

How Can We Help?
Training and Testing Models
MyCaffeControl
The MyCaffeControl is the main component used when working with MyCaffe to train and test a model or otherwise run a trained model on your data.
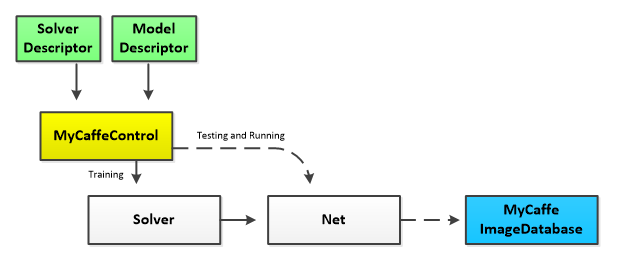
When using the MyCaffeControl, this component constructs the solver, training net, testing net and running net – all of which share the same weights. The internal Solver is created from a text-based solver descriptor and the internal Nets (train, test and run) are created from a text-based model descriptor where the run net is inferred from the train/test model descriptor.
Optionally, the MyCaffeControl can be configured to use the MyCaffe In-Memory Image Database which can greatly speed up training times after caching all data into the computer’s memory.
MyCaffe Projects
The MyCaffeControl optionally uses the ProjectEx object to help organize and group the dataset, model descriptor, solver descriptor and model results into a single location.
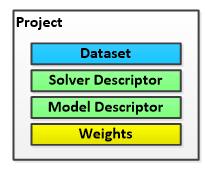
Each Dataset contains both the training Data Source and the testing Data Source, which are separate collections of data used for training and testing respectively. The Project Dataset contains the identification information necessary to load the data from each Data Source when needed.
The Solver Descriptor is parsed into the SolverParameter used to create the internal Solver used for training.
The Model Descriptor is parsed into the NetParameters used to create the internal training, testing and run Nets.
The following sections discuss how to train, test and run models using the MyCaffeControl.
Coding Examples
The following example demonstrates how to create and load a project into the MyCaffeControl, and then train and test the project.

In the sample above, first the preparatory steps 1-5 help prepare the MyCaffeControl for training.
1.) The SettingsCaffe object contains settings that tell the MyCaffeControl how to initialize itself, including settings that impact how data is loaded and queried. In the sample above, the image loading method is set to LOAD_ALL which directs the internal MyCaffeImageDatabase (used by the MyCaffeControl) to load all images before training.
2.) Next, the solver and model descriptors are loaded from file – for this sample the LeNet Solver and LeNet Model are used.
3.) The DatasetFactory loads the DatasetDescriptor for the MNIST dataset (Note, the MNIST dataset has already been loaded into the SQL database using the MnistDataLoader – the MyCaffe Test Application also provides the ability to load the MNIST dataset into SQL).
4.) Now that we have the DatasetDescriptor and the solver and model text descriptors, we are ready to create the ProjectEx.
5.) And finally, an instance of the MyCaffeControl is created.
We are now ready to create the internal Solver and Nets, load the data and create the connection to the low-level CudaDnnDll via the CudaDnn object.
6.) Calling the Load method directs the MyCaffeControl to load the project and its data in preparation for training, testing and running.
Once a project is loaded, we are ready to train and test the project.
7.) Calling the Train method directs the MyCaffeControl to start training the model on the training data set for the specified number of iterations.
8.) Calling the Test method directs the MyCaffeControl to start testing the model on the testing data set for the specified number of iterations.
Once your model is trained up to a satisfactory level of accuracy, you are ready to use the model in your application. To run the model the MyCaffeControl provides methods to run a new data item through the model, such as the Run (on a SimpleDatum) or Run (on an image) methods.
Each run method returns a ResultCollection used to determine the resulting class based on its probability or distance depending on the type of model used.
To download sample code demonstrating how to use the MyCaffeControl see the Image Classification Sample on GitHub.