

Temporal Fusion Transformers, as described in the Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting article by Lim et al. [1], use a complex mix of inputs to provide multi-horizon forecasting for timeseries data. The first step in understanding these models is to understand the data inputs fed into the model and the predicted outputs that it produces.
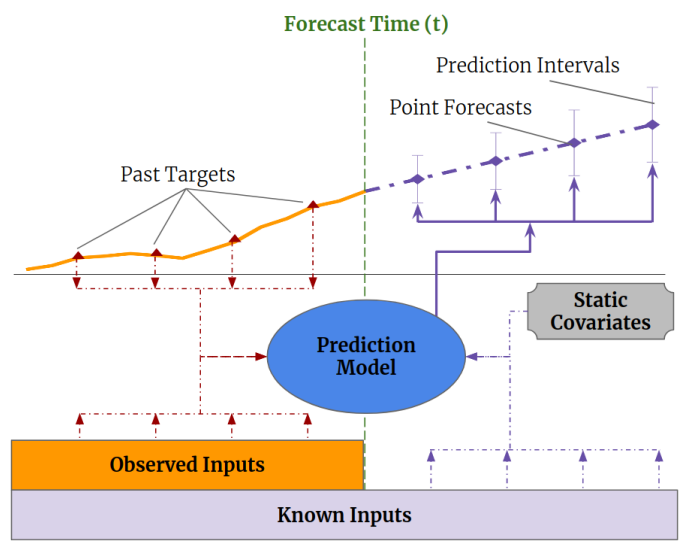
Time-series models train on a set of past targets that are mixed with observed inputs and known past and future inputs to produce the point forecasts at prediction intervals as shown above.
This post describes how the tft_torch [2] open-source project organizes data for its Temporal Fusion Transformer model training tutorial.
Input Data Files
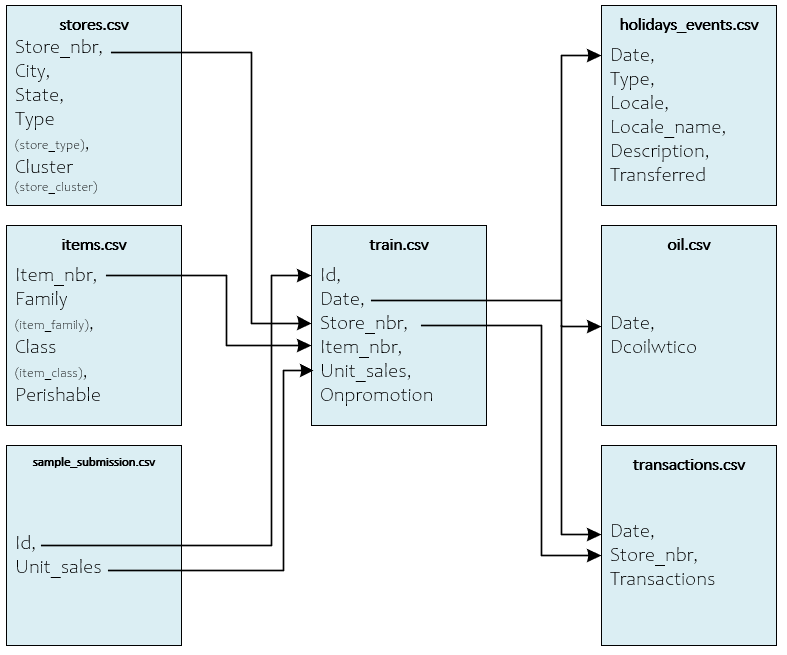
The Favorita Dataset, hosted on Kaggle, consists of 8 CSV files (7 shown below) that make up the Corporacion Favorita Grocery Sales Forecasting [3] data. An eighth test.csv file is also used for testing, but not shown for simplicity.
Once downloaded, the Favorita Dataset Creation Example [4] walks through the steps of processing the files to produce the final data.pickle file used in training and testing of the TFT model. The data.pickle file contains a total of 15,107,574 synchronized records that are allocated in the following manner:
Training 11,532,481 Validation 120,833 Testing 3,454,260
In total, the data.pickle file contains the following synchronized dataset sub-parts which are derived from the original CSV files previously discussed above.
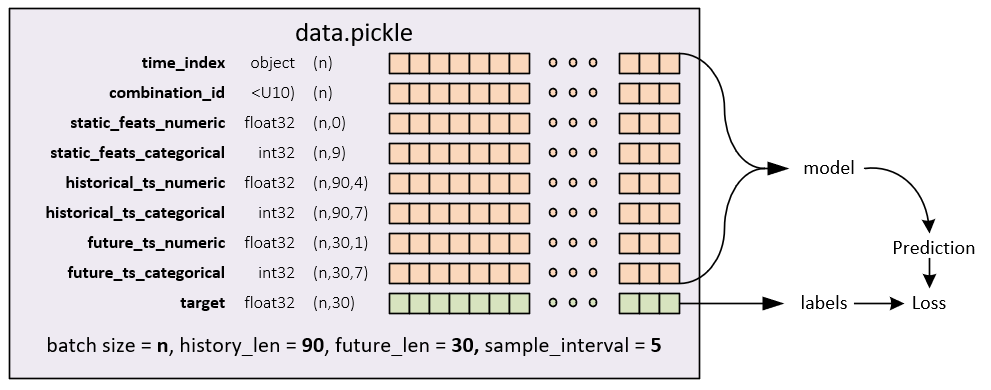
DataSet Sub-Parts
The dataset subparts are created in the following manner.
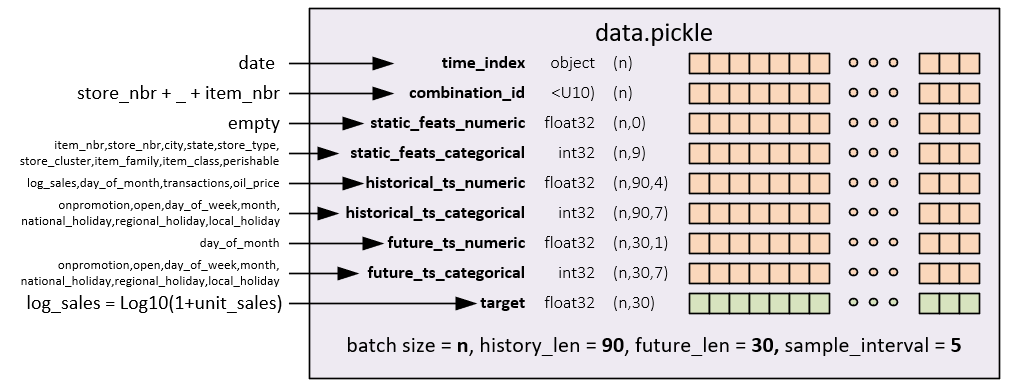
time_index
The time_index is created using the date field within the train.csv (or test.csv file).
combination_id
The combination_id is created by combining the store_nbr and item_nbr fields.
static_feats_numeric
The static_feats_numeric consists of the static, numerical features – for the current dataset there are no static_feats_numeric and for that reason this field has a shape (n,0).
static_feats_categorical
The static_feats_categorical consists of the following sub-fields: item_nbr, store_nbr, city, state, store_type, store_cluster, item_family, item_class and perishable.
historical_ts_numeric
The historical_ts_numeric consists of the following sub-fields: log_sales, day_of_month, transactions, and oil_price. Note, log_sales is created by calculating Log10(1 + unit_sales).
historical_ts_categorical
The historical_ts_categorical consists of the following sub-fields: onpromotion, open, day_of_week, month, national_holiday, regional_holiday, and local_holiday.
future_ts_numeric
The future_ts_numeric consists of the following sub-fields: day_of_month.
future_ts_categorical
The future_ts_categorical consists of the following sub-fields: onpromotion, open, day_of_week, month, national_holiday, regional_holiday, and local_holiday, which are the same as the historical_ts_categorical shown above.
target
The target field consists of the log_sales which is calculated with Log10(1 + unit_sales).
Model Output
The model outputs scaled log_sales predictions as shown below from the output in [5].
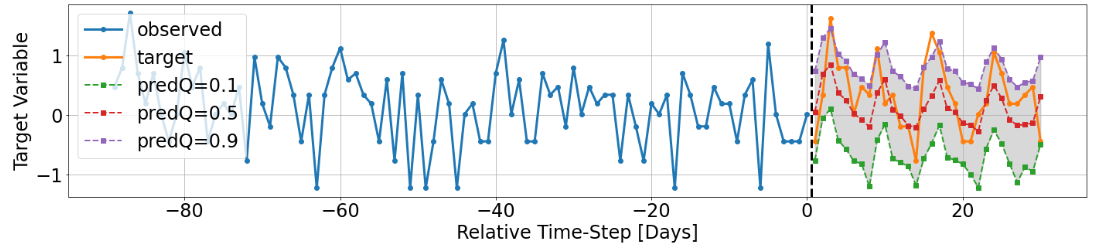
The log_sales can also be shown in an unscaled manner to produce actual unit_sales predictions.
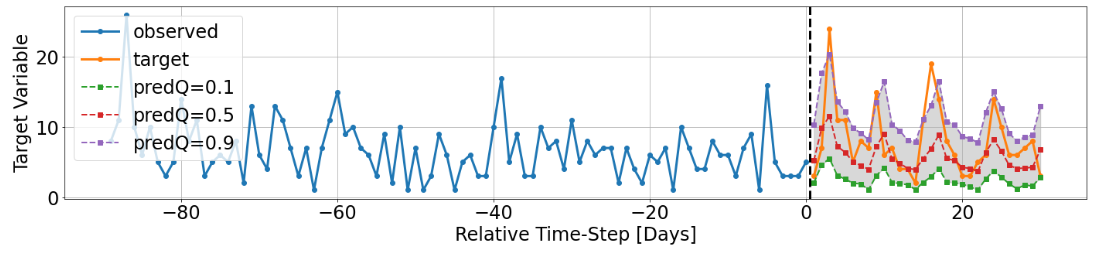
See [5] for more details on the Python code used to produce these graphics.
In our next article we dive deeper into how the Temporal Fusion Transformer models work to produce these predictions.
Happy Deep Learning!
[1]Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting by Bryan Lim, Sercan O. Arik, Nicolas Loeff and Tomas Pfister, 2019, arXiv:1912.09363
[2] GitHub: PlaytikaOSS/tft-torch by Dvir Ben Or (Playtika), 2021, GitHub
[3] Corporation Favorita Grocery Sales Forecasting by kaggle, 2018, kaggle
[4] Favorita Dataset Creation Example by Dvir Ben Or (Playtika), 2021, GitHub
[5] GitHub: PlaytikaOSS/tft-torch Training Example by Dvir Ben Or (Playtika), 2021, GitHub