

In this post we explore the impact of using different activations in the Closed-form Continuous-time (CfC) Liquid Neural Network as described by [1], [2] and [3].
Currently the CfC Unit Layer supports the following five different activations: RELU, SILU, GELU, TANH and LECUN. As shown below, each of these activations have different profiles.
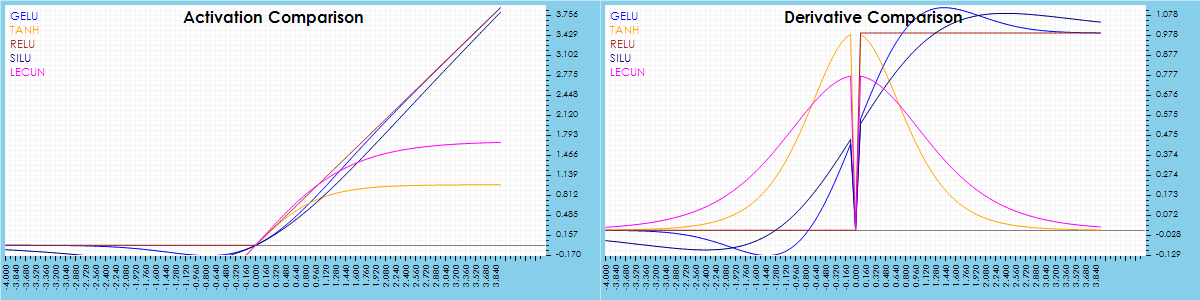
The visualization above separates the activations into two distinct profiles where the RELU, SILU and GELU continually rise and the TANH and LECUN roll off as the latter near and/or exceed 1.0. These profiles impact the speed and smoothness of the CfC servoing toward the target over time.
RELU Activation
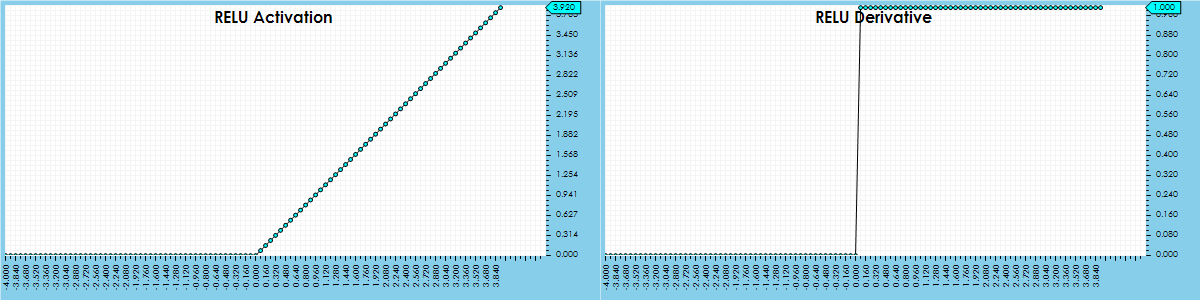
The standard RELU activation is fast and creates a smooth servoing that we will use as the basis for our comparison with other activations.
When using the RELU activation, a RELU Layer computes the Rectified Linear Unit calculations using the function:
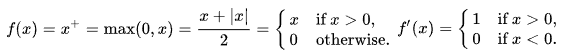
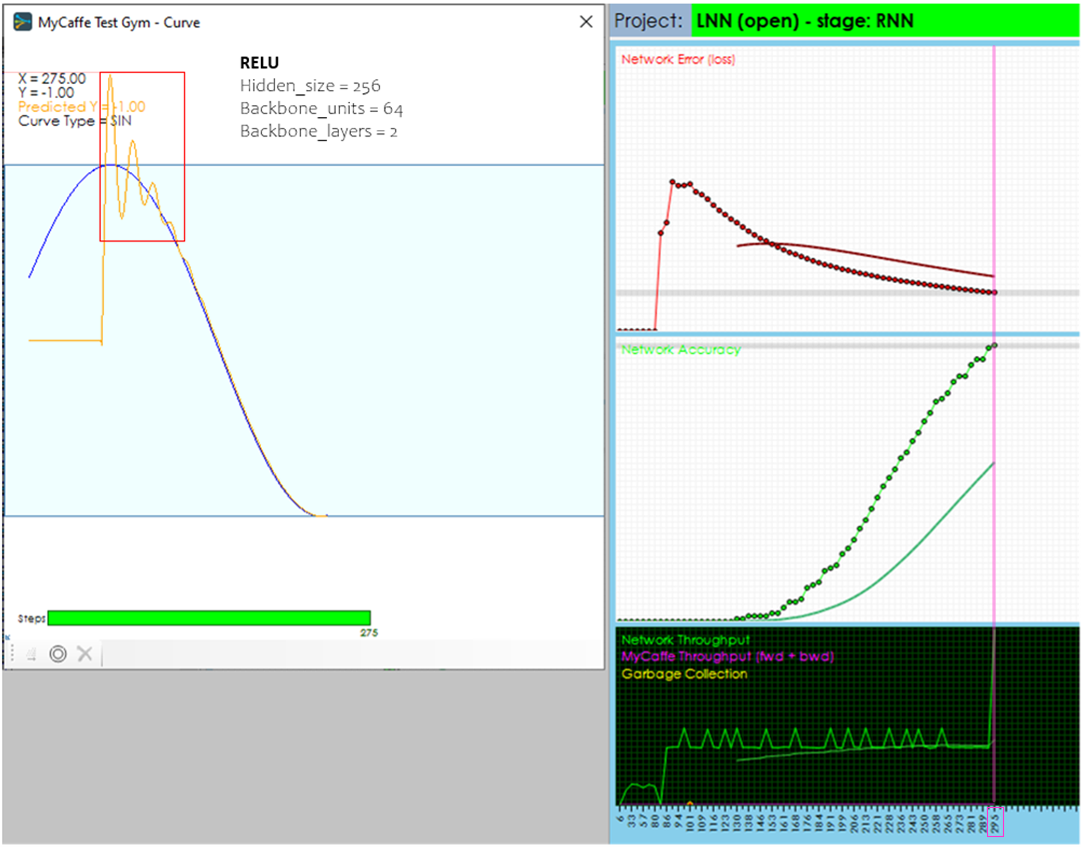
When using the standard RELU activation in the CfC Unit Layer, a smooth servoing toward the target occurs within around 147 steps and the accuracy (calculated as a 30-point rolling average of ‘closeness’ to target) reaches 99% at 295 training cycles (forward, backward and optimizer step). From that point on the model follows the curve very closely while the input data and time are in sync.
SILU Activation
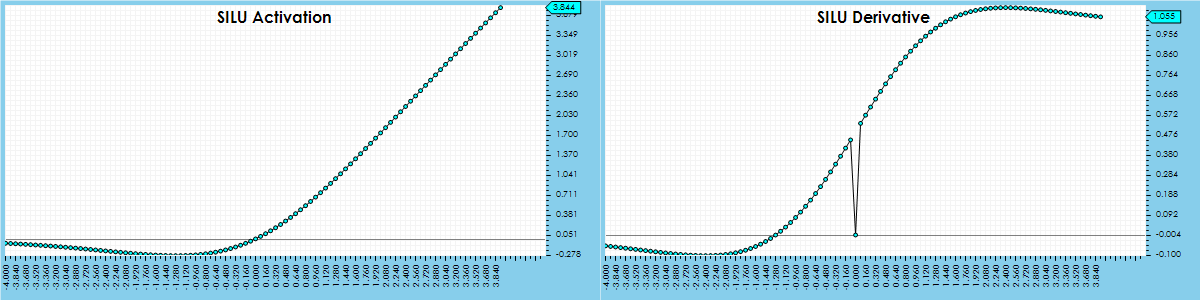
The SILU activation is a leaky version of the RELU where most of the focus is on the positive values yet some of the negative values are allowed to ‘leak’ into the calculation. The following function calculates the SILU activation:
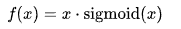
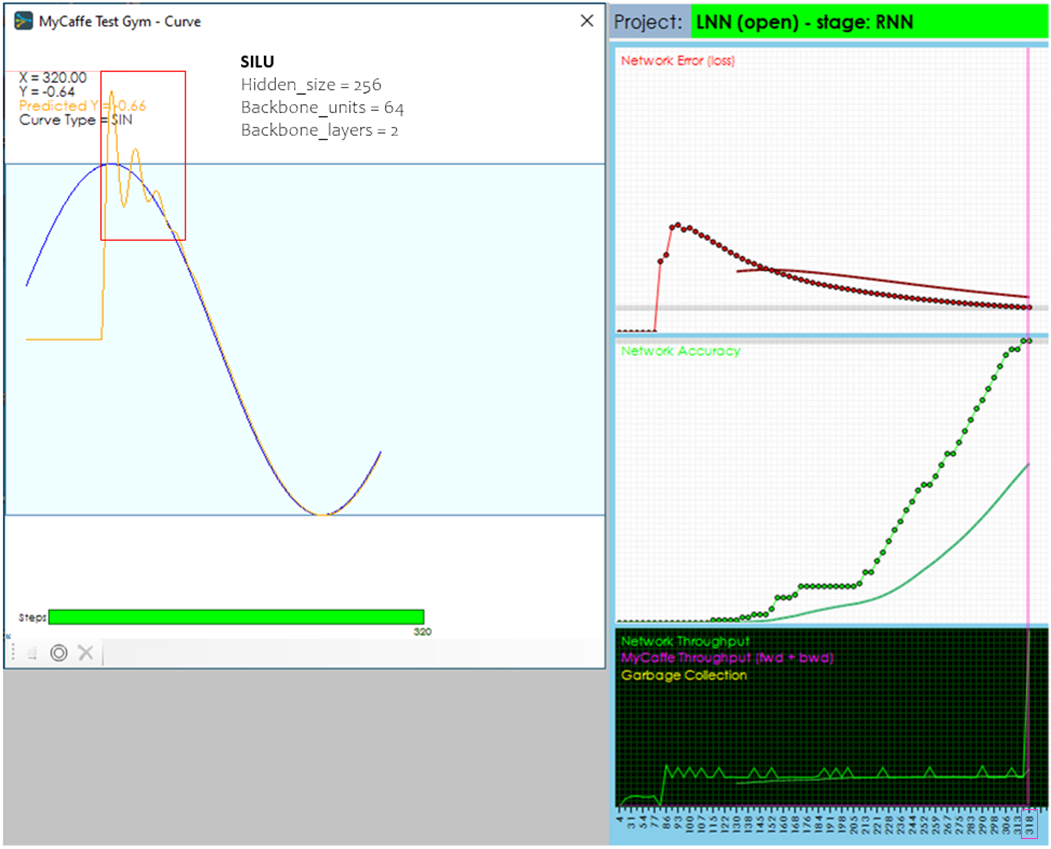
When using the SILU activation in the CfC Unit Layer, a similar smooth servoing curve to the RELU is observed that meets the target within the same 147 steps, yet the accuracy takes slightly longer to hit the 99% which is hit at 318 training cycles (23 more cycles than the RELU).
GELU Activation
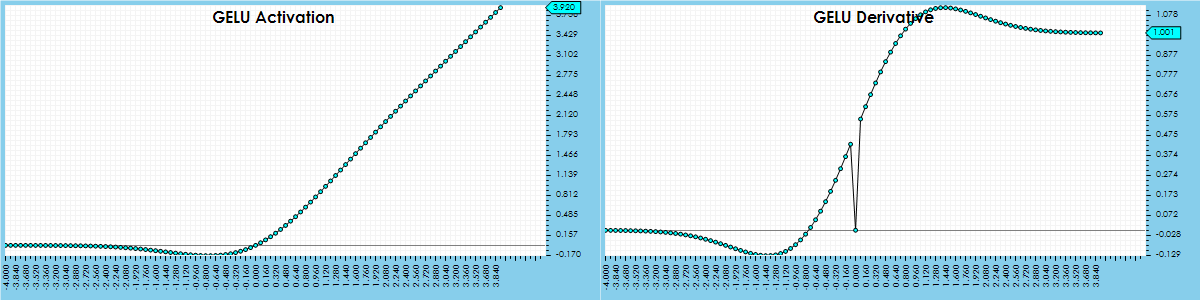
The GELU activation is another leaky variation of the RELU, yet the ‘leak’ is contained to negative values closer to zero than that of the SILU activation function. The following function calculates the GELU activation:
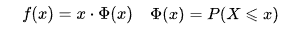
![]() term is the ‘cumulative distribution function of the standard normal distribution.’ [4]
term is the ‘cumulative distribution function of the standard normal distribution.’ [4]
Not surprisingly, when used in the CfC Unit Layer, the GELU also creates a smooth servoing to the target that looks very similar to the results from the RELU and SILU activation functions.
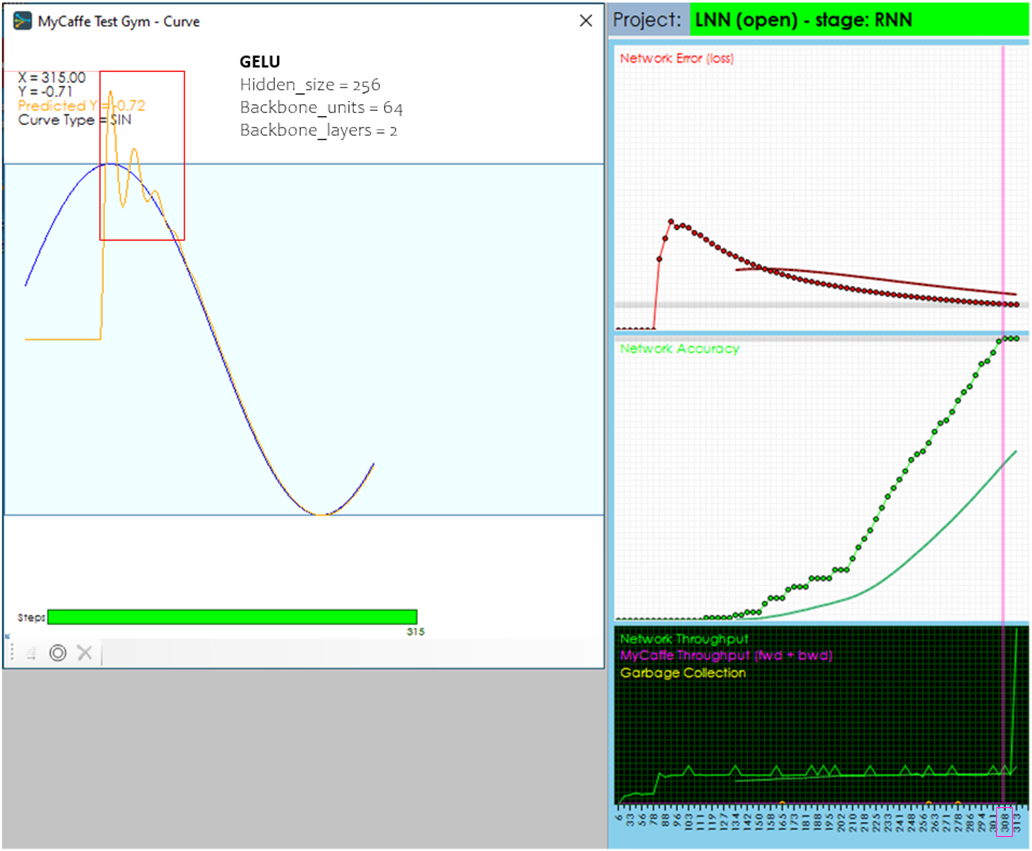
When using the GELU activation in the CfC Unit Layer, the predicted meets the target in around 147 steps like the RELU and SILU. However, the training accuracy hits 99% slightly faster than SILU yet slower than the RELU which may be attributed to the GELU’s activation profile having a ‘leak’ that falls in between that of the SILU and RELU. The GELU hits the 99% accuracy in around 308 training cycles.
TanH Activation
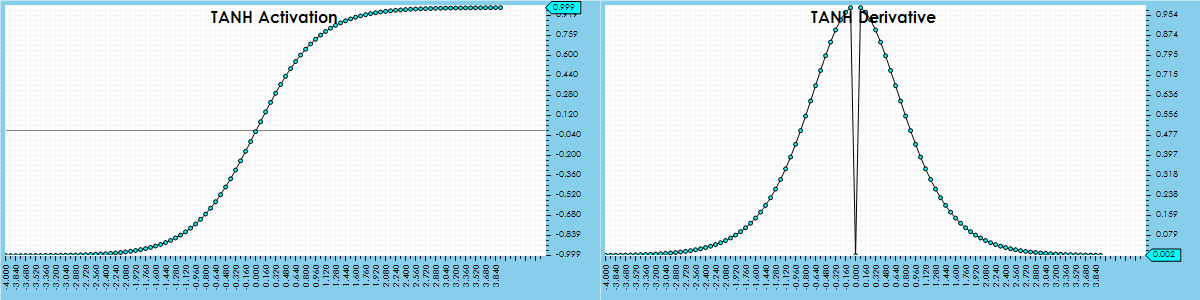
The TANH activation performs a hyperbolic tangent on the input to squeeze the values into a range between -1.0 and 1.0. The following is the activation function for the TANH activation:
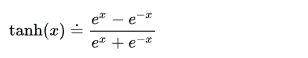
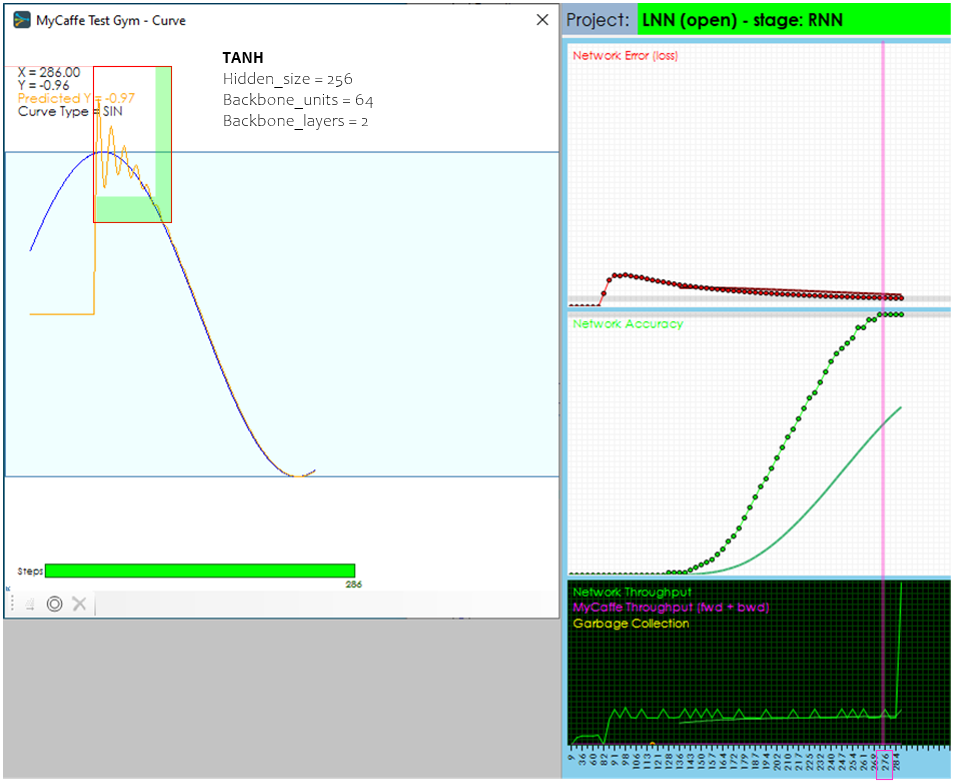
When using the TANH activation in the CfC Unit Layer, the predicted meets the target in around 135 steps – an 8% reduction in steps. Additionally, the accuracy hits 99% at around 276 training cycles which is a 6% reduction in steps from the RELU.
LECUN Activation
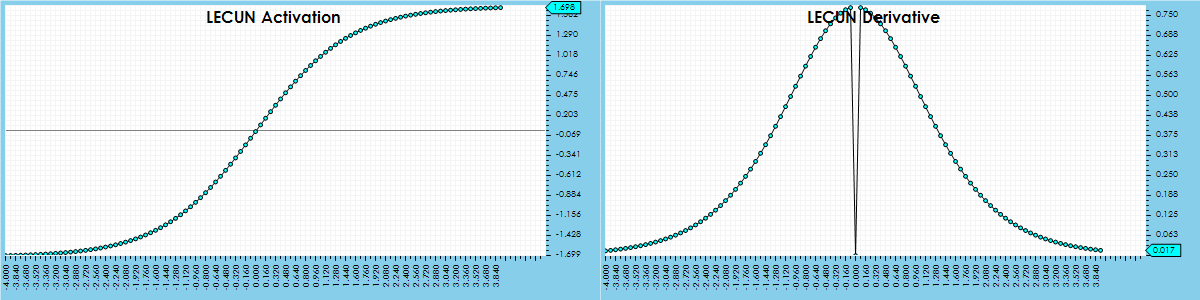
The LECUN activation has a similar profile to the TANH yet bounds the number to a larger range of around -1.7 and 1.7. The following is the activation function for the LECUN activation:

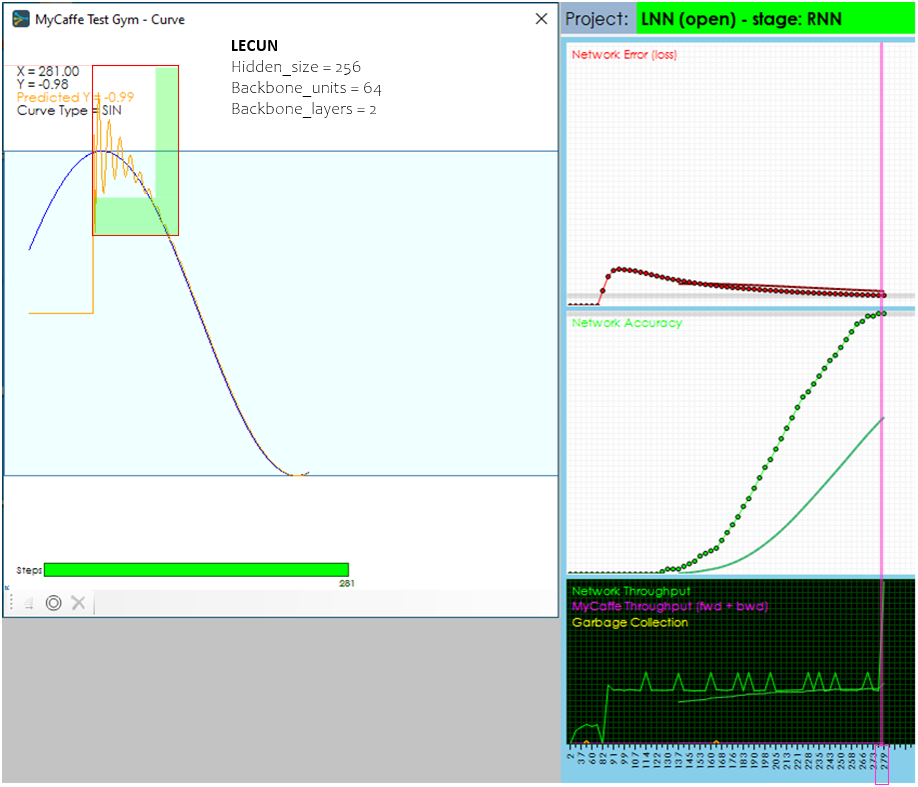
When using the LECUN activation in the CfC Unit Layer, the predicted meets the target in around 129 steps, however this activation appears to have more jitter and is not as smooth as the TANH. For that reason, the LECUN activation reaches 99% accuracy in 279 cycles, slightly more than the TANH activation.
Comparison Summary
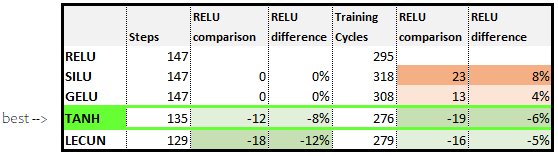
A summary of the impact each activation function has on the CfC’s ability to learn a simple Sine curve is shown in the table below.
Trying New Scenarios
To test a new scenario of your own, just open the model editor and change the properties of the CfC Layer in the Properties window of the SignalPop AI Designer.
Once the model is saved, re-open and train the model and watch the new results by double clicking on the Curve gym within the LNN project.
We hope this blog has given you a better perspective on how activation functions impact the CfC Liquid Neural Networks. To learn more about how the CfC Liquid Neural Network works, see our blog post on CfC. And to try other cool models, see our tutorials.
To dig into the source code for this post, see the TestTrainingRealTimeCombo function on the MyCaffe GituHub site.
Happy Deep Learning!
[1] Closed-form Continuous-time Neural Models, by Ramin Hasani, Mathias Lechner, Alexander Amini, Lucas Liebenwein, Aaron Ray, Max Tschaikowski, Gerald Teschl, Daniela Rus, 2021, arXiv:2106.13898
[2] Closed-form continuous-time neural networks, by Ramin Hasani, Mathias Lechner, Alexander Amini, Lucas Liebenwein, Aaron Ray, Max Tschaikowski, Gerald Teschl, Daniela Rus, 2022, nature machine intelligence
[3] GitHub: Closed-form Continuous-time Models, by Ramin Hasani, 2021, GitHub
[4] Rectifier (neural networks), Wikipedia
[5] Activation function, Wikipedia
[6] Lecun’s Tanh, Meta AI