIDIA Titan Xp GPUs (both running in TCC mode). The cuDNN version of LSTM provides a more efficient use of the GPU by using over twice as much of the GPU processing capacity as the Caffe version – and not surprisingly also generates more heat.
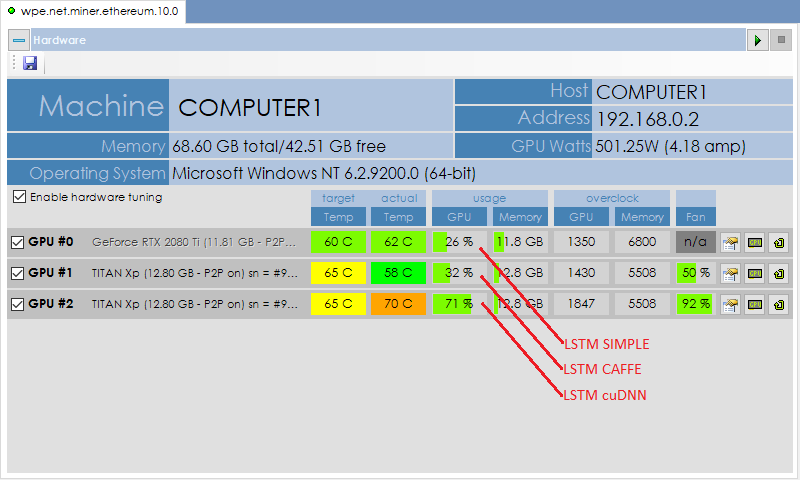
Given that the cuDNN version of LSTM can generate a lot of heat, we have found the dynamic cooling control, provided by the SignalPop Universal Miner, to be helpful in maintaining cooler GPU temperatures while training.
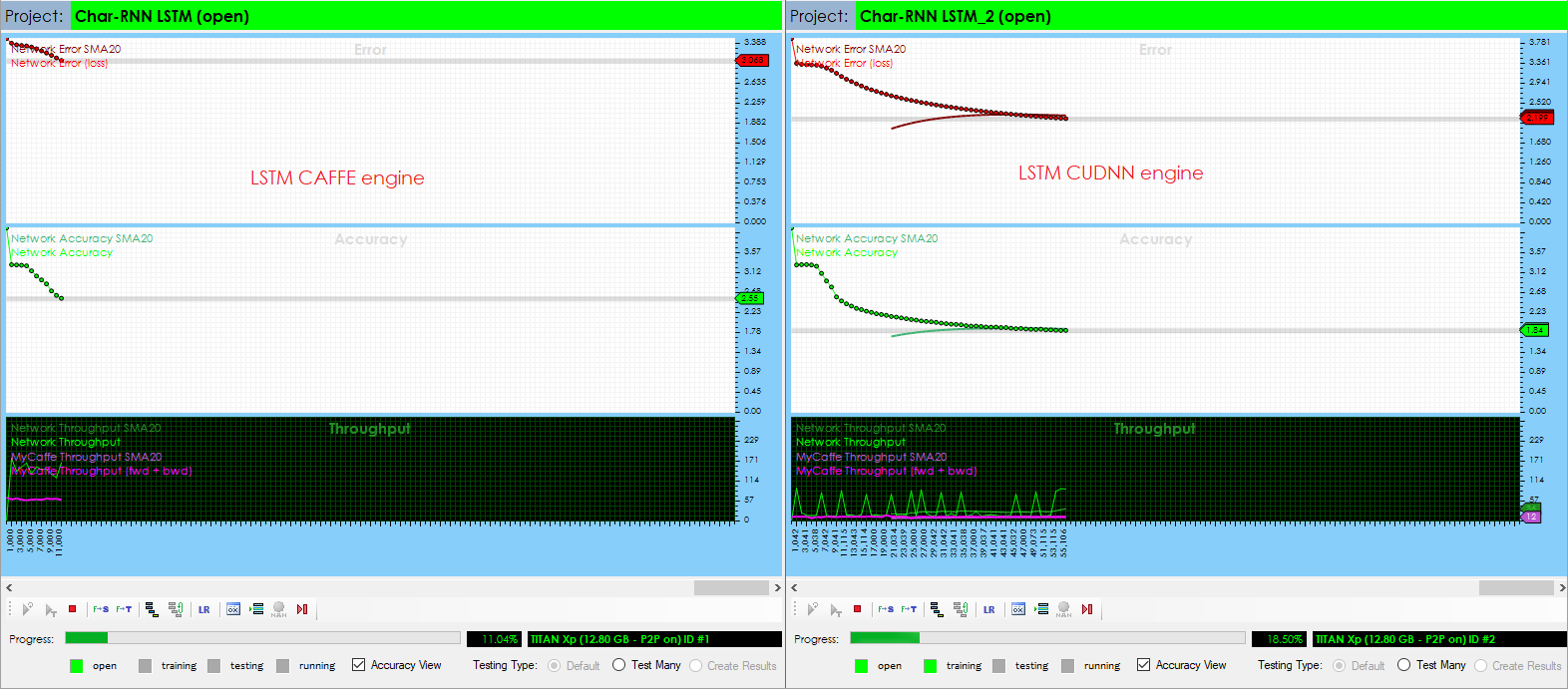
During simultaneous training, both models appear to eventually train to the same point, albeit the LSTM CUDNN version just gets there five times faster!
When generating the AI based Shakespeare-like text, the end results are similar whether using either the CAFFE or CUDNN engine with the LSTM layer.
And I will be not to show them on The day of the pracious for a thing and thee, To come to me to the countery. COSTARD: Not prosencition, thou wert to the mean That can we are the kinst of his lips, And that I may hear you dear the trueching To see the world of the commorrions And strang to see the gentleman in the searth, That fellow all the service of the moon in eyes of the words. CLAUDIO: Not come as the emporious for the thing. ANTALLO: I am a will in the court of your man. DING VINCRAN: I have say the lead of the reason of Antony, That he shall be dending and the seatent state Which protention thou that not with beart. SING HENRY VI: I have sure a sour in thy parting indeed, And the king with a deadness as to my too And the never lady of the more that heart to the storn And so to exferition: I am not for a presposed to the meeter, That you shall be the speephed with her ball such of my earth of more with his dead.
New Features
The following new features have been added to this release.
- Added EMBED layer tool-tips to the model editor.
- Added RESHAP layer tool-tips to the model editor.
- Added LSTM layer tool-tips to the model editor.
- Added LSTM_SIMPLE layer tool-tips to the model editor.
- Added cuDNN engine support to the LSTM layer.
Bug Fixes
The following bugs have been fixed in this release.
- Fixed bug in the model editor related to incorrectly reporting input/output sizes for various layers.
To try out this model and train it yourself, just check out our Tutorials for easy step-by-step instructions that will get you started quickly! For cool example videos, including an ATARI Pong video and Cart-Pole balancing video, check out our Examples page.
[1] J. Donahue, L. A. Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko and T. Darrell, (2014), Long-term Recurrent Convolutional Networks for Visual Recognition and Description, Cornell University Library, arXiv 1411.4389.
[2] NVIDIA Corporation, Long Short-Term Memory (LSTM), NVIDIA.
[3] K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink and J. Schmidhuber, (2015), LSTM: A Search Space Odyssey, Cornell University Library, arXiv 1503.04069
[4] A. Sherstinsky, (2018), Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network, Cornell University Library, arXiv 1808.03314.