

With GPT and ChatGPT, transformer models have been proven to be very powerful AI models. However, how do they work on the inside? With this post, we use the SignalPop AI Designer to visually walk through the forward pass of a transformer model used for language translation.
Before showing a visual walk-through we wanted to revisit where it all started – with the article ‘Attention is all you need‘ by Vaswani et al., published in 2017.
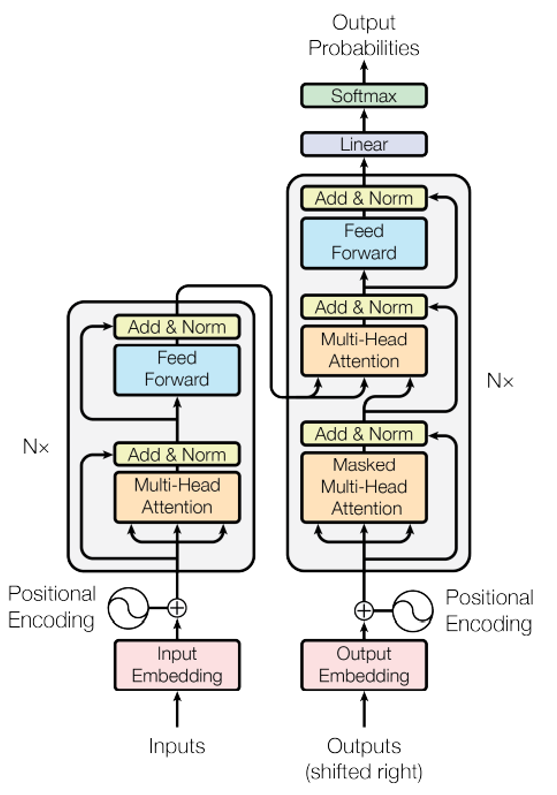
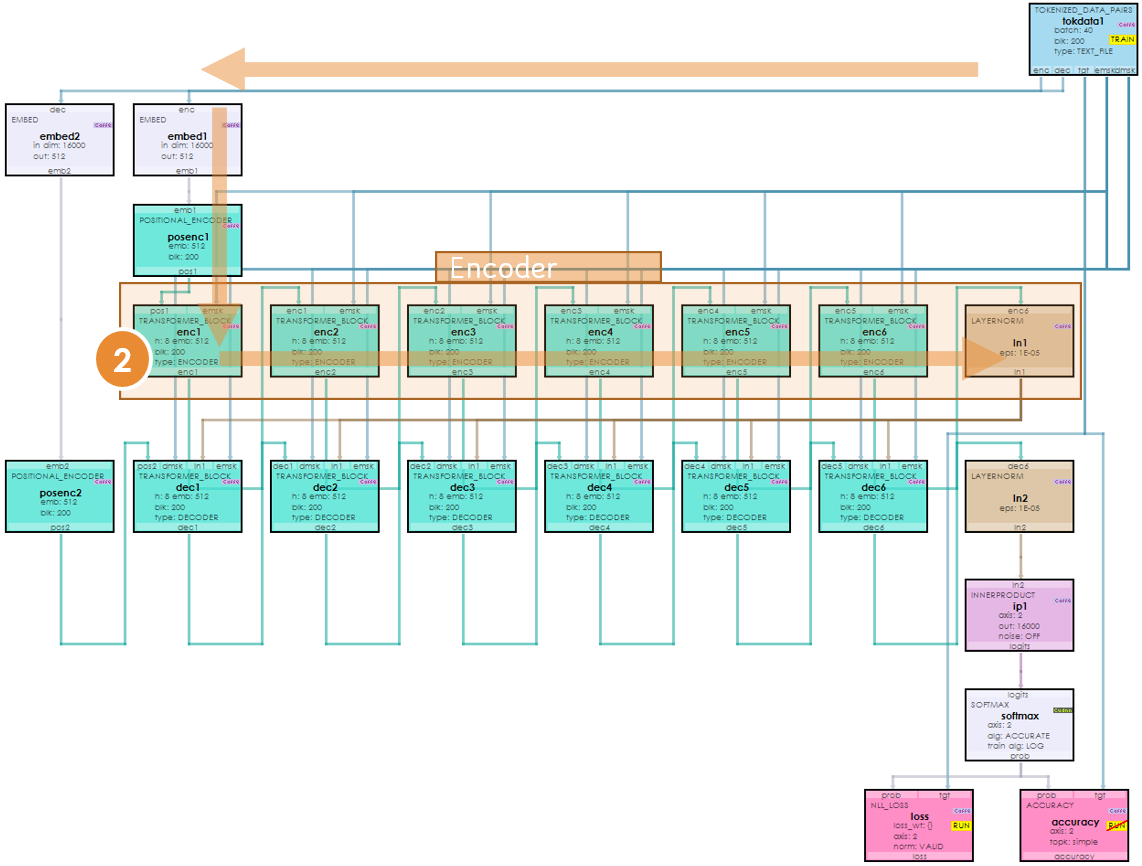
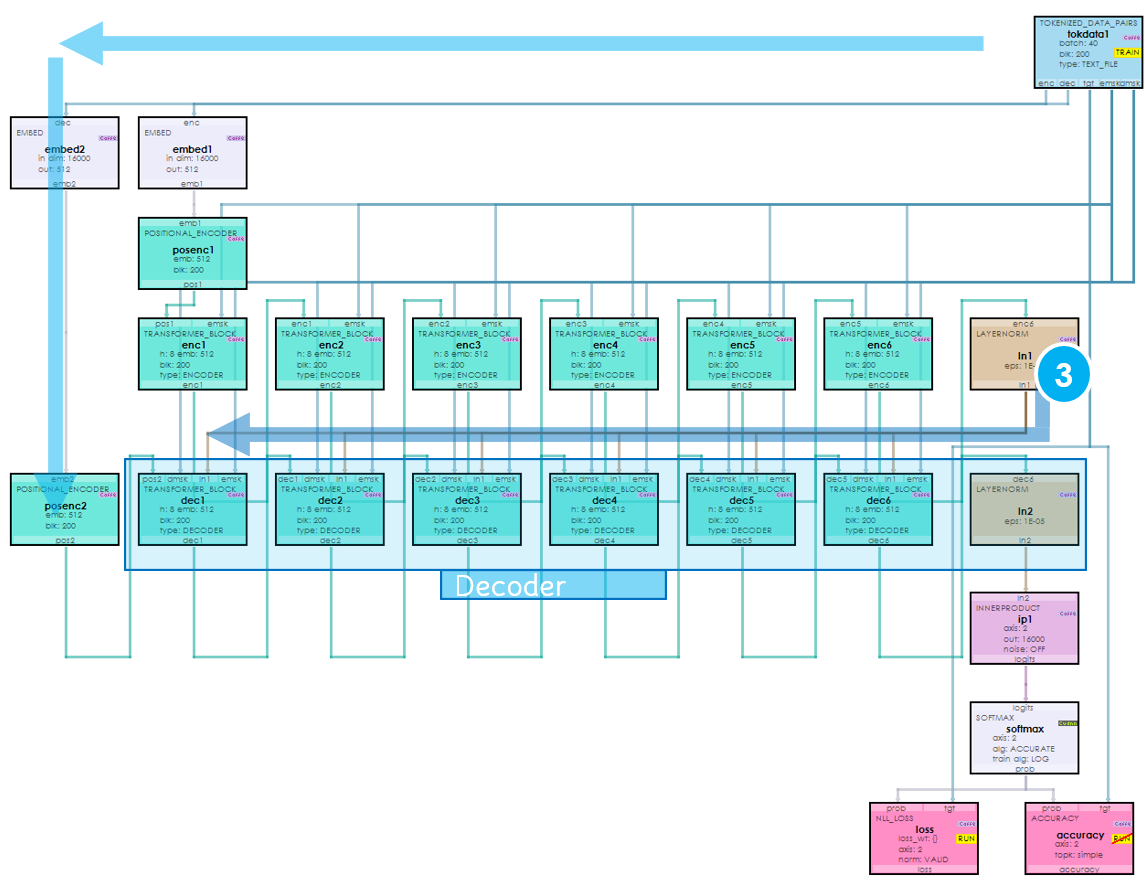
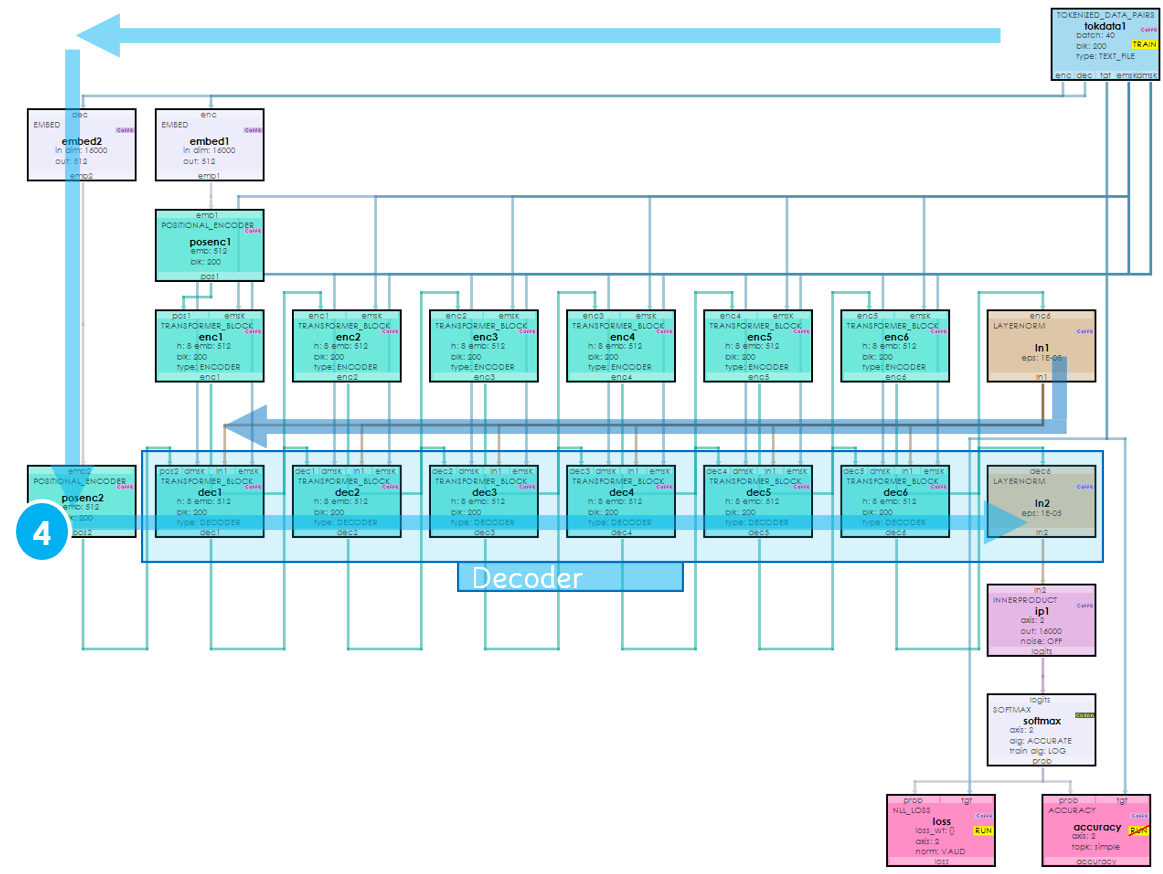
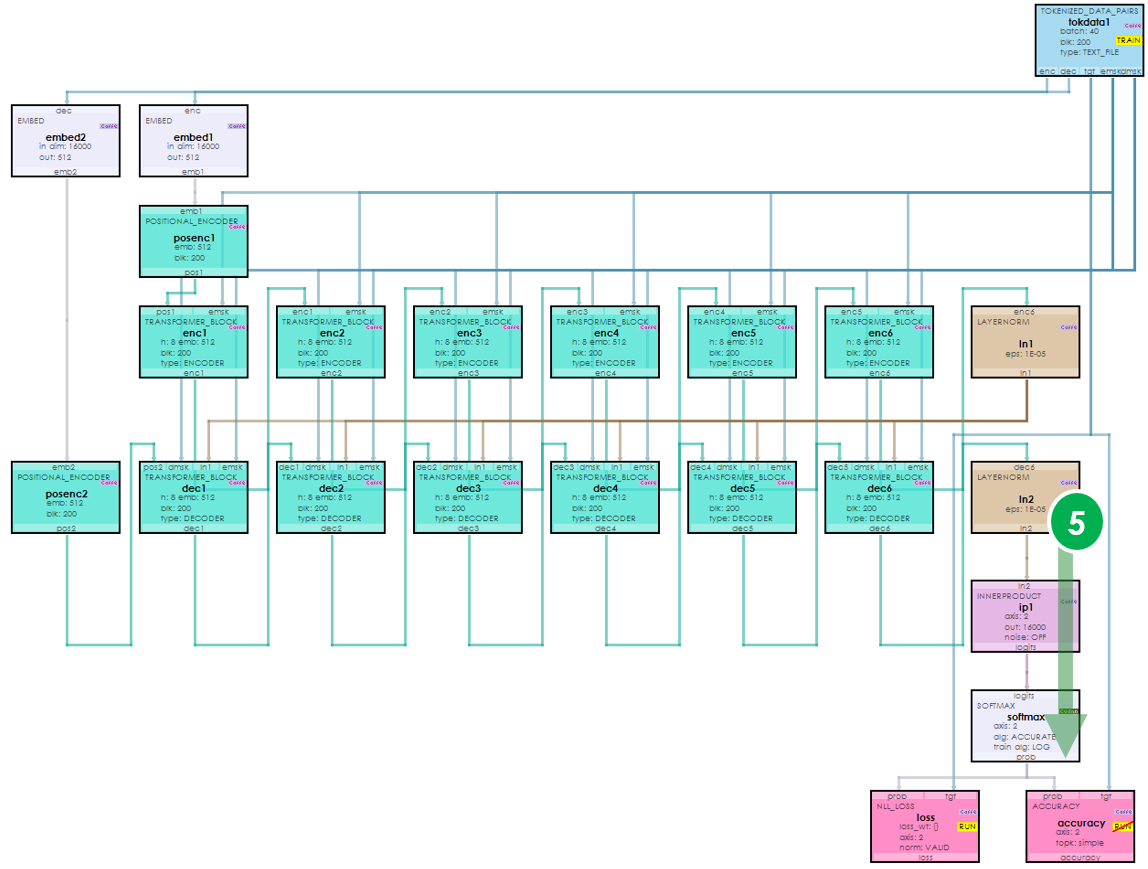
The central idea of a transformer is to map a learned ‘encoding’ to a learned ‘decoding’ to produce decoded outputs. This occurs with an encoder and decoder that work together to produce the results. Above, the encoder is shown on the left, whose outputs are mapped to the decoder inputs via the decoder on the right to produce the output probabilities.
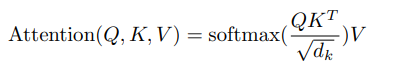
To make this mapping, self-attention is used to learn the probability distribution of the encoding, and also for learning the probability distribution of the decoding. Multi-head attention is then used to learn the mapping of the encoding probability distribution to the decoding probability distribution. Both self-attention and multi-head attention use the Attention Function above but with different Q, K and V values as shown below.
A Language Transformer Model
Below is a full transformer model used to perform language translation.
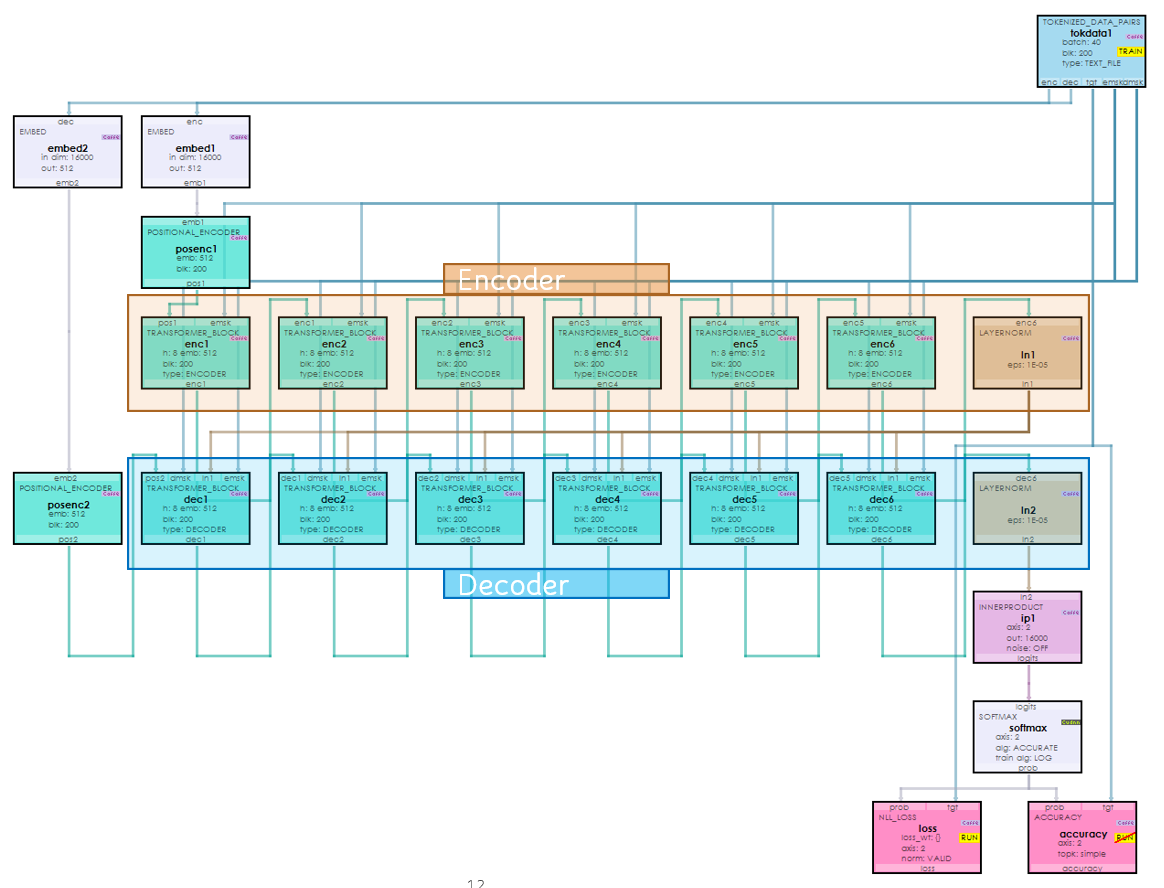
During our visual walk-through we discuss how data flows through this model when translating from one language to another such as from English to French.
Step 1A – Tokenizing the Encoder Input
In the first step, the input sentence such as, “When does the first European Union session start?” is tokenized into a set of numbers using a sentence-piece tokenizer.
Essentially, this tokenization process converts the input text sentence into a sequence of numbers representing each word or sub word of the sentence.

A visualization of the tokenized encoder inputs shows a sequence of pixels where each pixel represents a token, and its color shows the number range of the token itself. Notice that there are more blue pixels than other colors – these represent common words used in the input sentences. The above image contains a batch of tokenized inputs sentences.
Step 1B – Embedding the Encoder Input Tokens
In the next step, the encoder input tokens are converted to embeddings where a vector of numbers represents each token in the embedding space.

As you can see each of our token pixels have been expanded into many more numbers where a vector of numbers represents each token in the embedding. After creating the embedding, a position encoding is overlayed to introduce sequence information into the embedding data.
During our visualization of the position encoding data, we notice that the first element in the batch was a different color than the others.
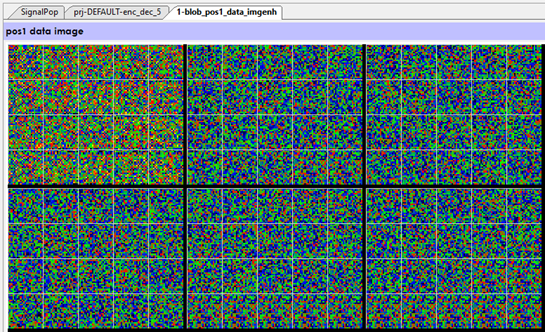
This turned out to be a difficult to find bug where the position encodings were not correctly applied to the other batch items. After fixing this bug our model accuracy increased by 10%.
Step 2 – Moving Through the Encoder Transformer Blocks
The encoder embedding + position embedding is then sent through the sequence of encoder transformer blocks. Our small language translation model only uses 6 layers, however larger models such as GPT-2 use 24 or more layers.
Step 2A – Encoder Input Data Masking
While in each encoder transformer block, the padded data (e.g., values = 0) are masked out so that we only focus on the actual encoder data.
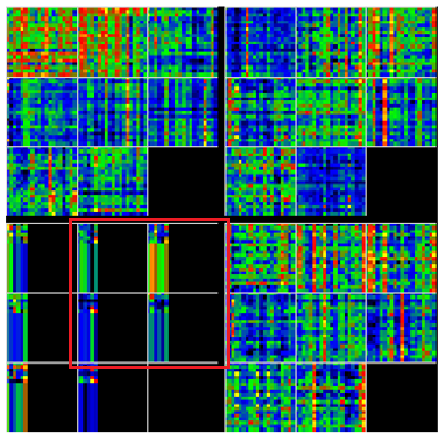
In the image above notice how the coloration stops at about 1/4 the width of the four smaller data boxes within the red rectangle – the right black areas have been masked out so that the model ignores them.
Step 2B – Encoder Self Attention
Next, the masked data is run through the Attention Function noted above.
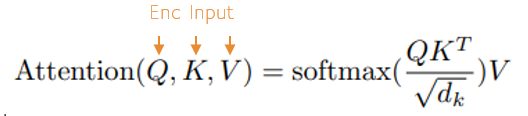
To perform self-attention, the Encoder Input data is fed into each of the Q, K and V values.
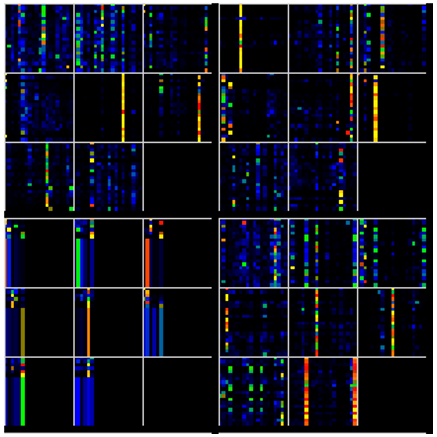
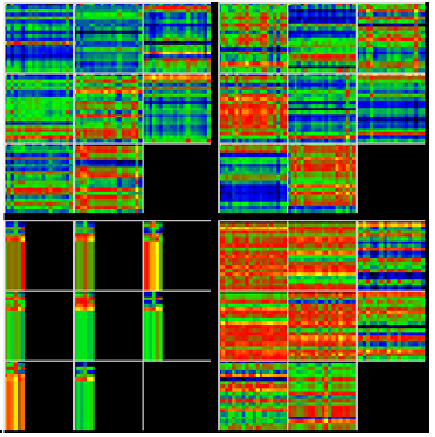
As shown in the image above, the self-attention process focuses the model on the important parts of the data.
Step 2C – Encoder Output Projection
The output of the self-attention is then fed into the encoder output projection which expands the data dimension and adds learning.
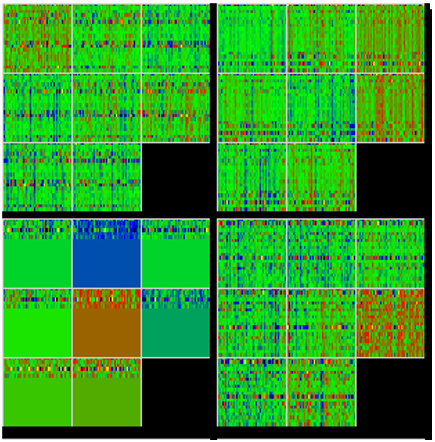
This same process repeats through each of the encoder transformer block layers, along with numerous Layer Normalizations.
Step 3 – The Last Encoder Output
The last encoder output is special in that it is used as an input to each of the decoder transformer blocks.
Each output of the transformer blocks (and numerous internal data) is Layer Normalized. Without layer normalization, the model would most likely blow-up with very large, ever-increasing outputs.

Layer normalization is similar to batch normalization except for one important difference – the area of data normalized is along the CxHxW dimension which happens to be the same dimension that each sentence input resides.
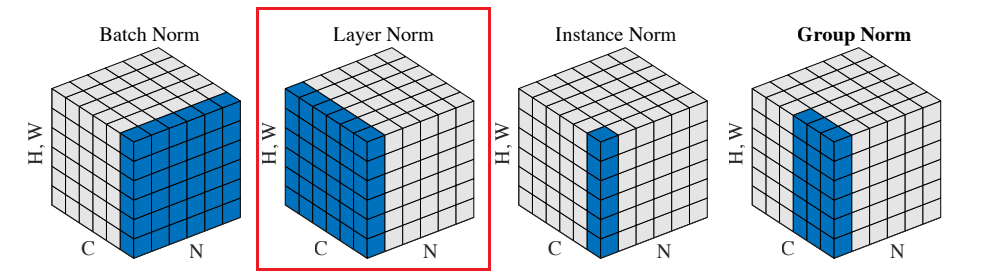
Normalizing within each sentence makes more sense than across sentences (e.g., batch normalization) for sentences may be very different in length and context.
Step 3A – Decoder Input Tokenization
In addition to the last encoder output, we must also tokenize the decoder input data.

The decoder tokenization process is very similar to the encoder tokenization process except the decoder input vocabulary is used during tokenization.
Step 3B – Decoder Input Embedding
Like the encoder embedding, the decoder embedding expands each decoder input token into a vector of numbers which then have a positional embedding added to introduce the sequence location data.
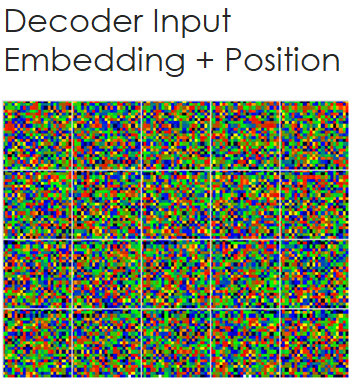
Step 4 – Moving Through The Decoder Transformer Blocks
The decoder transformer blocks are similar to the encoder transformer blocks in that they self-attend to the decoder input, but different in that they then multi-head attend the decoder inputs to the last encoder outputs which allows the model to learn how to map the encoder probability distribution to the decoder probability distribution.
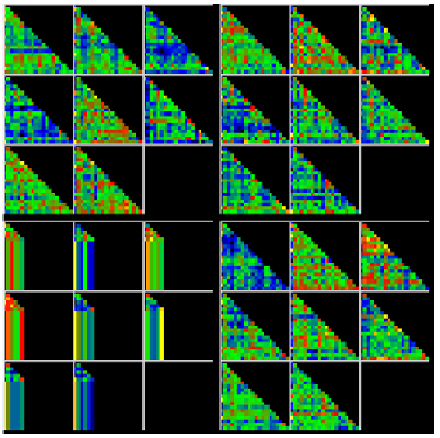
Step 4A – Decoder Input Data Masking
Like the encoder input data masking, the decoder input masking is used to mask out all data we don’t want the model to focus on. In particular, the decoder masking uses a triangle matrix to force a no-peek mask that force the model to learn from left to right, avoiding using data it will not know when inferencing.
Step 4B – Decoder Input Self Attention
Next, the masked data input is run through the Attention Function noted above to self-attend the data.
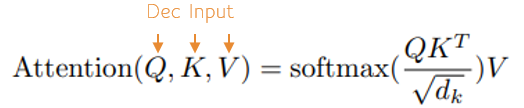
To perform the self-attention, the masked decoder inputs are run through the Attention Function as Q, K and V which produced the data below.
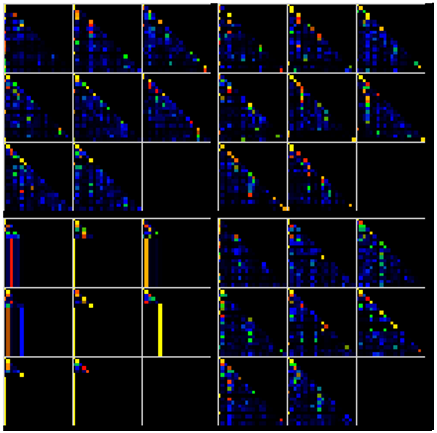
Step 4C – Decoder Input Projection
Like the encoder inputs, the self-attended decoder inputs are then run through the decoder output projection.
Step 4D – Decoder-Encoder Masking
Next, the decoder-input projection is added to the decoder input and re-masked, but this time with the encoder mask.
Step 4F – Decoder-Encoder Multi-head Attention
The mutli-head attention is used to learn the mapping between the encoder and decoder probability distributions.
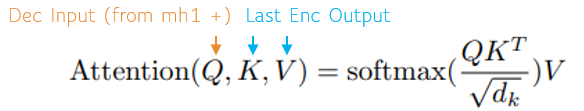
Notice that during the multi-head attention, the decoder input = Q which is then multiplied by the transpose of the last encoder output = K and then multiplied by the last encoder output = V to produce the following multi-head attention data.
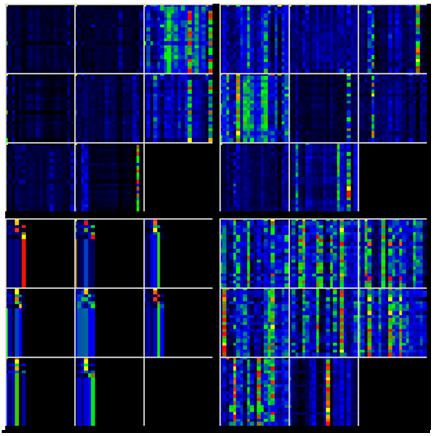
Also, notice that the multi-head attention data has found more important data than that of the previous self-attention data.
Step 4E – Decoder-Encoder Projection
Next the Decoder-Encoder Projection is produced.

The process of steps 4A-4E repeat through each of the decoder transformer blocks.
Step 5 – Producing the Results
The output of the final decoder transformer block is fed into a final projection, softmax and armax to produce the decoder output tokens.
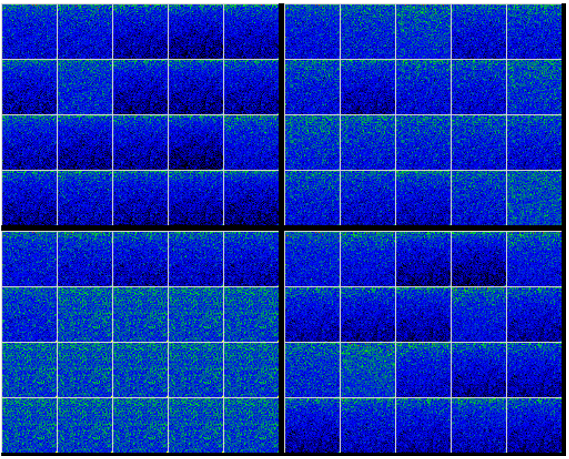
Step 5A – Producing the Logits
In our first step of producing the final results, the final decoder output is converted into logits by running the decoder output through the projection that maps the decoder outputs to vectors where each vector contains the vocabulary size of elements. For example, if the vocabulary is 16,000 in size, each vector will have 16,000 elements per item that will eventually be detokenized to a single token.
Step 5B – Converting Logits to Probabilities
The logits are converted to probabilities using a Softmax layer.
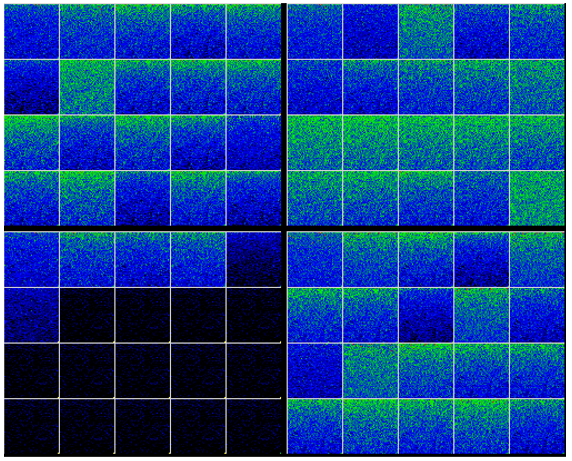
Step 5C – Converting probabilities to Tokens
Using an argmax, each vector of 16,000 probabilities is converted to a single output token corresponding to the location of the maximum item within the vector.

The decoder output tokens are then detokenized by looking up each token within the decoder vocabulary to produce the translated sentence.
Final Results
When we run the model, our input below produces an output sentence, that when verified using Google Translate, shows that we have correctly translated the English input sentence to its corresponding sentence in French.
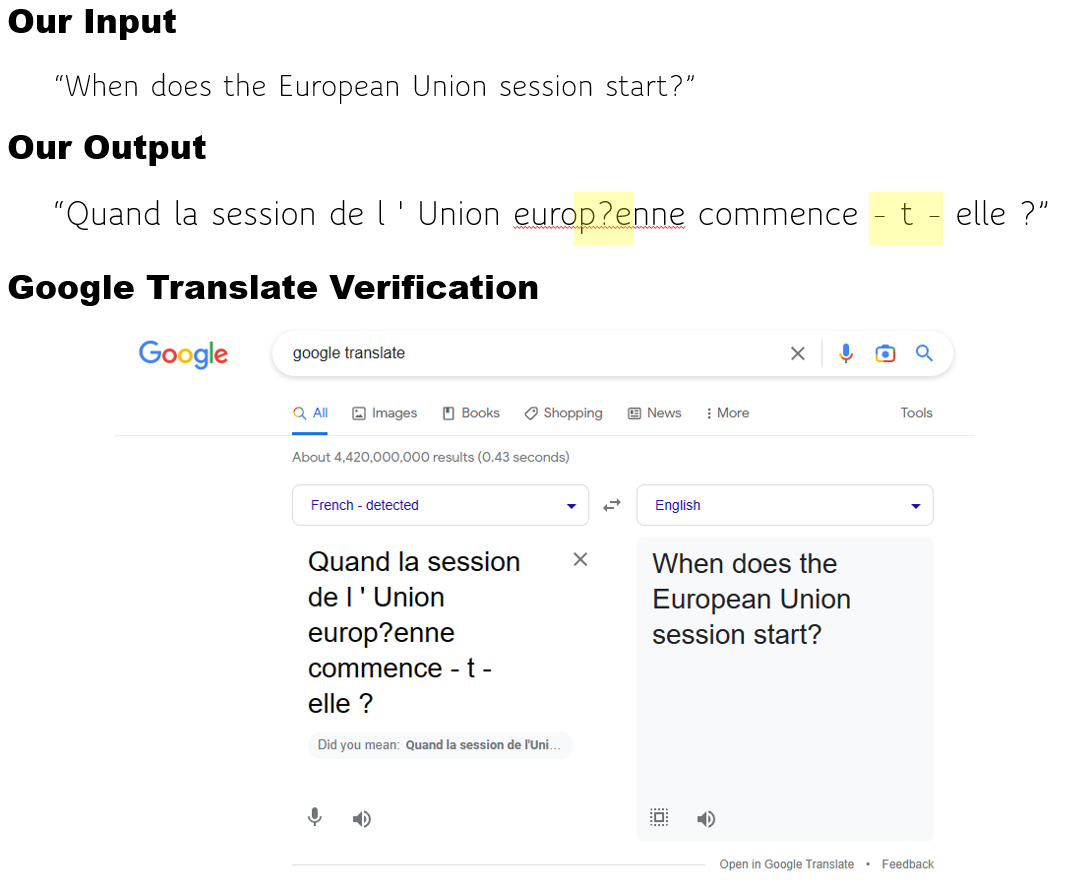
Note, the extra ‘?’ in ‘europ?enne’ may be a result of our custom sentence-piece not currently handling extended characters for the Google Translation result for the input ‘When does the European Union session start?’ produces the output:
“Quand commence la session de l’Union européenne ?”
For more information on the transformer model used to translate English to French, see the full presentation, “minGPT -vs- Encoder/Decoder Visual Walkthrough.”