

In our latest release, version 0.11.0.65, we have added support for the TripletNet used for one-shot and k-n shot learning as described in [1][2], and do so with the newly released CUDA 11.0.2 and cuDNN 8.0.2!
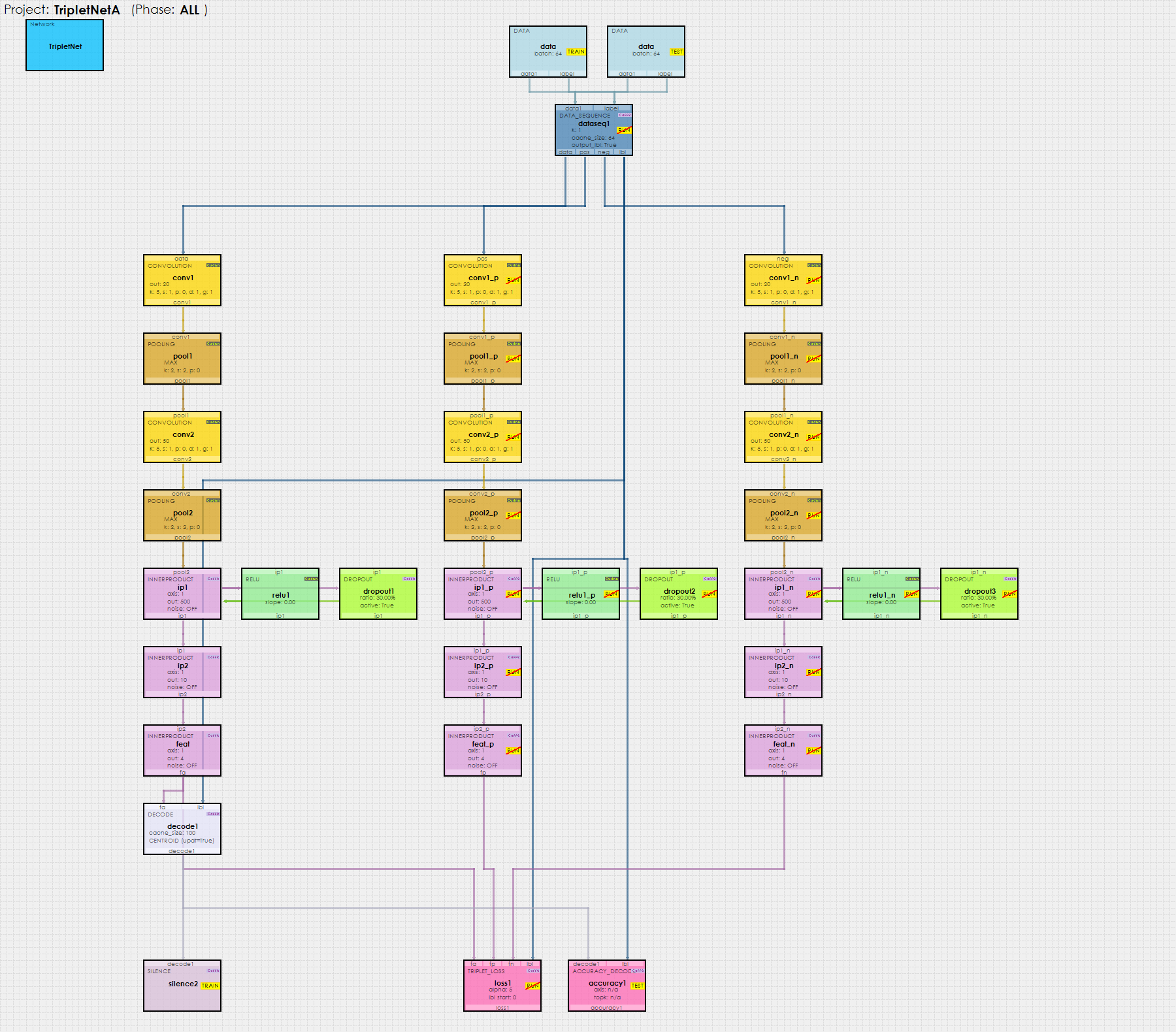
The TripletNet employs three parallel networks that each learn: an anchor image, a positive image that matches the label of the anchor, and a negative image that does not match the label of the anchor. A new Data Sequence Layer feeds the correct sequence of each of these three images into the three parallel networks (anchor, positive and negative).
At the bottom of the network the Triplet Loss Layer calculates the loss to move the positive images toward the anchor image and the negative images away from it. For details on the loss gradient calculation, see [3]. During the learning process, similar images tend to group together into clusters. To see this learned separation in action, first add a Debug Layer to the ip2 layer which learns the 4 item embedding of the anchor images.
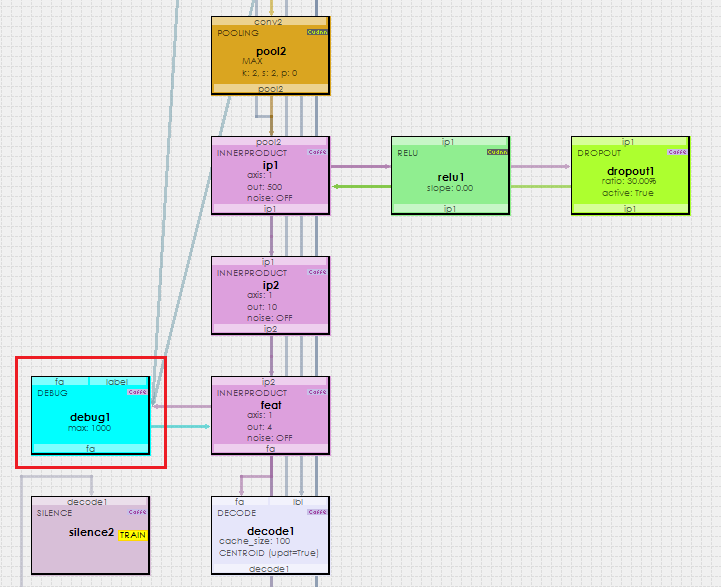
The Debug Layer caches up to 1000 of the most recently learned embeddings that are passed to it during each forward pass through the network.
Next, train the TripletNet for around 2,500 iterations where it should reach around 97% accuracy. At this point the Debug Layer will have a full cache of 1000 embeddings.
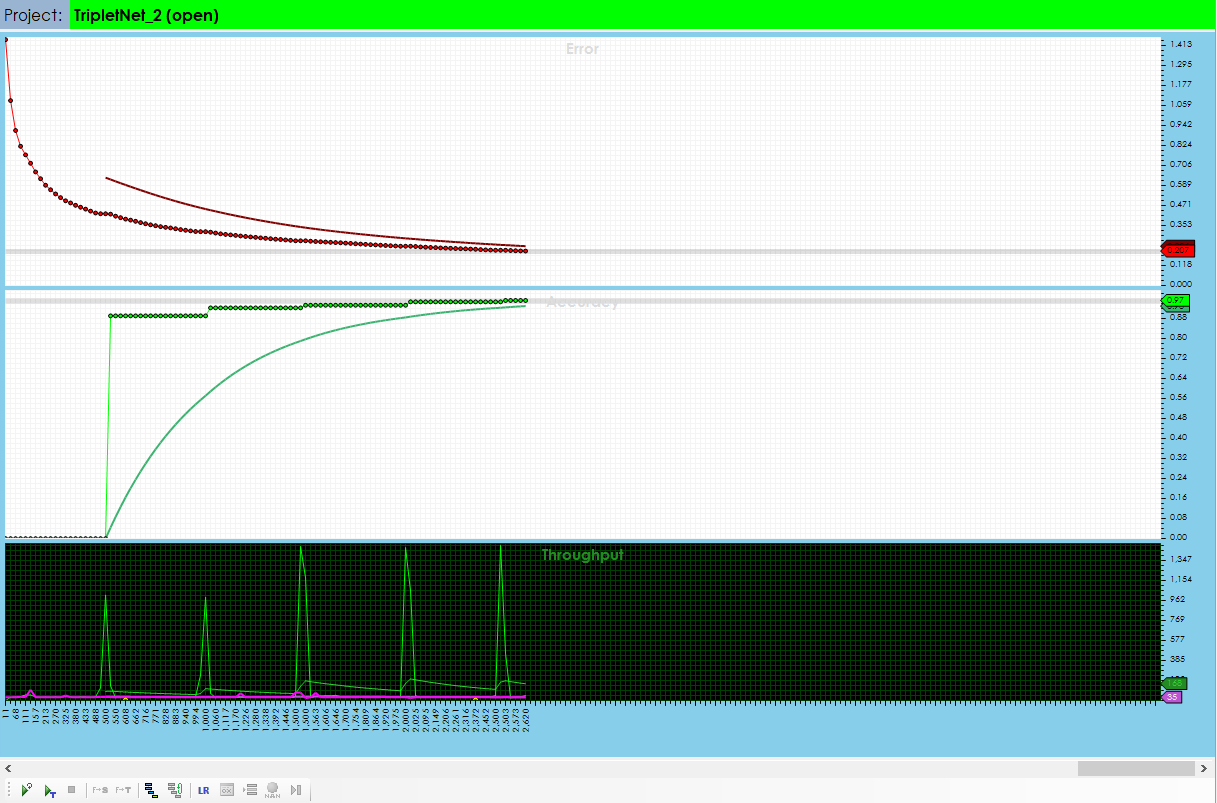
Once trained, right click on the Debug Layer and select ‘Inspect Layer‘ to run the TSNE algorithm on a subset of the stored embeddings. As shown below, the TSNE algorithm demonstrates a clear separation between each of the learned embeddings for each anchor image label.

TripletNets are very effective at learning a larger dataset, even when you only have a limited number of labeled data items. For example, the 60,000 training images of MNIST can be learned up to 80% accuracy with only 30 images of each of the 10 classes of hand written characters 0-9.
To demonstrate this, we first create a small sub-set of the MNIST dataset consisting of 30 images per label for both testing and training – a total of 600 images (1% of the MNIST 60,000 training images). And of the 600 images, only 300 images are used for training (0.5% of the original set) where the remaining 300 are used for testing.
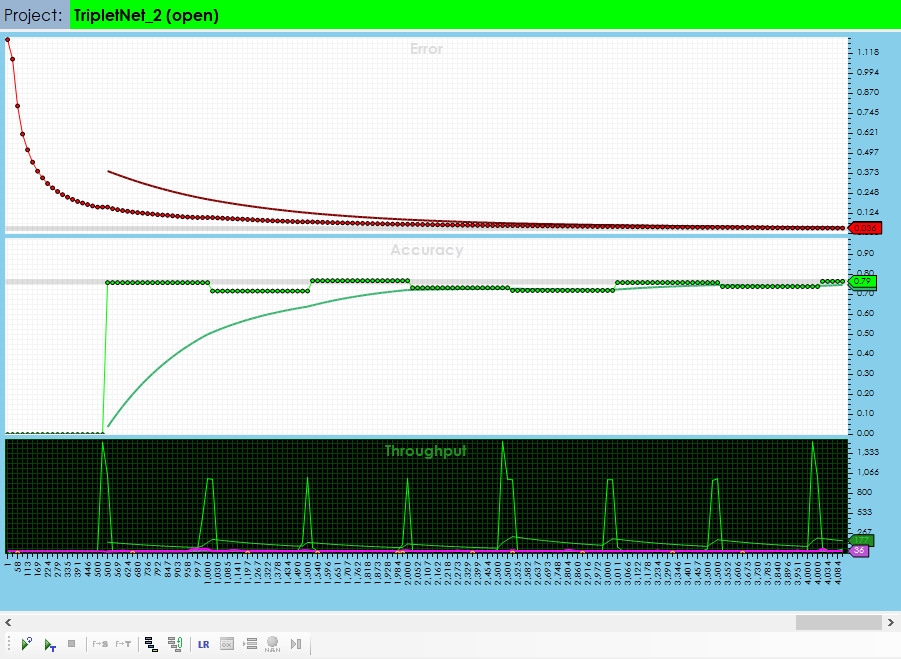
After training the model up to around 80% accuracy, we saved the weights and then replaced the 600 image dataset with the original, full 60,000/10,000 image MNIST dataset.
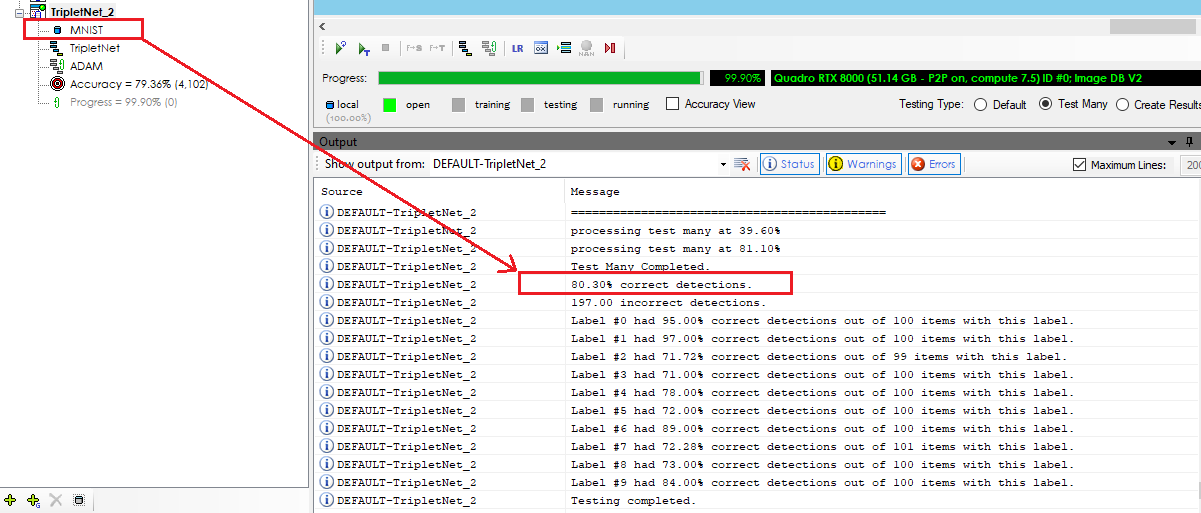
Next, we ran the ‘Test Many’ function on the original MNIST dataset, using the weights learned from the 600 image MNIST sub-set dataset and attained an accuracy of 80%, showing that the majority of the full MNIST dataset can be learned with a much smaller training dataset using the TripletNet model!
To try out the TripletNet for yourself, see the TripletNet tutorial which walks through the steps to train MNIST using only 1% of the original MNIST dataset.
New Features
The following new features have been added to this release.
- CUDA 11.0.2/cuDNN 8.0.2 support added.
- Added ONNX InceptionV1 model support to the Public Models dialog.
- Added ability to remove orphaned project files from the database.
- Added ability to change labels for each item within a dataset.
- Added new Data Sequence Layer support.
- Added new Triplet Loss Layer support.
- Added new Image Import dataset creator.
- Added new Auto Label to the COPY dataset creator.
Bug Fixes
The following bugs have been fixed in this release.
- Fixed bugs in Public Models dialog allowing hyperlink click during download.
- Fixed bugs caused when creating datasets.
- Fixed bugs in project import.
For other great examples, including beating ATARI Pong, check out our Examples page.
[1] E. Hoffer and N. Ailon, Deep metric learning using Triplet network, arXiv:1412:6622, 2018.
[2] A. Hermans, L. Beyer and B. Liebe, In Defense of the Triplet Loss for Person Re-Identification, arXiv:1703.07737v2, 2017.
[3] Shai, What’s the triplet loss back propagation gradient formula?, StackOverflow, 2015.