

GPT is a great transformer model used to solve many natural language problems, however GPT only implements the encoder side of a full encoder/decoder transformer model as described by Vaswani et al. [1].
Only a few changes are needed to implement a full encoder/decoder transformer model as shown below (GPT portion inspired by the minGPT model first presented by Karpathy [2]).
The following steps describe how to convert a minGPT model into a full encoder/decoder transformer model.
Step 1 – Create a MultiHeadedAttention Layer
The minGPT model uses a CausalSelfAttentionLayer, which is similar to a MultiHeadedAttention layer but has a different input structure.
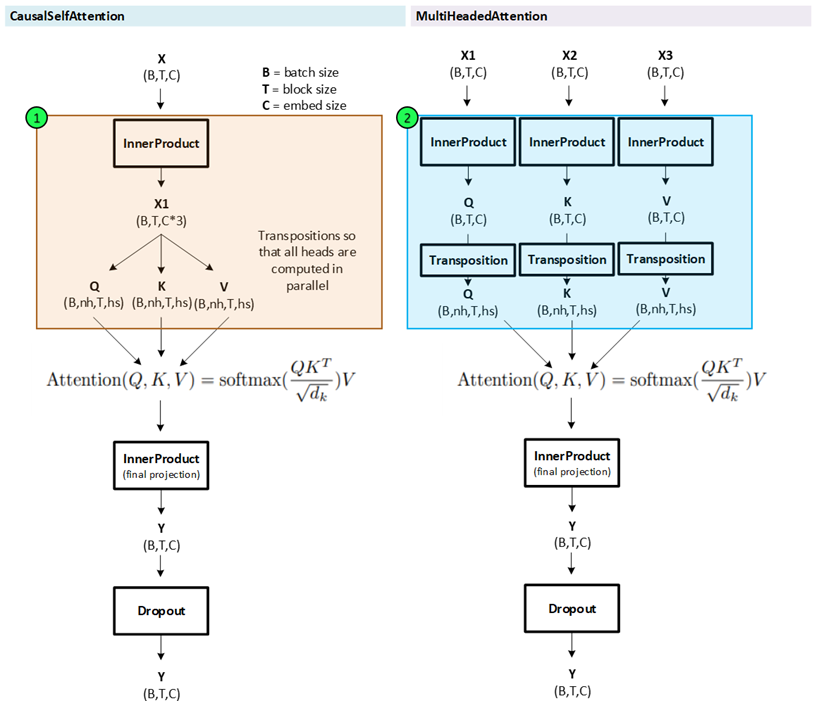
As shown above, the CausalSelfAttentionLayer takes a single input which is then tripled in size using an InnerProductLayer and then split into the Q, K and V variables that feed into the Attention formula.
The MultiHeadedAttentionLayer takes three separate parameters which are each converted into the Q, K and V variables using three distinct InnerProductLayers. This will be important later when linking the encoder to the decoder.
Step 2 – Create the Decoder Transformer Block
The TransformerBlockLayer of the minGPT model is essentially an EncoderTransformerBlockLayer.
To create the DecoderTransformerBlockLayer, a few alterations are needed to convert the EncoderTransformerBlockLayer so that it can link the encoder to the decoder.
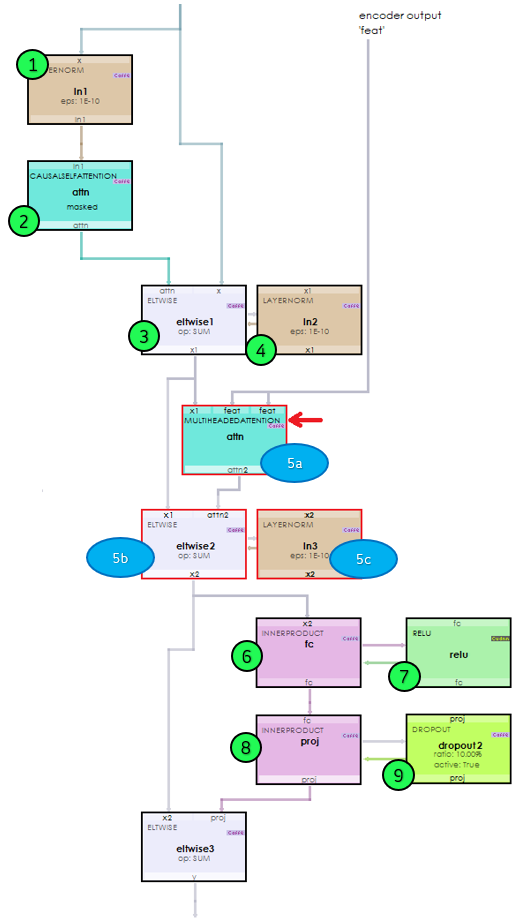
In the new DecoderTransformerBlockLayer, a MultiHeadedAttentionLayer (5a) is added to link the CausalSelfAttentionLayer output to the ‘feat’ output of the last EncoderTransformerBlockLayer via the Attention function shown below.
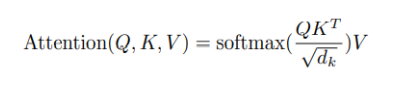
Q = X1 (layer normalized Causal Attention + X)
K = ‘feat’ output from last Encoder Transformer Block
V = ‘feat’ output from last Encoder Transformer Block
After calculating the attention, the result is added to the previous Add Norm ‘x1’ value and then fed into the MLP, just like the EncoderTransformerBlockLayer.
Step 3 – Build the full Model
With a DecoderTransfomerBlockLayer you are ready to build the full encoder/decoder model as shown above where all TransformerBlockLayers in the ‘Encoder’ section are TransformerBlockLayers similar to those used in the minGPT model, and the TransformerBlockLayers in the ‘Decoder’ section are TransformerBlockLayers with the new MutliHeadedAttention and Add Norm functionality added.
To learn more about converting the minGPT model into a full encoder/decoder transformer model, see the full presentation, “minGPT -vs- Encoder/Decoder“.
Note, the DecoderTransformerBlockLayer and MultiHeadedAttention layer are not yet released, but stay tuned for they may be in the next MyCaffe release.
[1] Attention Is All You Need by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, 2017, arXiv
[2] GitHub: karpathy/minGPT by Andrej Karpathy, 2022, GitHub