

When training any deep learning AI model, knowing your data is critical. This is especially important when training a transformer-based encoder/decoder model for data ordering is important.
In this post, we analyze the Python open-source language translation encoder/decoder transformer model by Jaewoo (Kyle) Song [1] which is based on the ‘Attention Is All You Need‘ article by Vaswani et. al. [2].
Training
As with most encoder/decoder training datasets, the first step is to preprocess the data into two sets (e.g., two text files) with matching lines of text. In our English to French translation example the source data file contains lines of English text, and the target data file contains matching French translations of each of those lines of English text. For example, the first line of text in the source data file is, “Resumption of the session” and the matching first line of text in the target data file is, “Reprise de la session.”
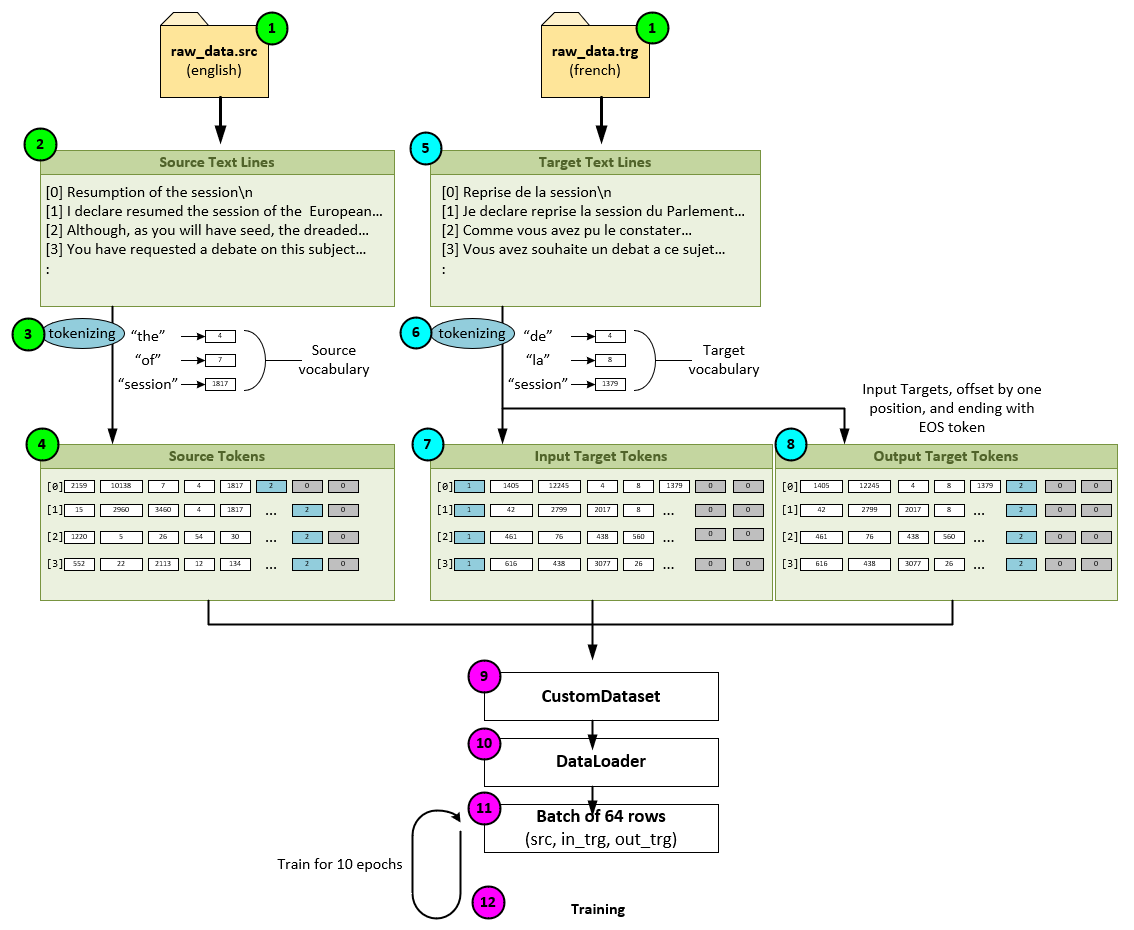
Data Flow when Training Encoder/Decoder Transformer Model for TranslationWhen training the encoder/decoder transformer model for language translation, the following data flow steps take place.
1.) First, the data set is preprocessed into the raw_data.src file containing the English text sentences, and a corresponding raw_data.trg file containing the matching French translations of the English text sentences.
2.) The lines of the English text file raw_data.src are read into an array of strings, …
3.) … and tokenized by using an English vocabulary which converts each sentence into a string of integer indexes where each index corresponds to each sentence word within the vocabulary. During the tokenizing process, the sentence “Resumption of the session\n” is converted into an integer array = [2159, 10138, 7, 4, 1817] where the indices 2159 and 10138 represent portions of the word ‘Resumption’, 7 represents ‘of’, 4 represents ‘the’, and 1817 represents the word ‘session’.
4.) Once tokenized, the source data is stored as a list of arrays of integers where each array represents a single input sentence.
5.) Next, the same process takes place with the target data – the French text. The raw_data.trg containing the French text is red line by line and stored in array of strings.
6.) The lines of the French target data are then tokenized in the same manner as the English text was tokenized in step #3 above, except this time a French vocabulary is used during the tokenization process.
7.) Once tokenized, the target data is stored in a list of arrays of integers where each array represents a single target input sentence. The number of items in the source data of step #4 above matches the number of items in the target input data. Each target input data array starts with the special BOS (beginning of sequence) token.
8.) In addition to creating the target input data of step #7, a matching target output data is also created where the target output data is the same as the target input data but with each sentence offset by one position. To shift the target input data, the special BOS token is removed, and a special EOS (end of sequence) is added to the end of the target output data integer array.
9.) The source data, target input data and target output data are all padded with ‘0’ so that all arrays within each list are the same length. These lists of integer arrays are then fed into a Python CustomDataset…
10.) …, which is used to initialize a Python DataLoader.
11.) During each training pass, the DataLoader collects batches of matching source data, target input data and target output data integer arrays and feeds them into the training process.
12.) Training continues until an acceptable loss level or accuracy is reached.
Masking Data for Encoding Phase of Training
When training, masking out data is an important part of the data flow, for masks are used to control which data flows through the training and which data does not.
During the encoding phase of the training model, the source data is masked with the encoder mask (e_mask). This mask is created by selecting all non-padded data produced at step 4 from the input data at step 2.
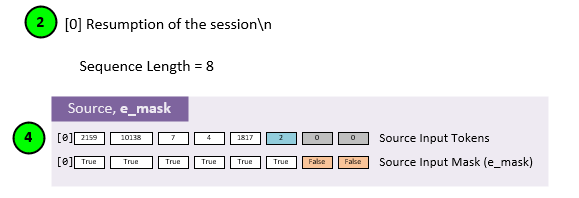
Assuming a sequence length of 8, the mask for a single source input line would look like the Source Input Mask (e_mask) above.
Masking Data for Decoding Phase of Training
The inputs to the decoding phase are also masked, but this massing process is a little more complicated for “we need to prevent leftward information flow in the decoder to preserve the auto-regressive property.” Vaswani et. al. [2].
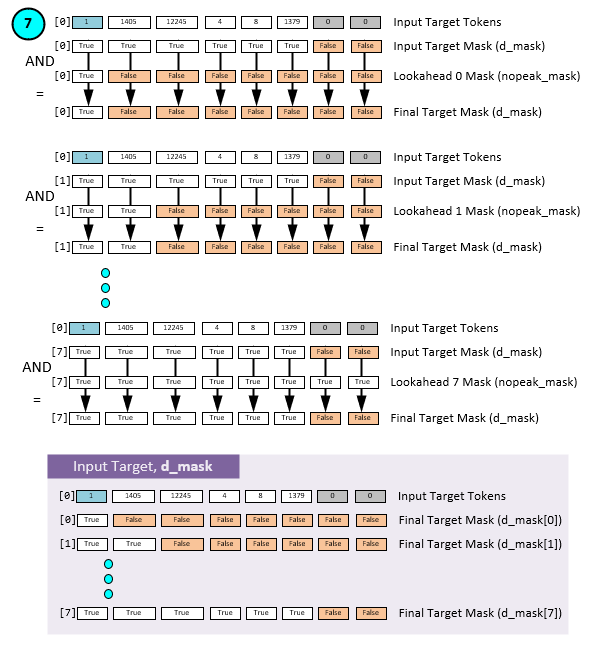
In order to prevent the leftward information flow, the Input Target Tokens are first masked similar to the Source Data, but then a triangular identity matrix is overlaid thus preventing the leftward information flow. Assuming a sequence length of 8, the final Target Input Data Mask (d_mask) is shown at the bottom of the figure above.
How is Masking Used During Training?
During the encoding phase of training, the e_mask is passed through the EncoderLayer and on to the MultiheadAttention layer which self attends to the Source Data.
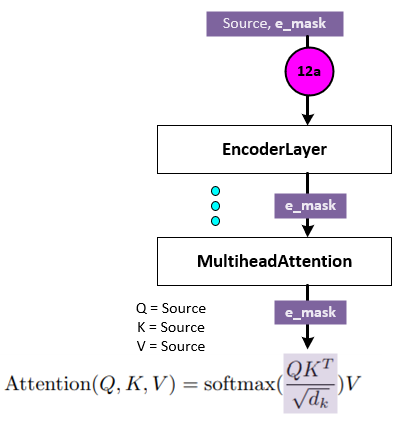
When self-attending to the Source Data (after normalization, and dropout, etc.) the Source Data is represented as the Q, K and V values fed into the attention function from Vaswani et. al. [2]. When using masking, the e_mask is applied to the final QK^T/Sqrt(dk) value just before the Softmax, thus forcing the Softmax to focus only on the areas where the e_mask = True (e.g., where we have non-padded tokens in the Source Data from step 4 above). All e_mask = False items are set to -infinity which forces Softmax to zero out these items.
During the decoding phase of training, the d_mask is used along with the e_mask. The decoding phase uses two different MultiheadAttention layers to first self-attend the Input Target Data and then to attend the output of the first multi-head attention with the encoder output from the last encoder layer.
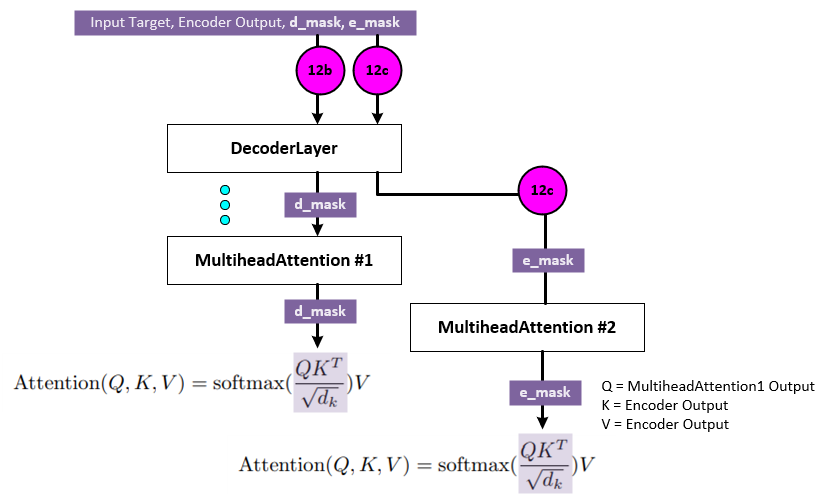
The first MultiHeadAttention self-attends the Input Target Data and uses the d_mask for data selection and prevent the leftward information flow. This masks out the data in a similar way as occurred during the encoder phase discussed above.
The second MultiHeadAttention attends the first multi-head output with the last encoder layer output and uses the e_mask for data selection.
Inference
Once trained, the model is ready for use to translate any sentence from English to French.
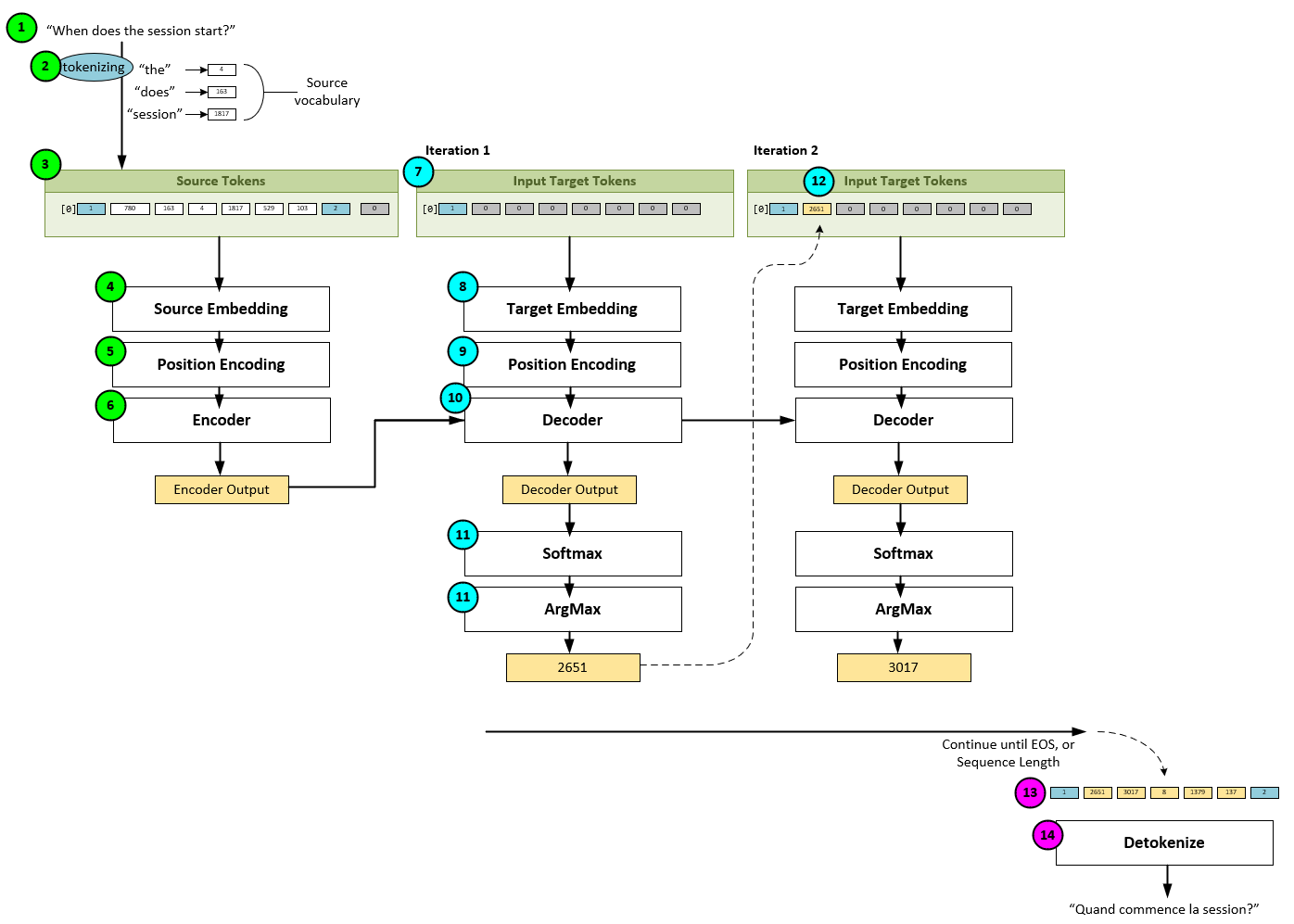
When using the transformer model to translate a sentence of English to French, the following steps occur.
1.) First, the English sentence, such as “When does the session start?” is entered.
2.) The sentence is then tokenized into the source tokens using the English vocabulary. For example, the sentence “When does the session start?” is tokenized into the integer array [1, 780, 163, 4, 1817, 529, 103, 2], where 1 represents the special BOS token and 2 represents the special EOS token.
3.) The input tokens are then padded with ‘0’ to match the sequence length used during training.
4.) Next, the padded input tokens are fed into the Source Embedding and, …
5.) …Position Encoding is added to the Source Embedding.
6.) The position encoded source embedding is then fed into the Encoder to produce the Encoder Output.
7.) During the first iteration on the decoder side, a padded input starting with the BOS token is created to form the initial Input Target Tokens.
8.) The input target tokens are then fed into the Target Embedding and, …
9.) … Position Encoding is added to the Target Embedding.
10.) The position encoded target embedding is then fed into the Decoder along with the Encoder Output produced in step #6 above to produce the Decoder Output.
11.) The decoder output then feeds into a Softmax and Argmax for a greedy selection of the predicted output token, which in this example is 2651.
12.) The predicted output token is then added to the first padded slot within the previous input target tokens. At this point the input target token array = [1, 2651, 0, 0, 0…]. The process repeats back at step #7 above until either an EOS token is predicted, or the sequence length is reached.
13.) Once an EOS token is predicted or the sequence length is reached, the final input target tokens are…
14.) … detokenized using the French vocabulary. In our example, the final input target tokens = [1, 2651, 3017, 8, 1379, 137, 2] are detokenized into the French sentence, “Quand commence la session?”.
Masking Data for Encoder Phase of Inference
Masking data during the encoder phase of inference occurs in the same way as with the encoder phase of training.
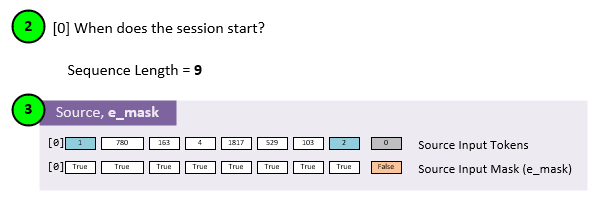
The main difference between the inference and training phases is that inference may only process a single line instead of a batch of lines.
Masking Data for Decoder Phase of Inference
When masking data for the decoder phase, the same masking process occurs like that of training, except a new mask is created on each iteration that produces a new Output Target – for the Input Target Data is different on each iteration.
On the first iteration of the decoder process, the Input Target Data = [1, 0, 0, 0, … sequence_length] which is masked as follows.
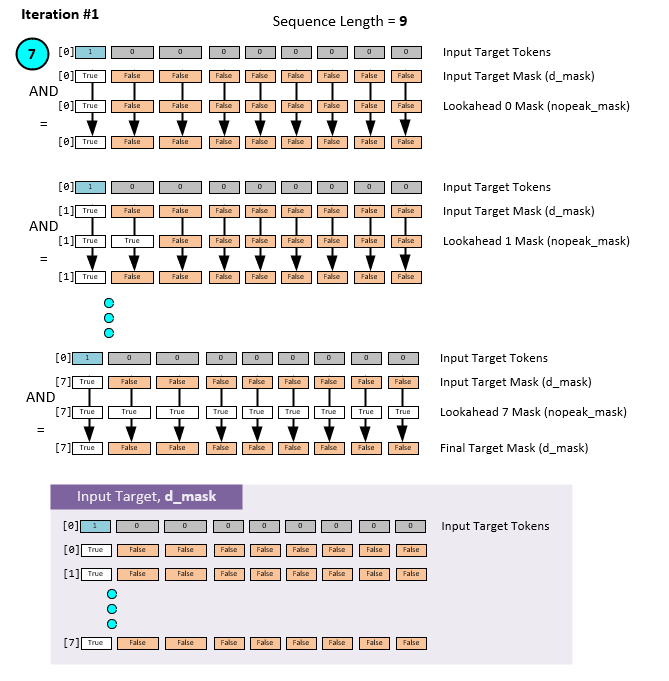
Note above that the only non-padded data is the special BOS token (e.g., BOS = 1). For that reason, only that data slot is used in the final mask for iteration 1.
On the second iteration, the predicted output from the decoder phase is added to the Input Target Data and run through the process again with the new and different mask shown below.
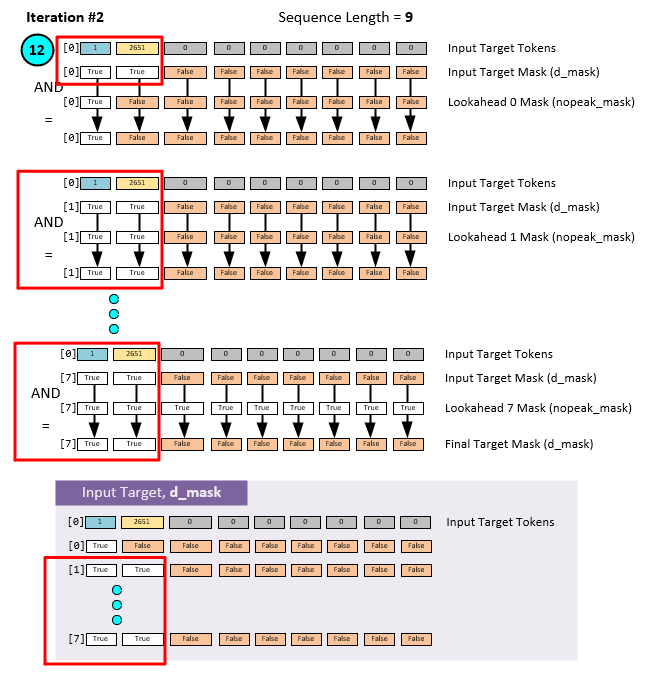
This mask renewing occurs on each iteration of the decoding phase of inference until the special EOS token is predicted or the sequence length is reached.
Summary
Now that you know how the data flows when training or inferencing with an encoder/decoder transformer model for language translation, go forth and translate!
[1] GitHub: devjwsong/transformer-translator-pytorch by Jaewoo (Kyle) Song, 2021, GitHub
[2] Attention Is All You Need by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, 2017, arXiv