

How Can We Help?
Training and Testing w/o Image Database
MyCaffeControl (Lite)
Whether using the MyCaffe Image Database or not, the MyCaffeControl is the main component used when working with MyCaffe to train and test a model or otherwise run a trained model on your data.
When using the MyCaffeControl without the MyCaffe Image Database, the component constructs the solver, training net, testing net and running net – all of which share the same weights. The internal Solver is created from a text-based solver descriptor and the internal Nets (train, test and run) are created from a text-based model descriptor where the run net is inferred from the train/test model descriptor.
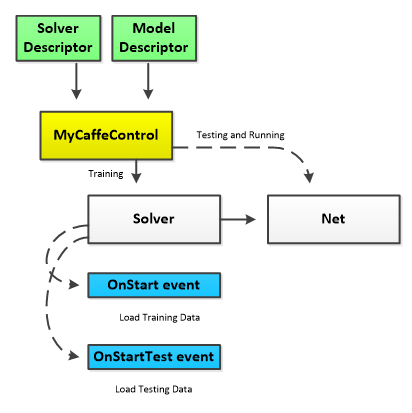
Before training, testing or running a model, the MyCaffeControl must be configured so that is can load the data to run the model against. Normally, the data is loaded by the MyCaffe In-Memory Image Database, but when using the MyCaffeControl without it, the data can be loaded directly via the OnStart and OnTestStart events provided by the Solver. Each of these events fire at the start of each training and testing cycle respectively, thus allow you to load your data just before it is needed for the current iteration.
Instead of using a project, the MyCaffeControl allows for loading the solver and model descriptors directly via its LoadLite function. Once loaded, calling the GetInternalSolver method returns the Solver created by the MyCaffeControl from the solver descriptor.
With the Solver in hand, you can easily connect to its OnStart and OnTestStart events.
Bare Bones MyCaffe
When using MyCaffe without the Image Database, you are responsible for directly loading the data, but are also able to run in a very light weight manner that only requires three modules (when using standard MyCaffe features):

These three modules offer nearly all of the layers supported by the original CAFFE[1][2].
Coding Examples
The following example demonstrates how to create and load a solver and model descriptor into the MyCaffeControl, and then train and test the project using the light-weight mode that does not use the MyCaffe In-Memory Image Database.

In the sample above, first the preparatory steps 1-3 help prepare the MyCaffeControl for training.
1.) A default SettingsCaffe object is created that contains initialization settings used by the MyCaffeControl, including the GPU ID to use.
2.) Next, the solver and model descriptors are loaded from file – for this sample the LeNet Solver and LeNet Model are used.
3.) And finally, an instance of the MyCaffeControl is created.
We are now ready for the MyCaffeControl to create the internal Solver and Nets, which use low-level CudaDnnDll via the CudaDnn object.
4.) Calling the LoadLite method directs the MyCaffeControl to load the solver and model descriptors in preparation for training, testing and running.
5.) Next, the GetInternalSolver is called to retrieve the Solver constructed in step #4 above. The OnStart and OnTestStart events are connected thus allowing us to load data at the very start of each training and testing iteration.
Once a project is loaded and the Solver is configured, we are ready to train and test the project.
6.) Calling the Train method directs the MyCaffeControl to start training the model on the training data set for the specified number of iterations.
6a.) Internally, the Solver fires its OnStart event at the start of each training iteration which allows for loading the data for that iteration. The data is loaded into the ‘data’ and ‘label’ Blobs of the Training Net (as defined by the LetNet model descriptor for the TRAIN phase). For more information on loading data from the CPU to the GPU, see Loading Data onto the GPU.
7.) Calling the Test method directs the MyCaffeControl to start testing the model on the testing data set for the specified number of iterations.
7a.) Internally, the Solver fires its OnTestStart event at the start of each testing iteration which allows for loading the data for that iteration. The data is loaded into the ‘data’ and ‘label’ Blobs of the Testing Net (as defined by the LetNet model descriptor for the TEST phase). For more information on loading data from the CPU to the GPU, see Loading Data onto the GPU.
Once your model is trained up to a satisfactory level of accuracy, you are ready to use the model in your application. To run the model the MyCaffeControl provides methods to run a new data item through the model, such as the Run (on a SimpleDatum) or Run (on an image) methods.
Each run method returns a ResultCollection used to determine the resulting class based on its probability or distance depending on the type of model used.
To download code that demonstrates how to load data into MyCaffe without the MyCaffe Image Database, see the Bare Bones Image Classification samples on GitHub.
[1] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, Trevor Darrell, Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv, 2014.
[2] David W. Brown MyCaffe: A Complete C# Re-Write of Caffe with Reinforcement Learning. arXiv, 2018.