

In our latest release, version 1.12.0.60, we now support ChatGPT type architectures with Encoder/Decoder Transformer Models based on the open-source transformer-translator-pytorch GitHub project by Song [1].
ChatGPT uses encoder/decoder transformer models to learn the context of the input query, the context of the likely responses and a mapping between the two via attention layers. The Translation Net also uses the encoder/decoder transformer architecture to learn the context of the input language, the context of the translation target language and a mapping between the two also with attention layers. A stack of encoder transformer blocks learns context of the input language and a matching stack of decoder transformer block learns the context of the target language plus the mapping between the input and target.
For more information on encoder/decoder transformer models see the following blog posts:
Visually Walking Through a Transformer Model
Data Flow when Training an Encoder/Decoder Model for Language Translation
Converting a GPT Model into a full Encoder/Decoder Transformer Model
TranslationNet MyCaffe Model
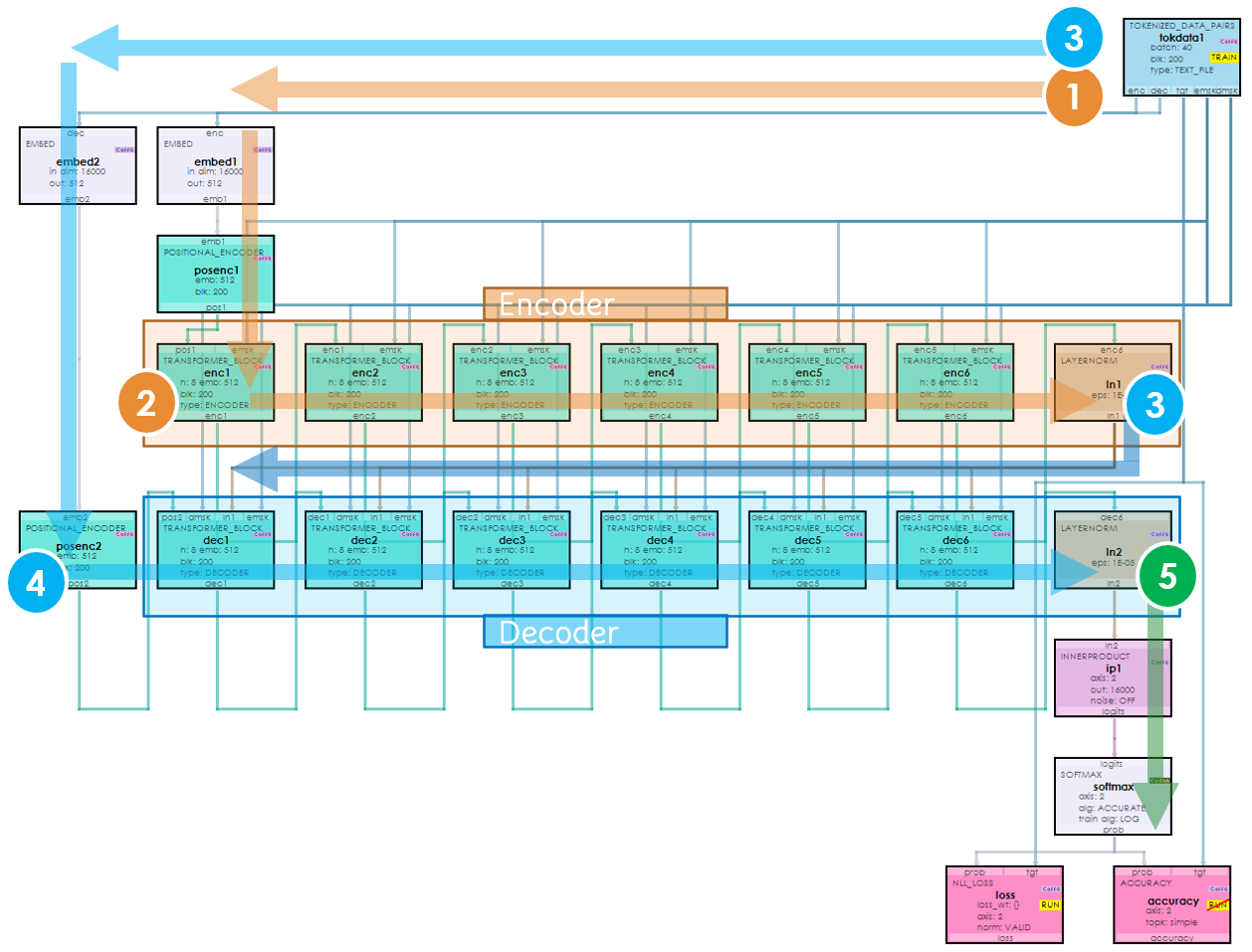
The Translator Net comprises two parallel stacks of TranformerBlockLayers where the first set are configured as the encoder transformer blocks, and the second set are configured as the decoder transformer blocks. Encoder transformer blocks learn the input language context and the decoder transformer blocks learn the target language context. In addition, the decoder transformer blocks learn to map the input context to the target context thus allowing for translation from English to French.
Encoder Transformer Block
The encoder transformer block uses the CausalSelfAttentionLayer to learn the input language context via self-attention.
When learning self-attention, the input language forms the Q, K and V inputs of the attention function [2].
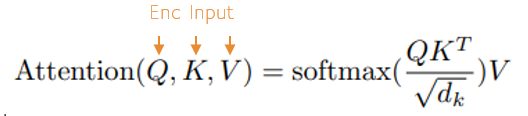
Decoder Transformer Block
Like the encoder transformer block the CausalSelfAttentionLayer is used to learn the target language context via self-attention as well.
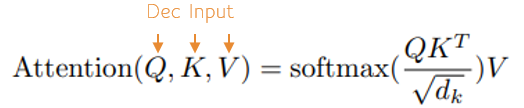
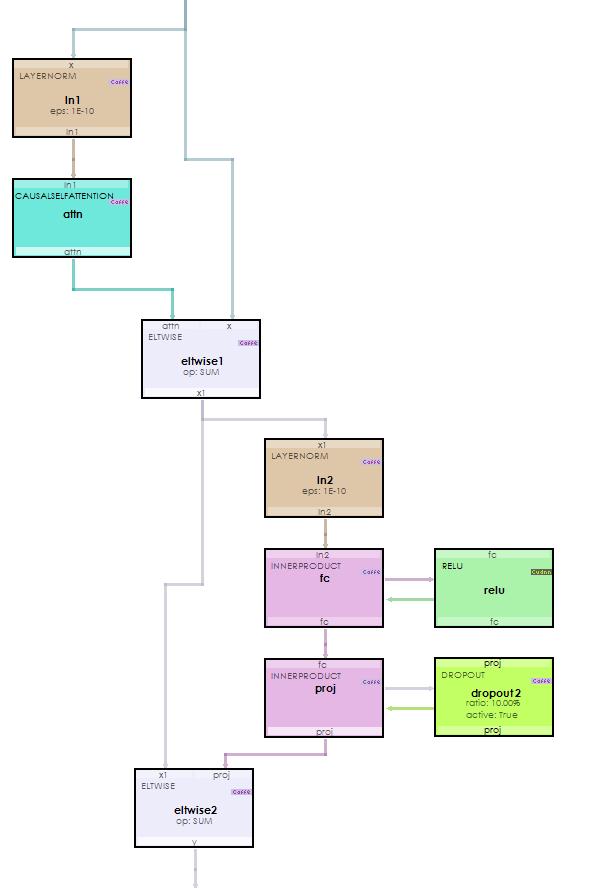
Internally, a decoder transformer block is similar to the encoder transformer block except for what takes place during steps 5a-5c shown below.
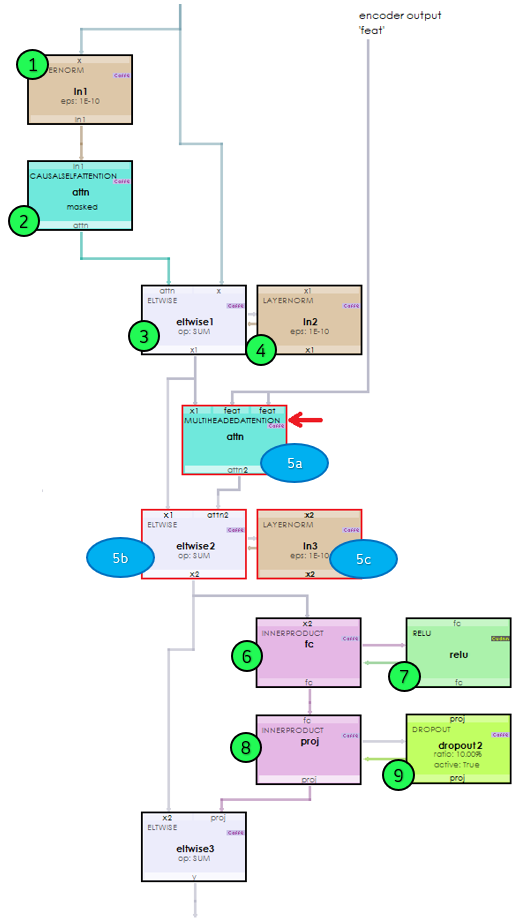
The MultiHeadedAttention in step 5a is where the mapping between the input context and target context is learned via the learned mapping between the decoder input and the last encoder output.
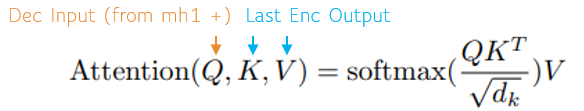
New Features
The following new features have been added to this release.
- CUDA 11.8.0.522/cuDNN 8.8.0.121/nvapi 515/driver 516.94
- Windows 11 22H2
- Windows 10 22H2, OS Build 19045.2604, SDK 10.0.19041.0
- Upgraded to NewtonJson 13.02
- Added new PositionalEncoderLayer.
- Added new ENCODER/DECODER TransformerBlockLayer.
- Added new TokenizedDataPairLayer.
- Added new Log algorithm support to SoftmaxLayer.
- Added new GPU support to ArgMaxLayer.
- Added new GPU support to AccuracyLayer.
- Added new NLLLossLayer.
Bug Fixes
The following bugs have been fixed in this release.
- Fixed bug in layer inspection for large models such as SSD.
- Fixed bugs in model visualization for large models such as SSD.
- Fixed memory issues in models.
- Fixed bugs in CausalSelfAttentionLayer related to batch training.
Create and train your own TranslationNet project to translate English to French, with the new Create and Train an Encoder/Decoder Transformer Model for Language Translation tutorial. For other great examples, including detecting gas leaks with object detection, or beating ATARI Pong, check out our Examples page.
Happy Deep Learning!
[1] Jaewoo (Kyle) Song GitHub: devjwsong/transformer-translator-pytorch, 2021, GitHub
[2] Attention Is All You Need by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, 2017, arXiv